1.简介
Kafka是一个分布式消息系统,使用Scala语言进行编写,具有高水平扩展以及高吞吐量特性。
目前流行的消息队列主要有三种:ActiveMQ、RabbitMQ、Kafka

ActiveMQ、RabbitMQ均支持AMQP协议,Kafka使用仿AMQP协议,目前Flume、Storm、Spark、Elasticsearch都支持与Kafka进行集成。
动态扩容:在不需停止服务的前提下动态的增加或减少节点,Kafka的动态扩容是通过zookeeper实现的,zookeeper上保存着kafka的相关状态信息(topic、partition等)
2.关于AMQP
AMQP全称 高级消息队列协议,是一个统一消息服务的应用层协议,为面向消息的中间件所设计,基于此协议的客户端与消息中间件可相互传递消息,并不受客户端和中间件的产品以及开发语言不同所限制。

Producer负责把消息发送给Broker。
Broker负责接收并存储Producer发送的消息。
Consumer负责从Broker中消费消息。
*Broker是消息队列中最小的运行单元,一个Broker的运行就代表着一个Kafka实例。
3.Kafka的模型
1.Broker
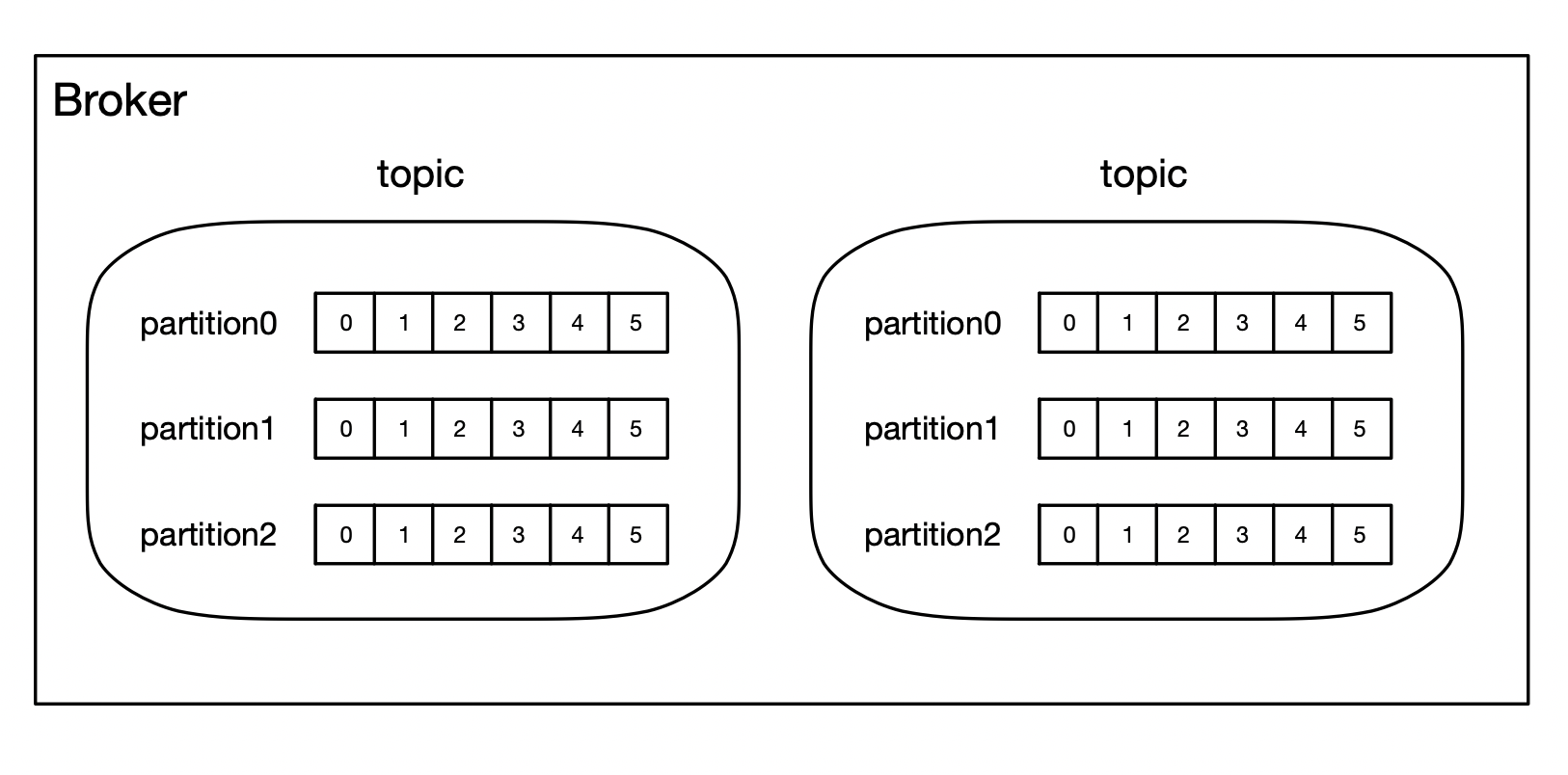
Broker中可以包含多个Topic,每个Topic下又包含多个Partition。
一个Topic(主题)类似于新闻中的体育、娱乐、等分类概念,在实际开发中通常一个业务对应一个Topic。
一个Topic下由多个Partition组成,每个Partition都是一个First In First Out的队列,用于存放Topic中的消息。
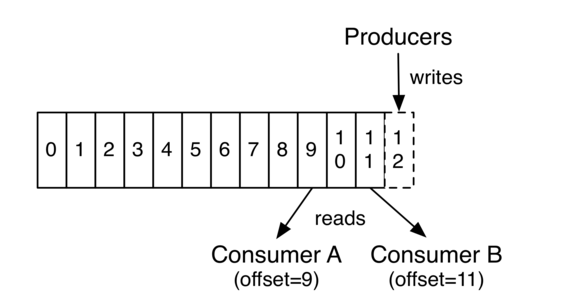
每个消息在Partition中都有一个offset(偏移量),是消息在分区中的唯一标识。
每个Consumer都需要维护一份自己的offset,用于记录当前消费的进度,然后保存到Kafka当中(Consumer可以以任意的位置开始进行读取,只需要设置offset即可)
在一个可配置的时间段内,Kafka集群将保留所有发送的消息,不管这些消息是否被被消费。
Kafka的分区是提高Kafka性能的关键手段,当Kafka集群的性能不高时,可以试着往topic中添加分区。
Kafka的分区备份
Topic下的每个Partition在Kafka集群中都有备份,在逻辑相关的一组Partition中,都有一个作为Leader,其余作为Follower,Leader和Follwer的选举都是随机的,当Follower接收到请求时首先会发送给Leader,由Leader负责消息的读和写并把消息同步给各个Follower,如果Leader所在的节点宕机,Follower中的一台则会自动成为Leader。
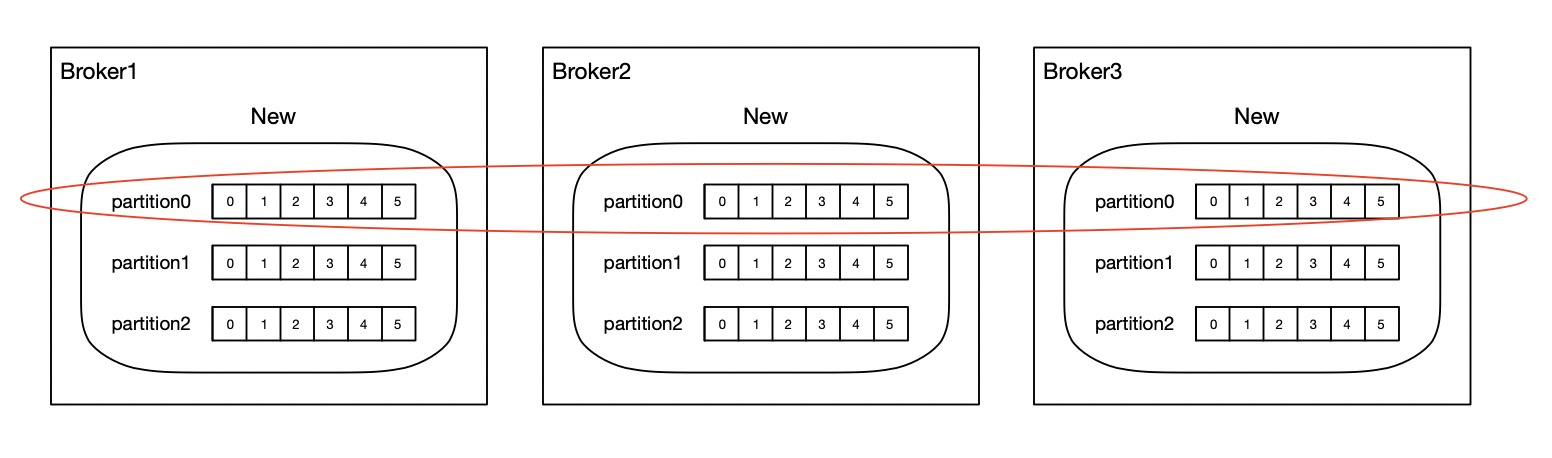
比如搭建一个Kafka集群,存在3个节点,同时设置Topic的分区数以及分区的备份数是3,现往Broker1中创建一个New Topic,那么在每个Broker实例中都会存在一个New Topic,同时每个New Topic下都会包含3个Partition,在逻辑相关的一组Partition中,都有一个作为Leader,其余作为Follower。
