引言
中心内有大量的项目经过多年的迭代建设,无论是从体量、功能、复杂度都达到了一个无法完全依赖人工验证交付的点。
我们和很多质量团队一样,随着公司业务迅速的增长,前期质量环节主要依赖人工把控,在质量自动化工程建设上没太多积累,面对如今的业务交付无论是从效率、质量上都逐渐暴露出明显的短板。
开发及运维团队已在CI/CD上进行了提效建设,木桶效应逐渐明显,质量团队也希望尽快突破自己的交付瓶颈,并能逐渐建立自己的技术专业线,于是我们分析了目前比较集中的痛点,识别出2个关键词:回归提效、质量门禁。
回归提效怎么做
由于系统的体量较大,面对每次交付的需求,我们一方面希望精准分析出本次需求的影响范围,另一方面受限于交付周期及存在的变更风险压缩测试工期。

要本质上解决这两点,势必全量回归是保障质量最有效手段,集中验证本次交付需求是确保顺利交付的唯一途径。
一个维护多年的产品,很难有人能够针对每次改动分析全面涉及到的功能及业务场景,测试人员很希望能够释放资源将工作重点移至新功能验证。
那么接下来思路逐渐清晰了,为回归测试提效,减少人工参与。我们深入分析了目前团队现状及行业常规的自动化回归做法:UI层、API层。
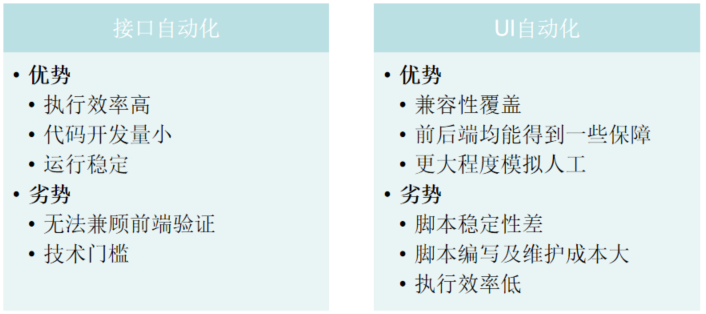
接口测试路线成为我们首选,基于这个思路,我进一步走向平台化。
平台化势在必行
要完成接口自动化建设,我们是使用现成的工具:Jmeter、Robot Framework,还是基于开源框架搭建工程,还是平台化。基于三个方面考虑:
1、已完成相关技术人才储备
2、开发&运维团队已先行建设DevOps
3、质量工程化,工程效率化,构建TestOps
我们决定搭建属于福禄自己的质量平台,以接口自动化为“基建”.
