一、安装
安装依赖包:
yum install glib2-devel mysql-devel zlib-devel pcre-devel openssl-devel cmake
下载二进制包:
解压安装:
tar zxvf mydumper-0.9.1.tar.gz cd mydumper-0.9.1/ cmake . make make install
安装完成后生成两个二进制文件mydumper和myloader位于/usr/local/bin目录下
查看是否正常:
mydumper --help
二、原理介绍
mydumper介绍
MySQL自身的mysqldump工具支持单线程工作,依次一个个导出多个表,没有一个并行的机,这就使得它无法迅速的备份数据。
mydumper作为一个实用工具,能够良好支持多线程工作,可以并行的多线程的从表中读入数据并同时写到不同的文件里,这使得它在处理速度方面快于传统的mysqldump。其特征之一是在处理过程中需要对列表加以锁定,因此如果我们需要在工作时段执行备份工作,那么会引起DML阻塞。但一般现在的MySQL都有主从,备份也大部分在从上进行,所以锁的问题可以不用考虑。这样,mydumper能更好的完成备份任务。
mydumper特性
①多线程备份
②因为是多线程逻辑备份,备份后会生成多个备份文件
③备份时对MyISAM表施加FTWRL(FLUSH TABLES WITH READ LOCK),会阻塞DML语句
④保证备份数据的一致性
⑤支持文件压缩
⑥支持导出binlog
⑦支持多线程恢复
⑧支持以守护进程模式工作,定时快照和连续二进制日志
⑨支持将备份文件切块
mydumper参数详解

$ mydumper --help Usage: mydumper [OPTION...] multi-threaded MySQL dumping Help Options: -?, --help Show help options Application Options: -B, --database 要备份的数据库,不指定则备份所有库 -T, --tables-list 需要备份的表,名字用逗号隔开 -o, --outputdir 备份文件输出的目录 -s, --statement-size 生成的insert语句的字节数,默认1000000 -r, --rows Try to split tables into chunks of this many rows. This option turns off --chunk-filesize -F, --chunk-filesize Split tables into chunks of this output file size. This value is in MB -c, --compress Compress output files压缩输出文件 -e, --build-empty-files 如果表数据是空,还是产生一个空文件(默认无数据则只有表结构文件) -x, --regex Regular expression for 'db.table' matching 使用正则表达式匹配'db.table' -i, --ignore-engines Comma delimited list of storage engines to ignore忽略的存储引擎,用逗号分割 -m, --no-schemas Do not dump table schemas with the data不备份表结构,只备份数据 -d, --no-data Do not dump table data备份表结构,不备份数据 -G, --triggers Dump triggers备份触发器 -E, --events Dump events -R, --routines Dump stored procedures and functions备份存储过程和函数 -k, --no-locks 不使用临时共享只读锁,使用这个选项会造成数据不一致 --less-locking Minimize locking time on InnoDB tables.