2.Producer
Producer向Broker中指定的Topic发送消息,消息将会根据负载均衡策略进入相应的Partition。
*Producer向Broker发送消息时,除了指定Topic以及Message以外,还可以指定一个Key,用于Partition的散列,Key相同的消息将会保存到同一个Partition当中。
3.Consumer组
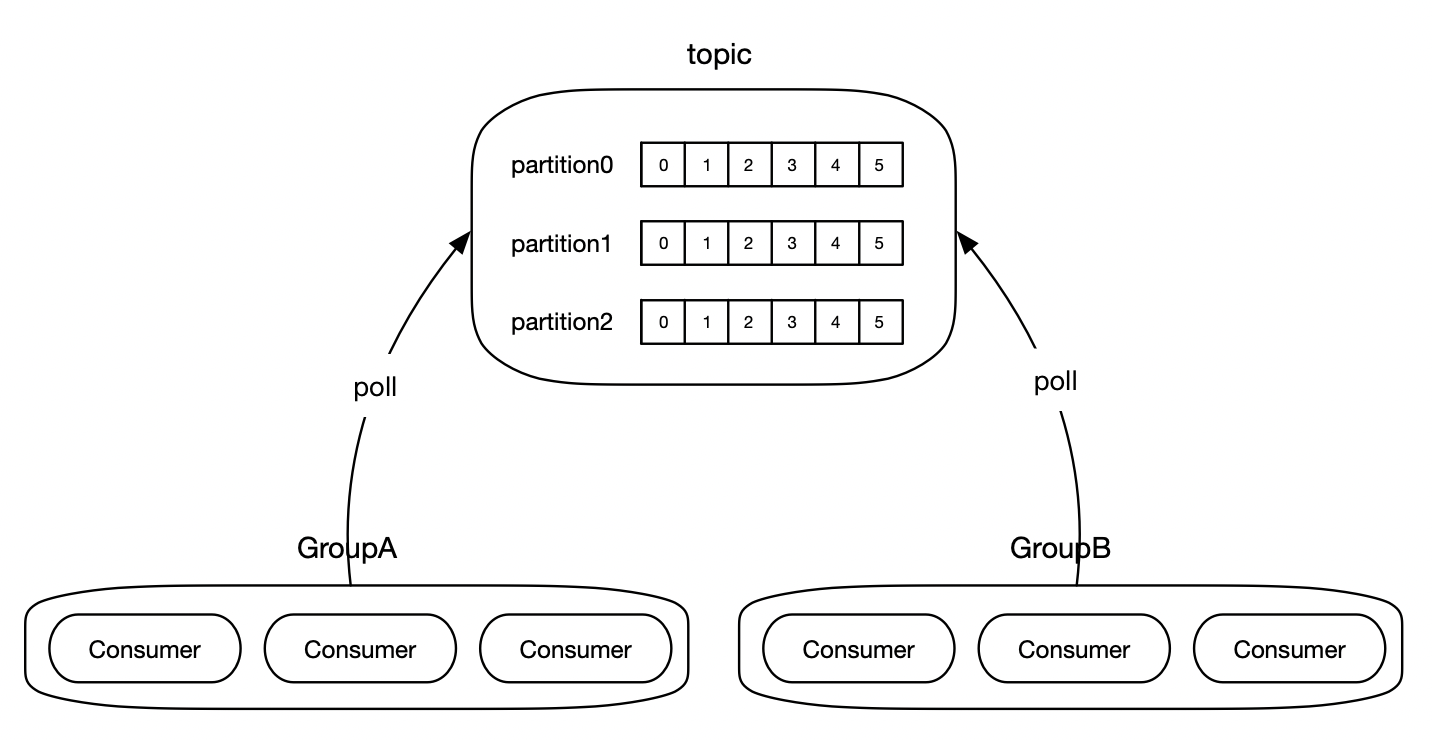
Kafka提供了Consumer组的概念,一个Consumer组下可以包含多个Consumer。
Kafka规定,Topic下的每一个Partition都只能被Consumer组下的唯一一个Consumer进行消费,以确保消费的顺序性,因此Consumer组下的Consumer数量不能超过Partition的数量,否则将会处于空闲状态。
队列模式
若所有的Consumer都在同一个Consumer组中下则成为队列模式,Topic中的各个Partition都只能被组中的唯一一个Consumer进行消费,组下的Consumer共同竞争Topic中的Partition。
广播模式
若所有的Consumer都不在同一个Consumer组中则成为广播模式,Topic中各个Partition的消息都会广播给所有的Consumer组。
4.Kafka的应用场景
1.解耦
比如存在一个应用A,它需要接收请求并且对请求进行处理,那么此时可以利用Kafka进行解耦,应用A只负责接收请求,同时将请求中的数据封装为Message,然后保存在Kafka的Topic当中,后续由应用B来进行消费,以达到解耦的目的。
2.削流
如果有大量并发的写请求直接去到数据库,那么将会导致数据库的奔溃(618/11.11),此时可以利用Kafka进行削流,将所有的写请求封装成Message,然后保存到Kafka的Topic当中,后续再通过Consumer以一定的速率进行消费(队列模式)
3.通知
首先各个被通知者都消费Kafka中指定的一个Topic,当需要进行通知时,往Kafka中指定的Topic发送消息,那么此时所有的被通知者就能够收到通知(广播模式)
5.关于Kafka中消息的顺序性
Kafka只能保证在同一个Partition中的消息是有序的,因为Kafka规定了Topic下的每个Partation都只能被Consumer组中的唯一一个Consumer进行消费,同时Kafka也没有实现在一个Consumer中使用多线程进行消费,Partition之间的消息是不能够保证有序的
Kafka是通过指定消息的Key来保证消息的顺序性的,因为Kafka会对Key进行散列,Key相同的消息将会保存在同一个Partation当中,因此当消息需要有序时可以通过指定相同的Key放入到同一个Partation当中。
如果需要在一个Consumer中使用多线程去消费Partation中的消息,那么需要自己实现,可以把Consumer拉取过来的消息全部提交到线程池中进行处理,那么消费的速度完全取决于线程池中线程的个数。