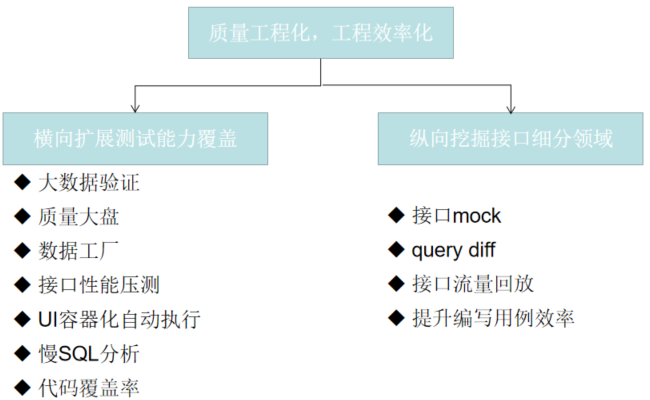
平台化后,我们可以充分利用现有的开发平台,进一步完成从上至下的流程对接。
全员平台建设
一旦平台化后,有效的降低接口自动化用例编写的技术门槛,深入了与现有的发布流程“兼容”,测试过程数据的持续沉淀为今后质量度量化提供基础。
团队内部我们进行了人员分工,长期参与项目交付的同学承担起“产品经理”,有技术长处的同学承担起“全栈工程师”,善于沟通协调的同学承担起“项目经理,迅速的确定了功能流程。
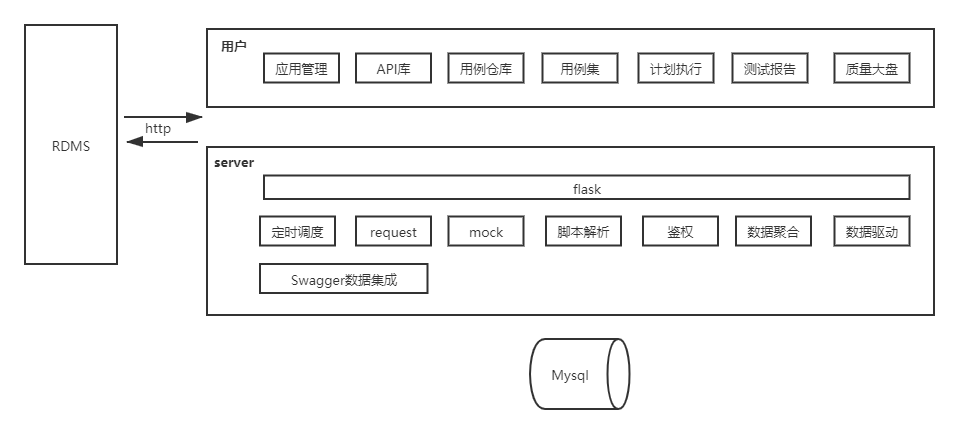
考虑今后更便捷的与中心内部其他系统“打通”,我们基于福禄现有的前端框架进行打磨,后端选择开发效率更高的python。
前端技术栈:antd(react) + apache echarts
后端技术栈:python + flask + blueprint
数据持久化:MySQL
平台功能介绍
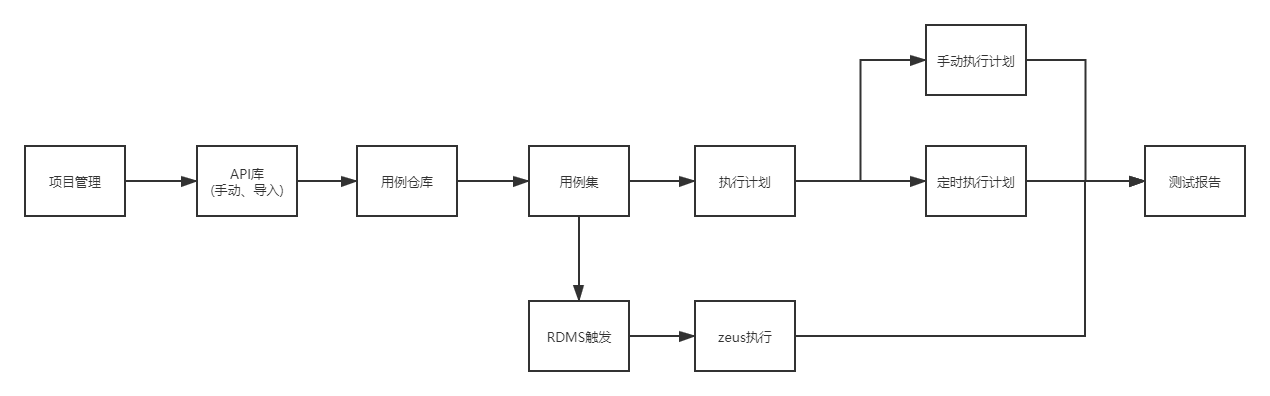
截止到目前,平台基本已完成:
项目环境信息->API搜集->用例编写->测试集创建->用例执行->测试报告
确保项目信息上下一致性
确保我们测试项目、应用、环境、api swagger信息从上至下是一致的,统一了数据源。
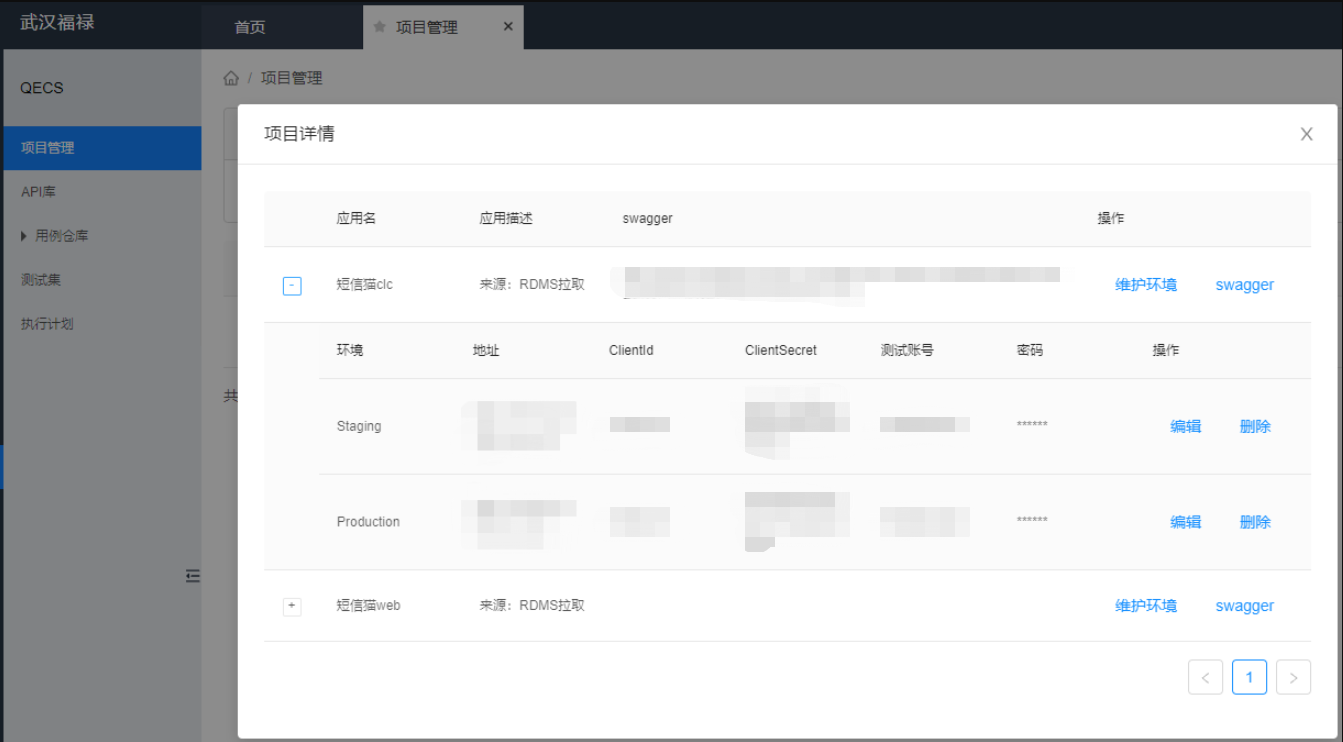
很多公司在接口测试都面临一个问题,到底我们接口覆盖做到什么程度,有没覆盖全,我怎么知道?
为了解决这一痛点,平台基于所有项目的api swagger进行解析,将api完整信息落库至平台,基于落库的api进行用例编写,避免了测试人员需要人工收集、手动填写、无法预知API量级......