减少对InnoDB表的锁施加时间 -l, --long-query-guard 设定阻塞备份的长查询超时时间,单位是秒,默认是60秒(超时后默认mydumper将会退出) -K, --kill-long-queries Kill long running queries (instead of aborting)杀掉长查询 (不退出) -D, --daemon Enable daemon mode启用守护进程模式,守护进程模式以某个间隔不间断对数据库进行备 -I, --snapshot-interval dump快照间隔时间,默认60s,需要在daemon模式下 -L, --logfile 使用的日志文件名(mydumper所产生的日志), 默认使用标准输出 --tz-utc SET TIME_ZONE='+00:00' at top of dump to allow dumping of TIMESTAMP data when a server has data in different time zones or data is being moved between servers with different time zones, defaults to on use --skip-tz-utc to disable. --skip-tz-utc --use-savepoints 使用savepoints来减少采集metadata所造成的锁时间,需要 SUPER 权限 --success-on-1146 Not increment error count and Warning instead of Critical in case of table doesn't exist --lock-all-tables Use LOCK TABLE for all, instead of FTWRL -U, --updated-since Use Update_time to dump only tables updated in the last U days --trx-consistency-only Transactional consistency only -h, --host 连接的主机名 -u, --user 用来备份的用户名 -p, --password 用户密码 -P, --port 连接端口 -S, --socket 使用socket通信时的socket文件 -t, --threads 开启的备份线程数,默认是4 -C, --compress-protocol 压缩与mysql通信的数据 -V, --version 显示版本号 -v, --verbose 输出信息模式, 0 = silent, 1 = errors, 2 = warnings, 3 = info, 默认为2
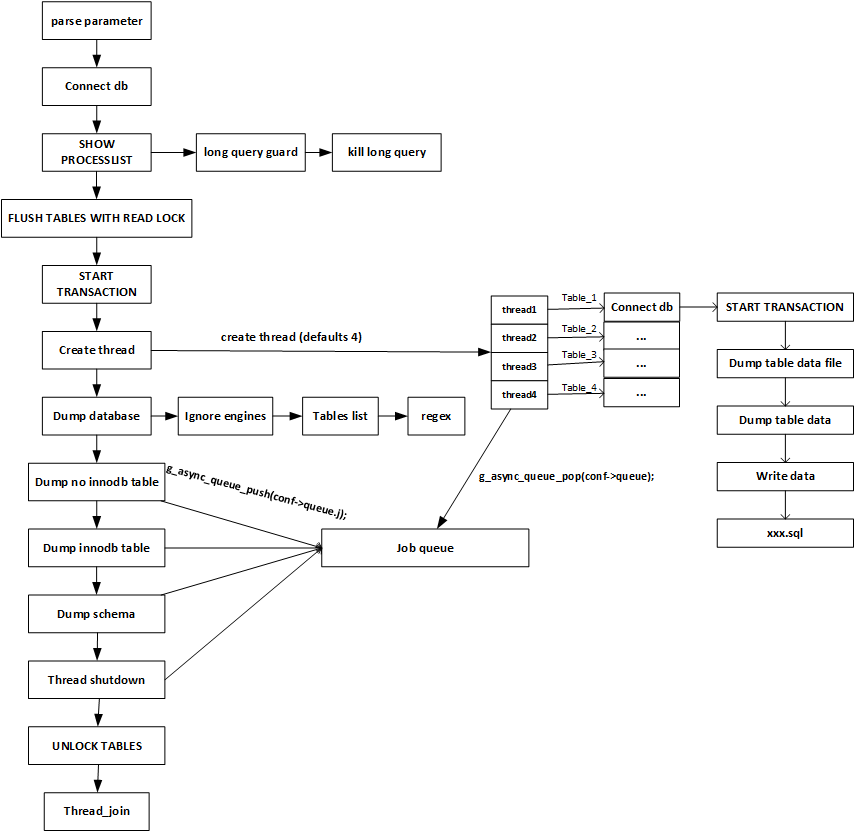
mydumper主要流程概括
1、主线程 FLUSH TABLES WITH READ LOCK, 施加全局只读锁,以阻止DML语句写入,保证数据的一致性
2、读取当前时间点的二进制日志文件名和日志写入的位置并记录在metadata文件中,以供即使点恢复使用
3、N个(线程数可以指定,默认是4)dump线程 START TRANSACTION WITH CONSISTENT SNAPSHOT; 开启读一致的事务
4、dump non-InnoDB tables, 首先导出非事务引擎的表
5、主线程 UNLOCK TABLES 非 事务引擎备份完后,释放全局只读锁
6、dump InnoDB tables, 基于 事务导出InnoDB表
7、事务结束
mydumper的less locking模式:
mydumper使用--less-locking可以减少锁等待时间,此时mydumper的执行机制大致为
1、主线程 FLUSH TABLES WITH READ LOCK (全局锁)
2、Dump线程 START TRANSACTION WITH CONSISTENT SNAPSHOT;
3、LL Dump线程 LOCK TABLES non-InnoDB (线程内部锁)
4、主线程UNLOCK TABLES
5、LL Dump线程 dump non-InnoDB tables
6、LL DUmp线程 UNLOCK non-InnoDB
7、Dump线程 dump InnoDB tables
mydumper备份流程图