6.Kafka的使用
1.安装
由于Kafka使用scala语言编写,scale语言运行在JVM中,因此需要先安装JDK并且配置好环境变量。

由于Kafka中的状态信息都保存在zk上,虽然Kafka自带zk,但一般是使用外置的zk集群,因此需要先安装zk服务并且配置好zk集群关系。

从Kafka官网中下载安装包并进行解压。
![]()
2.配置文件
config目录是Kafka配置文件的存放目录
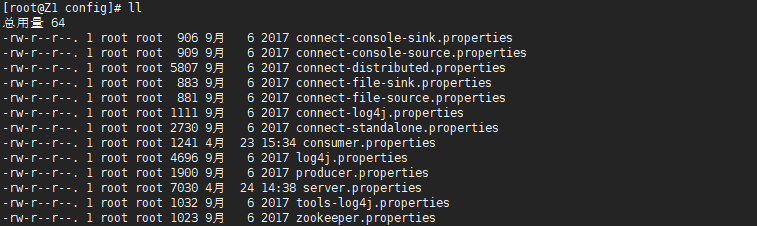
Broker端配置

Kafka在启动时需要连接ZK,共同连接同一个ZK集群的Kafka自动构成集群关系(broker.id在集群中不能重复)
Kafka中的消息是保存到磁盘的(log.dirs目录下),每个Topic下的Partition都对应log.dirs中的一个目录(topic-num),每个Partition目录下都有log文件用于存放消息,当Partition有新的消息时会往该log文件后进行追加。
如果创建的Topic其备份数大于1 ,那么在Kafka集群备份数个Broker中也会创建此Topic,因此在其log.dirs目录下也会存在该topic的目录。
Producer端配置

Consumer端配置

3.启动Kafka
1.启动zk集群
#启动zk节点
zkServer.sh start
#查看节点角色
zkServer.sh status
2.启动Kafka集群
./kafka-server-start.sh -daemon ../config/server.properties
3.创建Topic
1.创建名为chat的Topic,Topic的分区数以及备份数都为3。
./kafka-topic.sh --create --zookeeper 192.168.1.80:2181,192.168.1.80:2182,192.168.1.80:2183 --partitions 3 --replication-factor 3 --topic "chat"
创建Topic时需指定ZK服务地址,ZK中保存了Topic的分区数以及备份数(元数据),Kafka集群中的其他节点再从ZK服务中获取Topic的元数据来创建Topic。
2.查看各个broker中的log.dirs,可见在该目录下都生成了chat-0、chat-1、chat2分别表示chat Topic的第一个、第二个、第三个partation,每个partation中都有.log文件用于存放Partation中的消息。
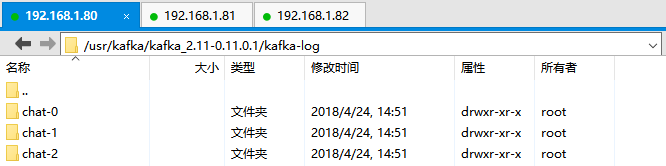
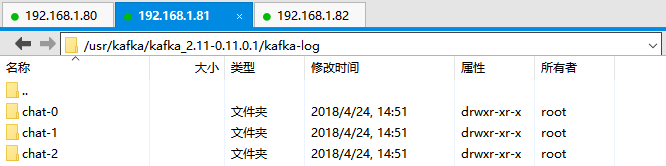
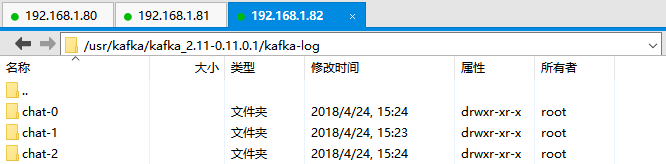
3.查看Kafka集群中chat Topic下各个Partation的状态
./kafka-topic.sh --describe --zookeeper 192.168.1.80:2181 --topic chat

