
构建大规模Prometheus-第一部分
最近需要实施一个Prometheus HA解决方案的项目。简单说下需求:
他们有一个100多个节点的Kubernetes集群,他们想将数据尽可能保存更长时间。
万一Prometheus挂了,他们没有备份节点
他们也需要Prometheus的伸缩解决方案。
解决方案
对于HA部分,采用联邦集群机制,对于长期存储的话,考虑使用Thanos,但是在研究过程中发现一个新项目,叫Cortex,以下是thanos和Cortex的比较:
CortexThanos存储 injestors 中的最新数据存储Prometheus中的最新数据使用Prometheus write API写入使用Sidecar方法写入支持长期存储支持长期存储支持HA不支持HA可和多个Prometheus集成单个
经过对比这些指标,决定采用Cortex。
但Cortex方案本身也存在一定的缺陷,如:
体系结构较复杂,需要深入了解Prometheus的 TSDB
对CPU、内存要求较高
会增加远程存储成本,例如S3,GCS,Azure存储等。
由于这几个因素对我们来说都不是问题,于是就开干了,而且挺好用的。
对于 Prometheus 的缩放,Prometheus 由于设计问题,只能垂直而不能水平缩放
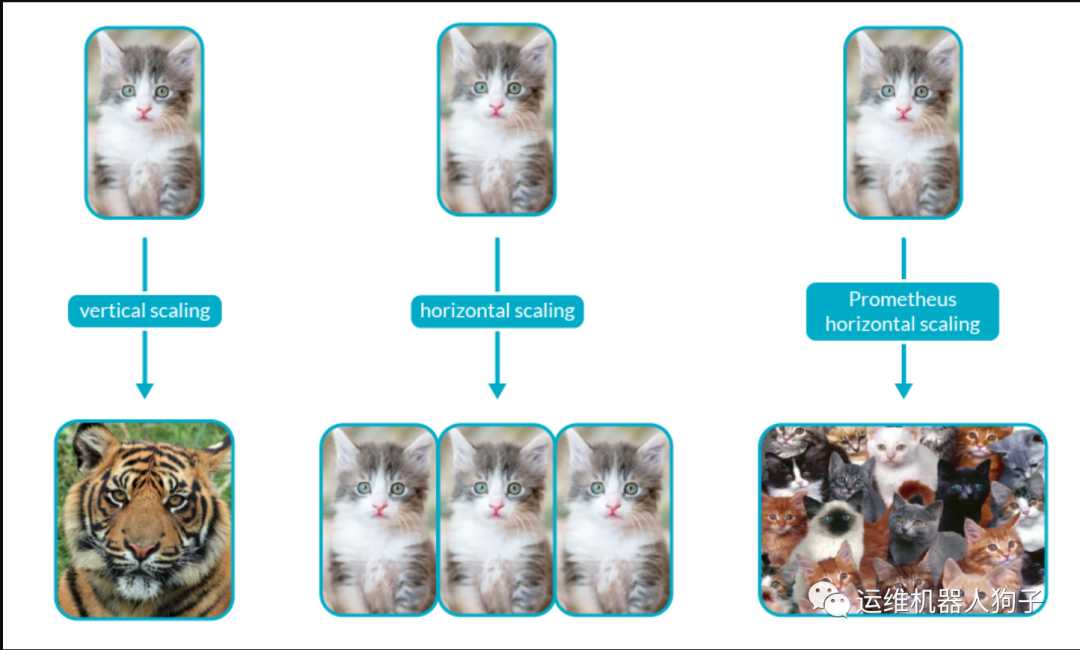
如果尝试水平缩放Prometheus,最终将得到分散的数据,这些数据无法轻松合并,因此就缩放部分而言,我们建议采用垂直方法。
为了自动化Kubernetes中Prometheus的垂直缩放,我们使用了VPA(Vertical Pod Autoscaler)。它可以根据资源的使用情况来缩减对资源过度使用的Pod的规模,也可以缩减对资源过度需求的Pod的规模。
结论
这篇文章看到了在Prometheus中实现高可用性,可伸缩性和长期存储所采用的方法。下一篇,我会给出实际操作方法。