结合可视化分析目前Visual Question Answering(VQA)系统的主要问题
https://zhuanlan.zhihu.com/p/112022790
Awesome-Text-VQA

讨论范围:
数据集:VQA 2.0:https://visualqa.org/
模型:
可视化方法:
在原图上绘制了主要的bounding box(bbox),同时将attention的权重显示为这些bbox的颜色,红色越深权重越大。Bottom-Up-Top-Down模型由于只有一个attention,直接使用这个attention的权重;BAN模型包含了多层attention,我为了简化,直接将所有attention取了均值,而不是将每一步attention都单独显示出来。
错误样例定义:
因为VQA 2.0对每个问题其实包含了多个答案,所以问题答案的ground truth(GT)并非简单的one-hot vector,官方定义参考:https://visualqa.org/evaluation.html。
因此我们的错误样本定义也不是简单的非GT,而是满足两个条件
1)和分数最高的GT答案不同
2)prediction_prob * GT_acc_prob < 0.3
第二个条件的目的主要是,即便答案答对了,如果本身分数很低,即其实模型不是很确定,也算错误。
Step 1:量化分析:
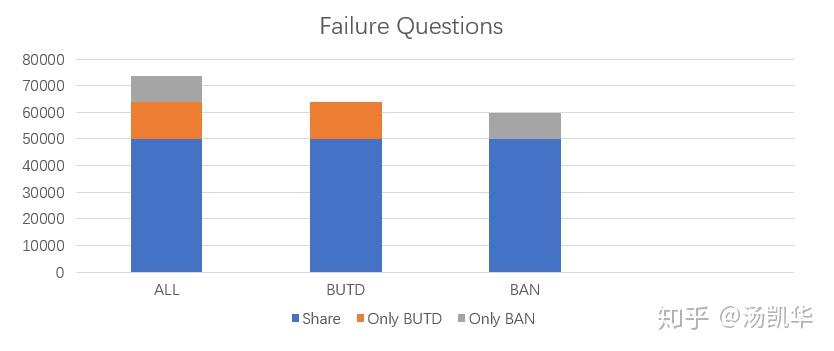
这里我们统计了所有答错的题目,ALL表示BUTD或BAN任何一个答错了。而颜色中,蓝色表示两个模型都答错的,BAN表示只有BAN答错的,橙色表示只有BUTD答错的。
Step 2:同一 图片&问题,两个模型可视化样例

我们发现引入了multi-attention的BAN可以关注到更多的物体,这也可能是为什么他比BUTD好的原因,这里的baseline其实就是BUTD。
Step 3:基于我观察的500+个错误样本,归纳的常见错误类型

我看了大概500+个两模型的错误样本,总结了六种目前VQA里的常见问题
- 第一个是由于标注员的问题,ground truth就标错了,或者标的文不对题。
- 歧义性,预测的答案是标准答案的另一种表达,或者是另一个回答问题的角度,总之其实没错。
- 超出图片本身知识,有些问题可能超出了图片本身的表述和信息,需要结合额外的生活常识来回答,或者问了图片外的物体的信息。
- 计数,这个问题也是VQA的常见问题,即目前的VQA无法数数。对的,即便是最简单的几个人也不会数,这里我推荐一篇paper,就这个问题做了详细的分析,也给了一个不错的模型:https://arxiv.org/abs/1802.05766
- 注意力机制的问题,1)关注到了错误的物体上,这通常是由于问题需要推理,但推理错了。2)物体的bounding box没有被检测出来,由于物体不显眼或者不常见。
- just wrong。什么都对了,连attention都对了,但就是答案错了。
目前的所有VQA的模型,大多只是在解决六个问题中的最后一个和部分的attention类罢了,通过更好的feature,更好的注意力/融合机制之类的。
Step 4:各类问题的比例(仅来自500+个我看的例子)
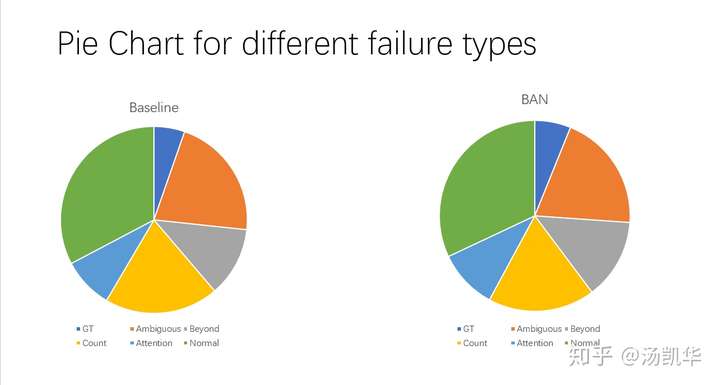
这里baseline就是BUTD模型。但这个比例仅来自我看的500+个例子。其中可以看出,确实是最后一类占了多数,这也就是为什么VQA的模型还能一直缓慢提升的原因。
Step 5:关于attention类的细分
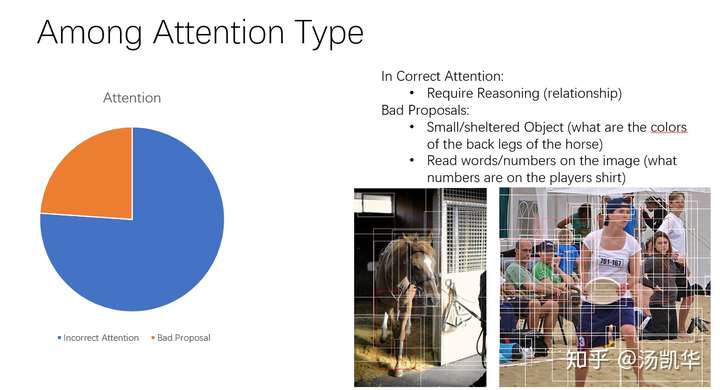
我还对了attention错误类做了细分。其中约3/4是由于attention错了,1/4是由于bbox proposal就没提出关键物体。
之所以这么做,是因为当时老板想让我就attention的问题来设计个提升VQA的模型,我想看下提升的upper bound,就做了个(劝退)分析。
Step 6:六类问题的典型例子
问题一:ground truth就是错的/模糊的 (1)什么车?(2)什么草?

问题二:问题表述的歧义。(1)所以这也算错?谁说AI要统治人类?(2)真·多说(一个字)多错 (3)词汇量大怪我咯 (4)GT啥意思?


问题三:超纲题(1)emmmm。。。(2)ban真牛逼直接说aisan,然而还是错(3)哈哈哈哈哈,承包我一天的笑点,不看也知道“妈妈”打扫的卫生 (4)有毒吧。。


问题四:计数题(1)出题人真恶趣味。。(2)bbox准不准都不知道,还怎么数

问题五:注意力(1)看哪呢(2)傻了吧(3)这谁看得见,等等小女孩为啥在男厕所。。(4)太难了。。


问题六:Just Wrong(1,2)BAN牛逼,(3,4)???真眼瞎?(没attribute的锅)


目前VQA系统的问题:

我觉得目前的主要问题是以下几点:
- 不会计数
- 无法区分答案相似的表达
- 无法理解歧义的问题,和问题的不同角度
- Attention中缺少推理能力
- 缺少不选择的能力,即便遇到上述说的超纲题类型,也会瞎attend一个/几个物体
- 特征:没有足够的attribute,比如上图最后一个问风扇朝向的问题,即便关注对了物体,但是学习的时候没有学习up/down的相关信息,也无法回答。
- 无法读数字/问题,这个问题已经有个新的task了:Text VQA:https://textvqa.org/