Leader:充当Leader的Broker节点(broker.id)
Replicas:存在备份的Broker节点(broker.id,不管节点是否存活)
Isr:存在备份的同时存活的Broker节点。
4.Producer发送消息
往Kafka集群中的chat主题发送消息
./kafka-console-producer.sh --broker-list 192.168.1.80:9092,192.168.1.81:9092,192.168.1.82:9092 --topic chat
如果不指定Key,那么消息将会根据负载均衡策略进入相应的Partation。

5.Consumer消费消息
启动Consumer
./kafka-console-consumer.sh --bootstrap-server 192.168.1.80:9092,192.168.1.81:9092,192.168.1.82:9092 --topic chat --from-beginning
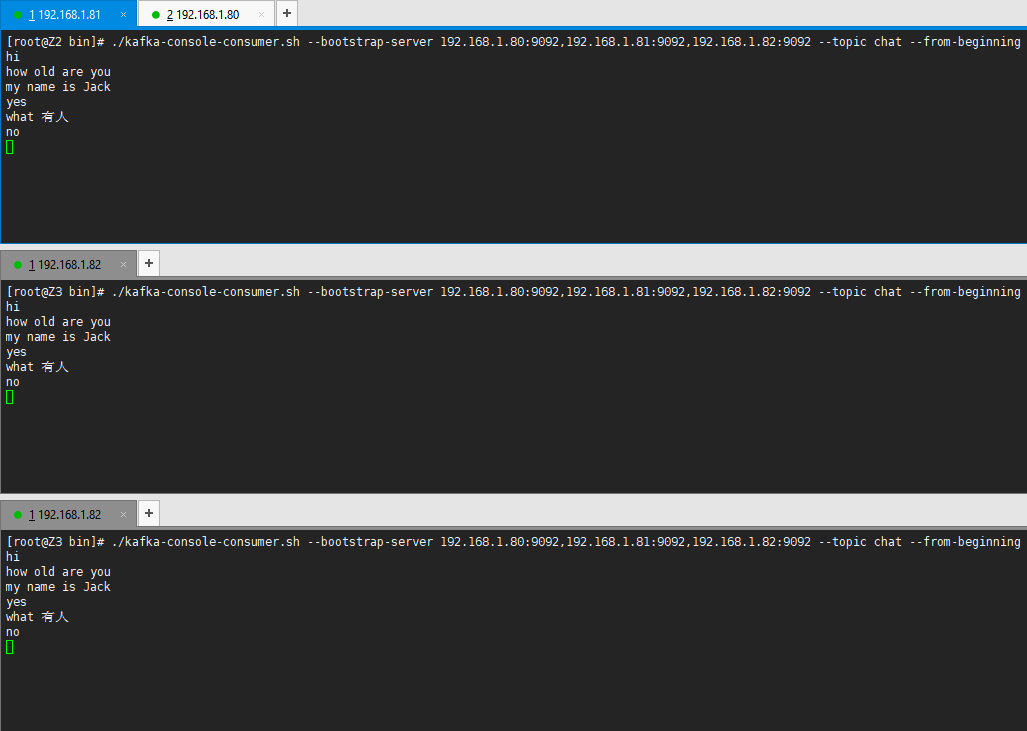
由于使用脚本文件启动Consumer并没有指定使用的配置文件,所以三个Consumer都不在同一个Consumer组中,因此三个Consumer都能够消费chat主题下各个Partation中的消息。
启动Consumer并指定配置文件
./kafka-console-consumer.sh --bootstrap-server 192.168.1.80:9092,192.168.1.81:9092,192.168.1.82:9092 --topic chat --from-beginning --consumer.config ../config/consumer.properties
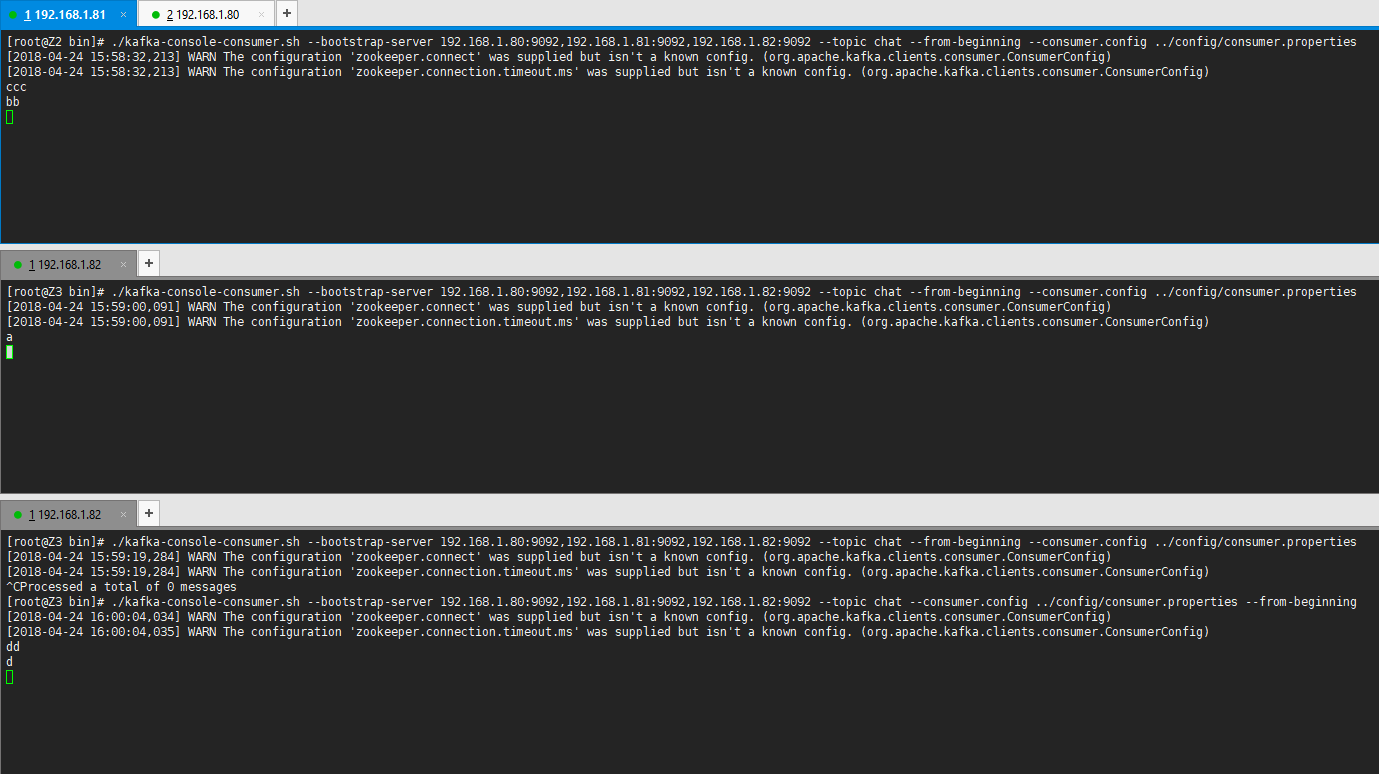
启动了3个Consumer并指定使用的配置文件,默认的group.id为test-consumer-group,因此这3个Consumer都在同一个Consumer组下,Topic中各个Partation仅能被组下的唯一一个Consumer进行消费。
在启动第一个Consumer时,Consumer组下只有一个Consumer,因此消息都会被此Consumer进行消费,当往Consumer组中添加新的Consumer时,将会重新分配拥有Partation的权利。
7.JAVA中使用Kafka
1.导入依赖
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.12</artifactId> <version>0.11.0.1</version> </dependency>
2.创建Topic
ZkUtils zkUtils = ZkUtils.apply("192.168.1.80:2181,192.168.1.81:2181,192.168.1.82:2181", 30000, 30000, JaasUtils.isZkSecurityEnabled());