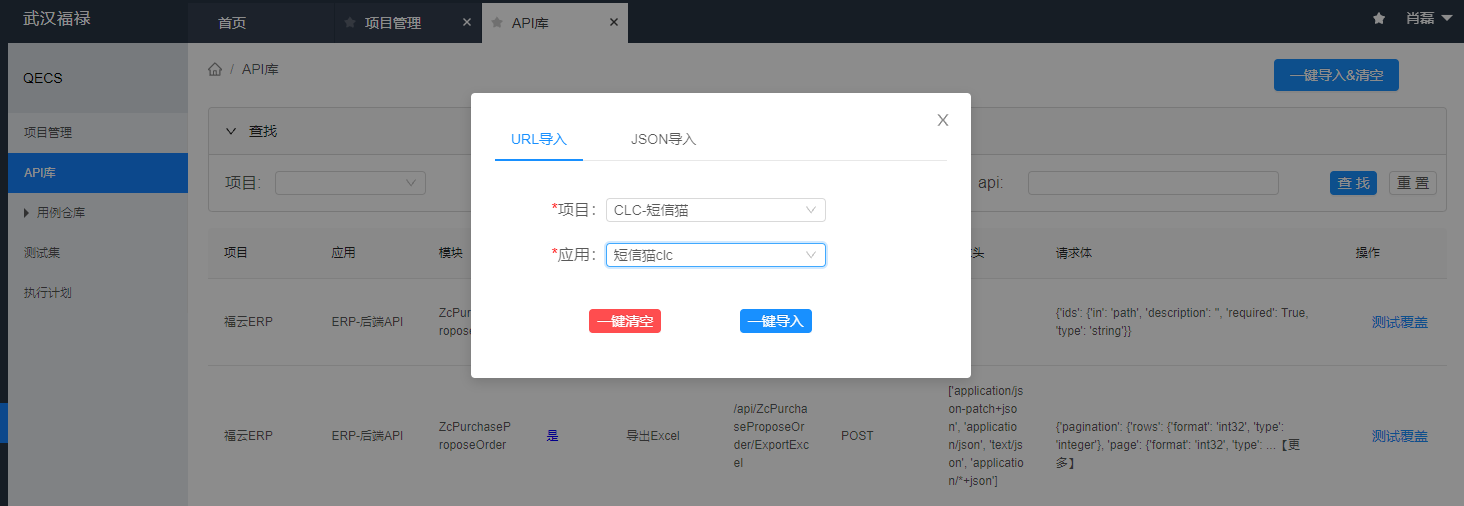
将来想知道API覆盖率轻而易举,API的用例编写到底写到什么程度,每个API如何设计的用例,平台化的收益逐渐兑现。
既要高效写用例,也要满足复杂的实现
初期我们希望借助平台化极大降低编写接口用例的技术门槛提高效率,将常用的编写方式搬入了平台。但是随着深入的应用,很多复杂的场景涉及到:多接口上下文依赖、接口数据逻辑处理、数据库操作.....这类场景如果全部平台实现,显然对平台的设计提出了更高的要求及灵活度的实现,还会使得平台功能略显臃肿。于是我们设计出两套用例编写模式:用户模式、专家模式。
用户模式
大部分接口独立存在,这些接口用例量大、编写难度低、覆盖场景清晰,那么我们就在平台上一次性写好写全,边写还能边调试,这才是正确的写用例姿势。
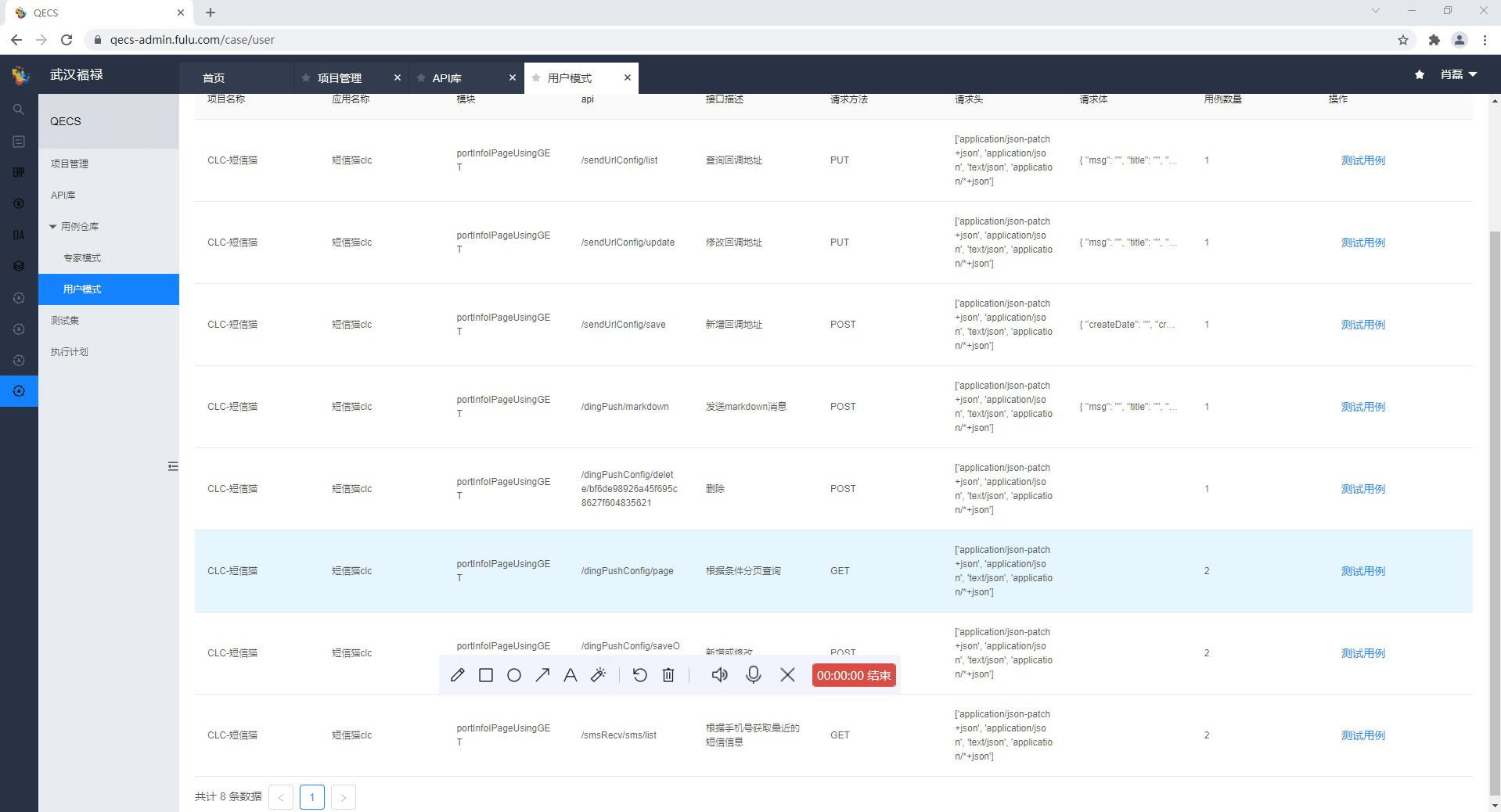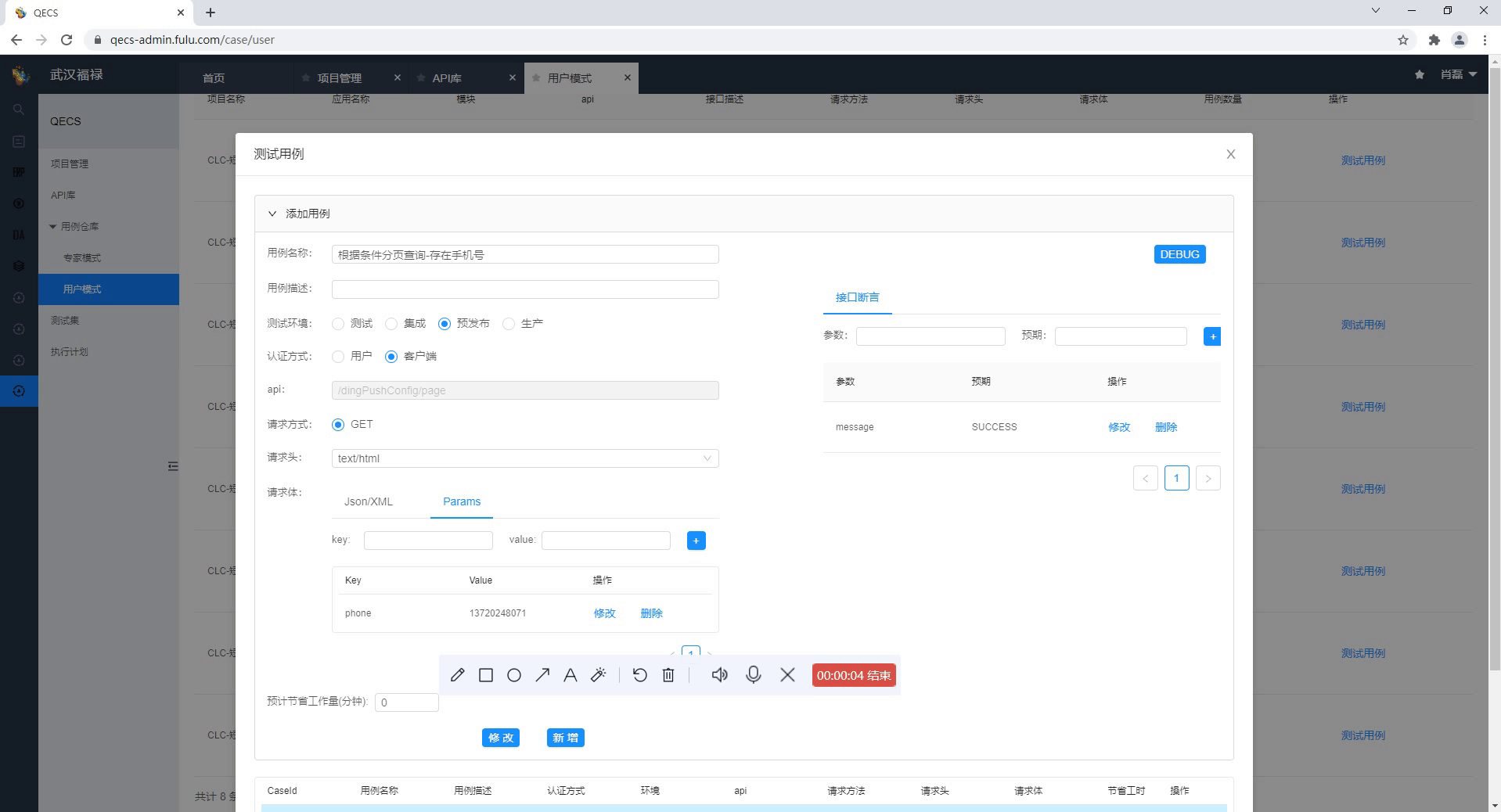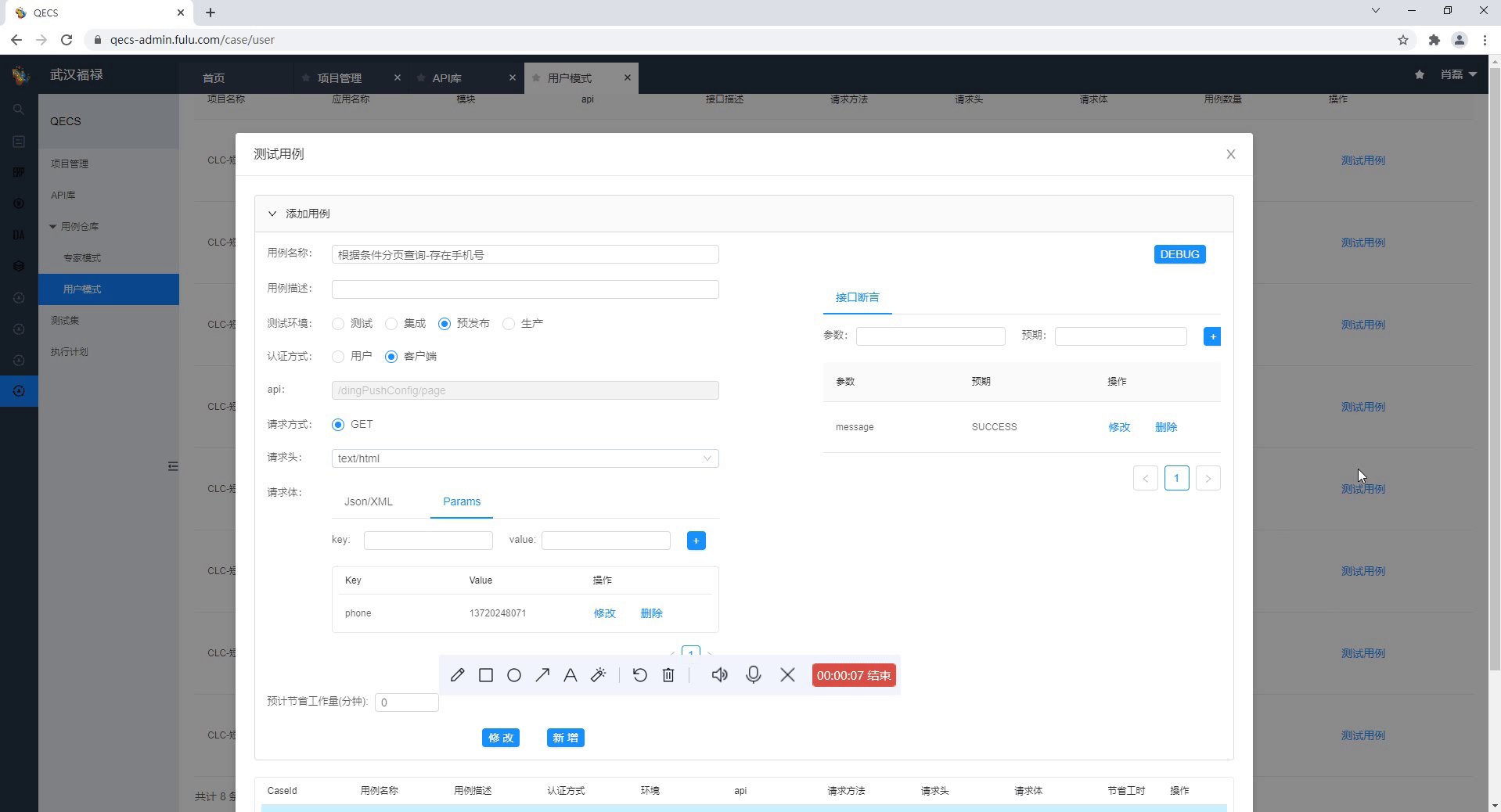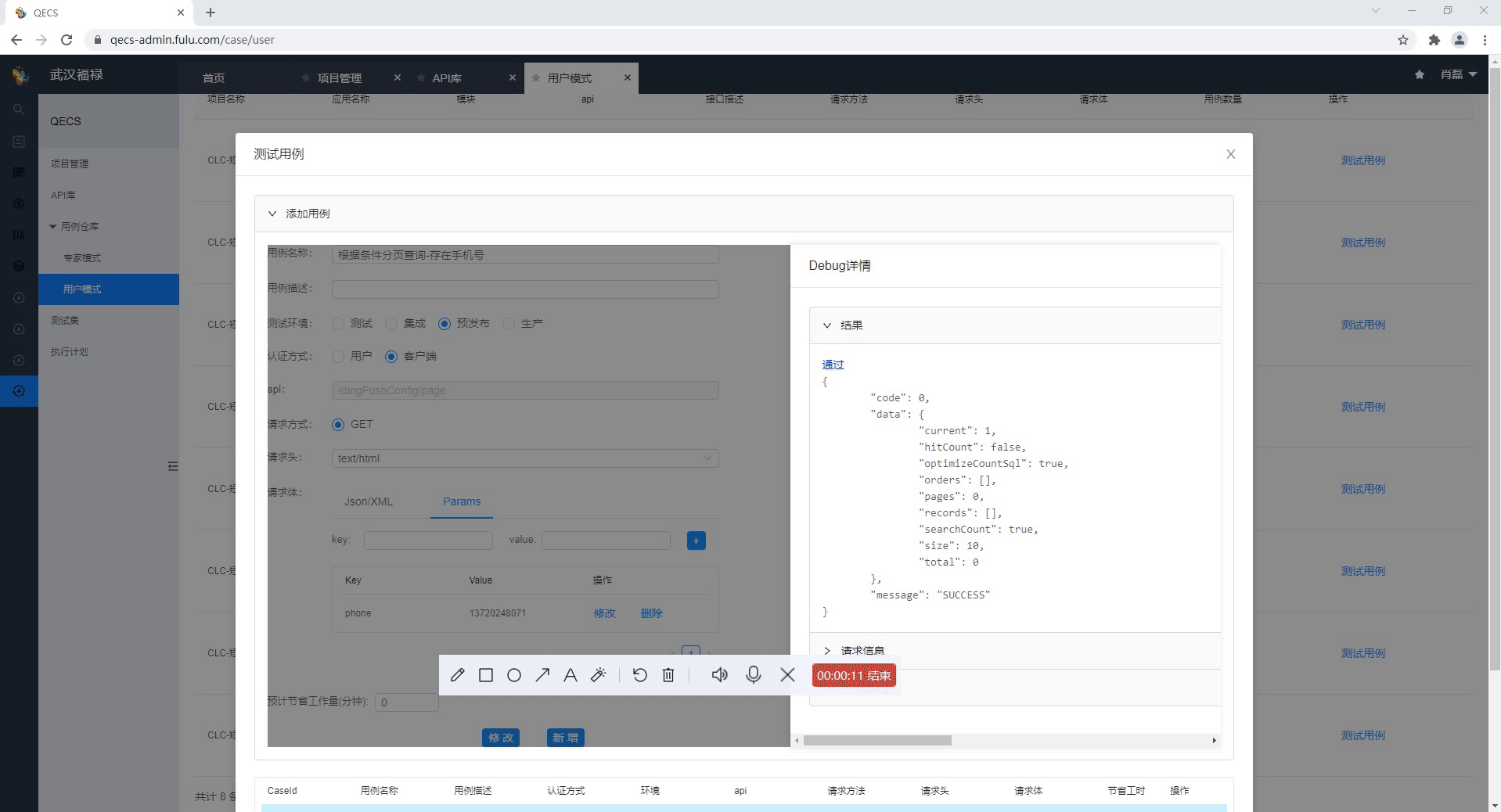
调试过程中遇到接口异常,提供了自动生成分布式日志链接,迅速通过日志进行问题定位
专家模式
为了避免平台功能过于臃肿,对于较为复杂的接口测试场景我们保留了“轻量化”代码途径。使用python+unittest构建脚本方式,一方面满足复杂用例设计,另一方面测开人员习惯于脚本编写方式完成用例设计。
unittest本身提供了一套完整case管理、执行、测试报告解决方案,但是我们要将所有的用例统一管理、兼容用户、专家混合模式执行、测试报告整合......于是对框架进行了二次改造。
第一步、对用例进行打标,代码工程化的结构能够移植到平台上进行管理及执行调度
我们通过装饰器属性进行解析改造
Case层