// 创建一个名为chat的主题其包含2个分区,备份数是3
AdminUtils.createTopic(zkUtils, "chat", 2, 3, new Properties(), RackAwareMode.Enforced$.MODULE$);
zkUtils.close();
3.Producer发送消息
//创建Properties对象用于封装配置项 Properties props = new Properties(); props.put("bootstrap.servers", "192.168.1.80:9092,192.168.1.81:9092,192.168.1.82:9092"); props.put("acks", "all"); props.put("retries", 0); props.put("batch.size", 16384); props.put("linger.ms", 1); props.put("buffer.memory", 33554432); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); Producer<String, String> producer = new KafkaProducer<>(props); //创建消息实体ProducerRecord,并指定消息上传的topic、消息的Key、消息的Value ProducerRecord<String,String> record = new ProducerRecord<String,String>("topic","key","value"); //发送消息 producer.send(record); //关闭连接 producer.close();
KafkaProducer是线程安全的,在线程之间可以共享单个生产者实例。
send()方法是异步的,一旦消息被保存在待发送缓冲区时此方法就立即返回,其返回Future<RecordMetadata>实例,当调用该实例的get()方法时将会阻塞直到服务器对请求进行应答(阻塞时长跟acks配置项有关),当服务器处理异常时将抛出异常。
消息由Key和Value组成,Key相同的Message将会保存在同一个Partation当中(根据Key进行散列)
4.Consumer消费消息
//创建Properties对象用于封装配置项 Properties props = new Properties(); props.put("bootstrap.servers", "192.168.1.80:9092,192.168.1.81:9092,192.168.1.82:9092"); props.put("group.id", "consumerA"); //自动提交Consumer的偏移量给Kafka服务 props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("auto.offset.reset", "earliest"); props.put("session.timeout.ms", "30000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); Consumer<String, String> consumer = new KafkaConsumer<>(props); //订阅主题,一个消费者实例可以订阅多个主题 consumer.subscribe(Arrays.asList("chat", "hello")); //接收数据,消息存放在ConsumerRecords消息集合中 ConsumerRecords<String, String> records = consumer.poll(1000*5); //遍历消费端消息集合获取ConsumerRecord消费端消息实体,一个消费端消息实体包含偏移量、消息Key值、消息Value值 for (ConsumerRecord<String, String> record : records){ System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value()); }
poll(long blockTime)方法用于接收topic中的消息,当没有消息时将会等待blockTime的时间 (单位:毫秒),执行结果需结合auto.offset.reset配置项。
使用commitSync()方法可以手动同步消费者的偏移量给Kafka 。
使用seek(TopicPartition , long)方法手动设置消费者的偏移量。
8.Spring Kafka
1.导入依赖
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>0.10.2.0</version> </dependency> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> <version>1.2.0.RELEASE</version> </dependency>
2.创建Kafka Producer配置类
@Configuration @EnableKafka public class KafkaProducerConfiguration { /** * Producer配置 */ private Map<String, Object> senderProps() { Map<String, Object> props = new HashMap<>(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); props.put(ProducerConfig.RETRIES_CONFIG, 1); props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384); props.put(ProducerConfig.LINGER_MS_CONFIG, 1); props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 