@annotation.class_annotation(case_name='战略大盘一纵上游商品大类', case_desc='战略大盘一纵上游商品大类')
class UpstreamCases(RunTestCase):
test_results = {}
test_data = {}
@classmethod
def setUpClass(cls):
# 如果本地unittest调试运行,不从runMain入口执行,需要放开下面两行注释,此段用于设置用例的测试环境和连接自动化平台的执行环境
Config.set_env('Staging')
cls.conf = ConfigRead()
super().setUpClass_(cls.conf)
cls.conn = MysqlQuery(cls.conf.SQL_SERVER, cls.conf.SQL_PORT, cls.conf.SQL_USER, cls.conf.SQL_PWD,
cls.conf.SQL_DATABASE)
def run(self, result=None):
"""
覆写unittest.testcase的测试用例运行方法,执行完用例完成结果回填
:param result: 测试结果参数
:return:
"""
# 如果本地unittest调试运行,不需要将执行结果回写平台数据库,可将第三个参数开关置为False
super().runCase(self.test_results, result, False)
self.test_results.clear()
@annotation(steps_name='获取战略大盘一纵上游商品大类数据', steps_desc='获取战略大盘一纵上游商品大类数据',
api_url=API_URL['upstream-goods-category'], api_method='POST')
def test_01_save_member(self):
data = {"startDate": "2021-01-01", "endDate": "2021-09-24"}
data = json.dumps(data)
path = urljoin(self.conf.FD_HOST, API_URL['upstream-goods-category'])
headers = {'Content-Type': ContentType['json']}
result = self.req.post_(path, headers, data=data)
self.test_results['response'] = result.text
self.test_results['status_code'] = result.status_code
self.test_results['response_time'] = result.elapsed.total_seconds()
verify_map = json.loads(result.content)
data = verify_map['data']
gmv = data['gmv']
member_gmv = 0
for item in data['list']:
member_gmv = member_gmv + item['gmv']
logger.info('获取战略大盘一纵下游行业大类数据成功:
Response = ' + result.text)
assert result.status_code == 200 and verify_map.get('message') == '成功!【战略大盘一纵上游商品大类】' and gmv >= member_gmv
装饰器解析
class MyAnnotation(object):
def __init__(self, **kwargs):
"""
解析测试类和测试方法注解的类装饰器
使用方法:
1. 在测试类上方添加@MyAnnotation.class_annotation(...)
2. 在测试方法上方添加@MyAnnotation(...)
:param kwargs:
"""
self.kwargs = kwargs
def __call__(self, func):
"""
方法装饰器
将注解内容解析出来存入方法的__annotations__属性中,获取时直接调用method.__annotations__
:param func: function
:return: function
"""
for item in self.kwargs.items():
key = item[0]
value = item[1]
func.__annotations__[key] = value
return func
@staticmethod
def class_annotation(**keywords):
"""
类装饰器
将注解内容解析出来存入类的__annotations__属性中,获取时直接调用class.__annotations__
:param keywords: dict参数
:return: class
"""
def func(cls):
class Wrapper(cls):
def __init__(self, *args, **kwargs):
setattr(self, '__annotations__', {})
for item in keywords.items():
key = item[0]
value = item[1]
self.__annotations__[key] = value
super().__init__(*args, **kwargs)
return Wrapper
return func
@staticmethod
def generate_cases(class_list):
"""
从class_list 获取要解析用例注解的class名
遍历class找出用例注解,并生成cases.yml文件
:param class_list: class列表
:return:
"""
for item in class_list:
cases = dict()
module = importlib.import_module(item)
class_ = inspect.getmembers(module, inspect.isclass)
target = list(filter(lambda f: f[0].endswith('Cases'), class_))[0]
class_name = target[0]
target_class = target[1]
loader = unittest.TestLoader().loadTestsFromTestCase(target_class)
test_suite = loader._tests
cases[class_name] = target_class().__annotations__
cases[class_name]['case_path'] = item
for i in test_suite:
test_name = i._testMethodName
case_an = getattr(target_class(), test_name).__annotations__
cases[class_name][test_name] = case_an
print(cases)
MyYaml().write(os.path.join(rootPath, 'target', '%s.yml' % class_name), cases)
@staticmethod
def recursive_dir(items, result, is_check_path=True):
"""
递归用例模块
:param items: 要递归的目录路径或用例路径
:param result: 递归的结果
:param is_check_path: 是否检查路径的开关,可不传,保持默认即可
:return:
"""
for item in items:
path = os.path.join(rootPath, item.replace('.', os.sep))
if is_check_path:
assert os.path.exists(path) or os.path.exists(path + '.py'), "不存在的路径:" + path
print('从%s扫描到模块如下:' % item)
if os.path.isdir(path):
files = [os.path.splitext(n)[0] for n in os.listdir(path) if not str(n).startswith('__')]
MyAnnotation.recursive_dir(['.'.join([item, n]) for n in files], result, False)
else:
if str(path.split(os.sep)[-1]).endswith('Cases') and os.path.exists(path + '.py'):
result.append(item)
print(item)
else:
continue
执行结果进行落库,便于测试结果汇总分析,重写runMain
def run_case(test_plan, field):
"""
使用unittest testRunner 执行用例,执行结束后回填测试数据到平台数据库
:param test_plan: 平台测试计划ID