1024000); props.put(ProducerConfig.ACKS_CONFIG, "1"); props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); return props; } /** * Producer工厂 */ @Bean public ProducerFactory<String, String> producerFactory() { return new DefaultKafkaProducerFactory<>(senderProps()); } /** * KafkaTemplate */ @Bean public KafkaTemplate<String, String> kafkaTemplate() { return new KafkaTemplate<>(producerFactory()); } }
3.创建Kafka Consumer配置类
@Configuration @EnableKafka public class KafkaConsumerConfiguration { /** * Consumer配置 */ private Map<String, Object> consumerProps() { Map<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); props.put(ConsumerConfig.GROUP_ID_CONFIG, "GroupA"); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true); props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "100"); props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "15000"); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); return props; } /** * Consumer工厂 */ @Bean public ConsumerFactory<String, String> consumerFactory() { return new DefaultKafkaConsumerFactory<>(consumerProps()); } /** * Kafka监听器 */ @Bean public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() { ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); return factory; } }
4.Producer发送消息
@Component public class Producer { @Autowired private KafkaTemplate<String,String> kafkaTemplate; public void send() throws Exception { kafkaTemplate.send("topic", "key","value"); } }
5.Consumer消费消息
@Component public class Consumer { @KafkaListener(groupId="GroupA",topics = "topic",concurrency="3") public void consumer(String value) { System.out.println(String.format("消费消息,value:%s", value)); } }
@KafkaListener注解中的concurrency数量为开启的Consumer数量,也就是在Consumer组下存在多少个Consumer。
9.使用Kafka要解决的问题
1.Consumer端消息丢失
当Consumer消费消息后,自动提交了offset,如果后续程序处理出错,那么消息将会丢失,此时可以通过手动提交offset的方式进行解决。
2.重复消费
当Consumer读取消息后,程序也成功进行处理,如果手动提交offset时出错,则会导致重复消费,同时如果Producer重复发送消息也会导致重复消费,当发生重复消费时只需要保证幂等性即可(多次执行的结果保持一致)
如何保证幂等性
1.每次保存时,都先从数据库查一次,如果数据已存在则表示重复消费(针对并发不大同时实时性不高的场景)
2.数据库表添加唯一约束,当重复消费时将会插入失败(针对没有分库分表的场景)
3.添加消息表并在字段上加上唯一约束,每当消费完一条消息就往表里插入一条记录,当重复消息时将会插入失败(针对有分库分表的场景)
4.每次保存时,都先从Redis中查一次,如果Redis中已存在则表示重复消费(不太靠谱,除非过期时间设置很久)
*如果并发很高,需要借助Redis或者Zookeeper通过分布式锁来进行控制(比如Producer发送了2条相同的消息,如果没有指定Key,假设这两条消息分别坐落在不同的Partation当中,然后刚好被两个Consumer线程同时消费,此时就存在同步问题,需要通过分布式锁来进行控制)
3.Broker端消息丢失
当Partition中的Leader重选举时,也就是说Leader挂了,那么有可能导致消息未来得及同步给其他的Follower,最终导致消息丢失,此时只需要在Producer中设置acks等于all,那么Producer必须等待Leader将消息同步给所有的Follower后再进行返回。
4.消息堆积
消息堆积主要是因为Consumer消费的速度太慢了,可以通过为Topic新增Partation同时新增Consumer来进行消费从而提高消费的速度,或者将Consumer拉取的数据放入到线程池中进行处理,那么消费的速度就取决于线程池中线程的数量(要注意内存溢出),但是就不能通过Kafka监控工具中来判断是否存在消息堆积的现象了
5.消费失败
当消费失败时,可以将消息放入到一个队列当中,比如使用Redis的list结构,后续专门有一个线程来处理消费失败的消息(定时任务)