:param field: sql环境字段
:return:
"""
# 使用左连接查询测试计划下专家用例集
sql = MysqlQuery(field.SQL_SERVER, field.SQL_PORT, field.SQL_USER, field.SQL_PWD, field.SQL_DATABASE)
sql_s = 'select case_plan_info.id, set_id, case_plan_info.run_env, case_plan_info.app_id from case_plan_info left join case_set on case_plan_info.set_id = case_set.id where plan_id = %d and run_mode = 1' % int(
test_plan)
query_list = sql.query(sql_s)
for item in query_list:
try:
test_suite = unittest.TestSuite()
case_report = {}
steps_report = {}
# 设置测试环境
env = item['run_env']
Config.set_env(env)
print('设置环境参数为:', env)
# 数据库查询出用例集中的用例
s = "select case_id from case_set_info where set_id = %d and is_del = 0" % item['set_id']
cases_set = sql.query(s)
for case in cases_set:
ss = 'select * from case_expert where id = %d' % int(case['case_id'])
query_rr = sql.query(ss)
class_ = query_rr[0]['case_class']
import_path = query_rr[0]['case_path']
case_name = query_rr[0]['case_name']
app_id = query_rr[0]['app_id']
# 执行用例前先在case_report中插入数据
sql.query(
"insert into case_report (plan_id, set_id, app_id, case_id, case_name, run_env) values (%d, %d, %d, %d, '%s', '%s')" % (
test_plan, item['set_id'], app_id, int(case['case_id']), case_name, env))
last_insert_id = sql.get_last_row_id()
update_field = sql.query('select * from case_report where id = %d' % last_insert_id)[0]
[update_field.pop(key) for key in ('create_time', 'update_time')]
title = '_'.join([env, class_])
case_report[title] = update_field
# 查询case用例中的步骤
ss = "select * from case_steps where case_id = %d and case_name = '%s'" % (
int(case['case_id']), case_name)
query_rr = sql.query(ss)
method_list = []
for step in query_rr:
method = step['method_name']
# 执行用例前先在steps_report中插入数据
sql.query(
"insert into steps_report (plan_id, steps_id, steps_name, case_id, case_name, run_env) values (%d, %d, '%s', %d, '%s', '%s')" % (
test_plan, step['id'], step['steps_name'], step['case_id'], step['case_name'], env))
last_insert_id = sql.get_last_row_id()
update_field = sql.query('select * from steps_report where id = %d' % last_insert_id)[0]
[update_field.pop(key) for key in ('create_time', 'update_time')]
none_list = [k for k, v in update_field.items() if v is None]
list(map(lambda f: update_field.pop(f), none_list))
sub_title = '_'.join([title, method])
globalVar.set_key(sub_title, update_field)
steps_report[sub_title] = update_field
# 动态import用例模块
module = importlib.import_module(import_path)
object_ = getattr(module, class_)
method_list.append(object_(method))
test_suite.addTests(method_list)
test_result = unittest.TextTestRunner(verbosity=2).run(test_suite)
print(test_result)
# 判断测试执行结果,并回填测试数据到数据库
if test_result.wasSuccessful():
for raw in case_report.values():
sql.query("update case_report set status = 1 where id = %d" % raw['id'])
else:
# 回填用例测试状态 case_report
for key, value in case_report.items():
steps_id = ','.join([str(v['id']) for k, v in steps_report.items() if k.startswith(key)])
step_status = sql.query(
"select count(status) as count from steps_report where id in (%s) and status = 1" % steps_id
)[0]['count']
if step_status == len(steps_id.split(',')):
sql.query("update case_report set status = 1 where id = %d" % value['id'])
else:
sql.query("update case_report set status = 2 where id = %d" % value['id'])
# 回填测试状态 case_plan_info
case_id = ','.join([str(value['id']) for value in case_report.values()])
case_status = sql.query(
"select count(status) as count from case_report where id in (%s) and status = 2" % case_id
)[0]['count']
if case_status:
sql.query("update case_plan_info set status = 2 where id = %d" % item['id'])
else:
sql.query("update case_plan_info set status = 1 where id = %d" % item['id'])
except:
print("runMain 执行异常,报错如下:")
traceback.print_exc()
sql.query("update case_plan_info set status = 2 where id = %d" % item['id'])
根据平台管理维度,生成Case脚本转为yml文件,导入至平台进行统一管理
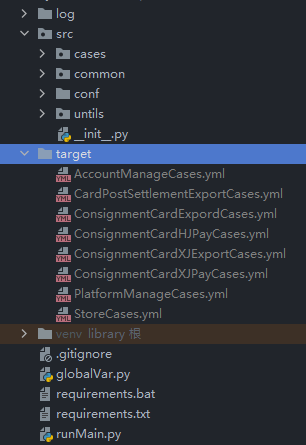
StoreCases:
case_desc: 完成数据新增->查询->修改->删除
case_name: 店铺基础流程
case_path: src.cases.erp.storeCases
test_01_create:
api_method: POST
api_url: /api/Store
steps_desc: 新增店铺
steps_name: 新增店铺
test_02_find:
api_method: GET
api_url: /api/Store
steps_desc: 查询店铺
steps_name: 查询店铺
test_03_update:
api_method: PUT
api_url: /api/Store
steps_desc: 更新店铺
steps_name: 更新店铺
test_04_del:
api_method: DELETE
api_url: /api/Store
steps_desc: 删除店铺
steps_name: 删除店铺
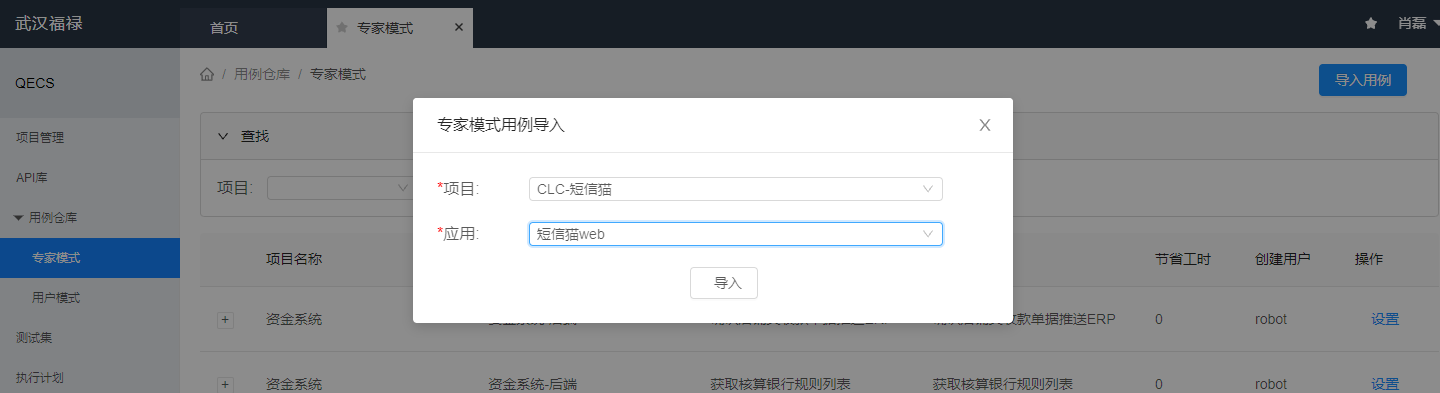
质量门禁搭建
中心项目已完成容器化一键发布,平台与发布流程高度集成,我的期望是每次完成发版后,自动触发接口用例的执行,并且根据不同的测试环境及迭代情况,定制我们的覆盖范围。测试人员在每次收到提测通知前,接口测试先行自测,根据测试结果判断是否满足提测要求。
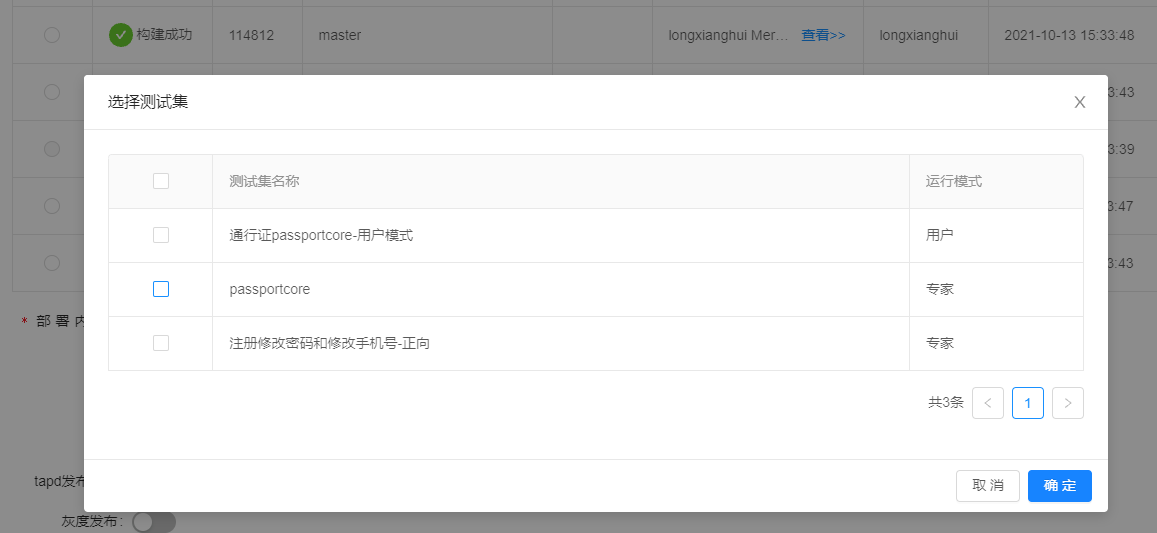
完成CD后自动运行所配置的测试集,并已钉钉消息方式通知到相关测试人员,查看测试结果。
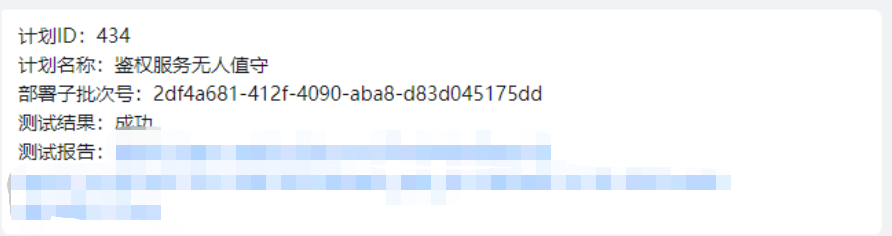
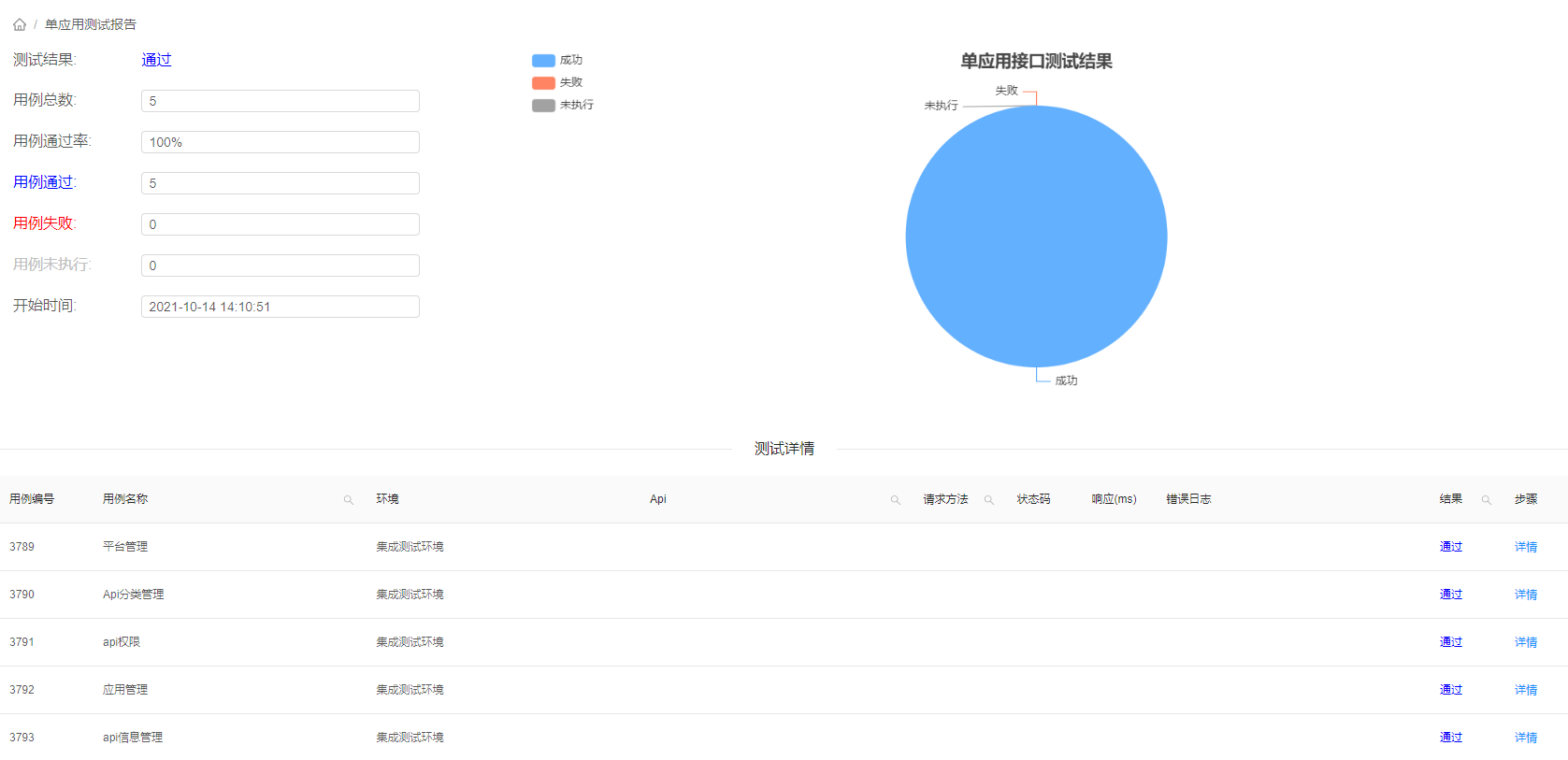
我们接下来
TestOps是我们未来长期建设的目标,我们将基于接口测试为基础,逐步完善我们的专业线基建,使得我们“质量门禁”更丰富......
我们还是一个“年轻的”质量团队,在质量工程建设上现在仅仅迈出了第一步,接下来我们正在设计不一样的“数据工厂”、无代码化的mockserver.......尽请期待☺
未来我们逐渐完善平台功能后,也会进行开源,希望更多朋友一起参与到质量工程建设当中,一起交流讨论实践心得!