学习心得及问题总结
总结
杨思恒
机器学习相比逻辑推理知识工程等传统技术,是基于概率论中的模型、策略和算法发展起来的。在经过算法和算力等的发展下,深度学习越来越成熟了,在图像识别,语言处理等方面都有着广泛的应用。
但深度学习也并非无所不能的,它也有一些缺点,如算法输出不稳定,容易被攻击;模型复杂度高,难以纠错和调试;模型层级复合程度高,参数不透明;端对端训练方式对数据依赖性强,模型增量性差;专注直观感知类问题,对开放性推理问题无能为力;人类知识无法有效引入进行监督,机器偏见难以避免等等。
神经网络学习通过利用矩阵的线性变换加激活函数的非线性变换,将原始输入控件投影到线性可分的空间区分类回归。神经网络的层数并非越多越好,层数过多可能会产生梯度消失。一般来说,三层神经网络为最优。
常虹
看了这个视频总体感受就是挺迷的,第一次接触,了解了不一样的东西,同时也觉得数学真的是特别有用,和我们的专业关联很大,甚至还有物理知识,融会贯通,想到小时候大人们说的:“学好物理化,走遍全天下”,这句话不是没有道理的,数学就像地基一样,相当重要。对于机器学习呢,感觉他很神奇,通过代码和数学知识就能解决很多问题,模拟人的神经网络,觉得高深莫测,但是了解了原理的话又会说:“原来是这个样子的,就像大脑在学习工作”。
傅芷琴
知识工程/专家系统:有人工参与,人工定义辅助的这种专家系统的学习结果容易解释,不过不够准确,具有一定主观性,同时需要一定精力去构建所需要的模型,费时费力。
机器学习:机器自动训练模式,这个模式更加客观,准确,需要大量数据作为机器学习的支撑。
机器学习的学习过程中需要问题建模,确定目标函数,确定最优模型,求解模型参数。
传统机器学习:在输入原始数据之后,进行特征处理(手动设计特征),然后进行机器的浅层学习,训练和测试分类器,然后输出结果。
深度学习:搜集大量数据,选择合适的深度模型,确定模型超参数,之后让机器进行优化学习找到最有效的结果。
后深度学习:给数据,机器学习给结果。
深度学习应用领域可以在在视觉和语言。
深度学习在探索过程中要发现现在还“不能”解决的问题,以便更好发展。
深度学习的“不能”:
算法输出不稳定,容易被“攻击”。(稳定性低)
模型复杂度高,难以纠错和调试。(可调试性差)
模型层级复合程度高,参数不透明。(参数不透明)
端到端训练方式对数据依赖性强,模型增量性差。(增量性差)
专注直观感知类问题,对开放性推理问题无能为力。(推理能力差)
人类知识无法有效引入进行监督,机器偏见难以避免。(机器偏见)
通过激活函数和线性函数的作用使得整个神经网络获得非线性拟合能力。
单层感知器是首个可以学习的人工神经网络。在多层感知器中,三层感知器能实现同或门。
万有逼近定理:
一个隐层包含足够多神经元,三层前馈神经网络能以任意精度逼近任意预定的连续函数。
双隐层感知器逼近非连续函数。
多层神经网络问题:梯度消失。
自编码器:多层神经网络(三层)
受限玻尔兹曼机(RBM)
多家赫
看了这个视频,我觉得深度学习的过程就是把训练时的输入数据通过这台机器经过一些算法处理获得输出数据,然后把输出数据与训练数据的输入数据的正确结果做对比判断其误差,经过无数次的反复训练,最终把误差控制到最小最理想的范围内则学习过程结束。深度学习应该就是我们所说的人工智能,或者说是人工智障,有了深度学习,未来也就有了无线的可能。
余闽喆
深度学习是机器学习的一个分支,应用了深度神经网络的机器学习称为深度学习。而二者的区别在于:机器学习主要还是依赖于人工来帮助定义特征,所有的规则是白盒的,设计者肯定清楚结果的走向。而深度学习有个非常重要的特征就是“黑盒”,因为它不是按照人为的设计来运作每一步的,只是在一个建模、评价、优化的模型框架中,而具体的细节是不可知的。算法输出不稳定;模型复杂度高,难以纠错和调试;模型层级复合程度高,参数不透明;端对端训练方式对数据依赖性强,模型增量性差;专注直观感知类问题,对开放性推理问题无能为力;人类知识无法有效引入进行监督,机器偏见难以避免等等。这是很多人所说的缺点,但是我认为正是“细节不可知”,让深度学习能够超越人类代替人类做一些事情成为了可能。
邓皓文
看了这个视频,我对深度学习有了新的想法,我认为深度学习不只是为了提高学习效率更多的是用于建立、模拟人脑进行分析学习的神经网络,同时并模仿人脑的机制来解释数据的一种机器学习技术。例如我们实验可以知道不能只靠图库里的机械化的程序去识别图片,更多的要像神经一样靠训练和大量的数据支撑以及同时需要更多的运算力支撑。
问题
激活函数是如何选择的?如何去选择一个最优的激活函数?
逐层预训练解决梯度消失这方面没有很理解。
三层前馈神经网络的BP算法详解。
没太理解RBM模型求解求解到的结果有什么作用。
如今有没有公开的实例代码用于学习轻量级的深度学习?
深度学习对于硬件需求特别高,那么移动端是不是就没有效率进行深度学习了?

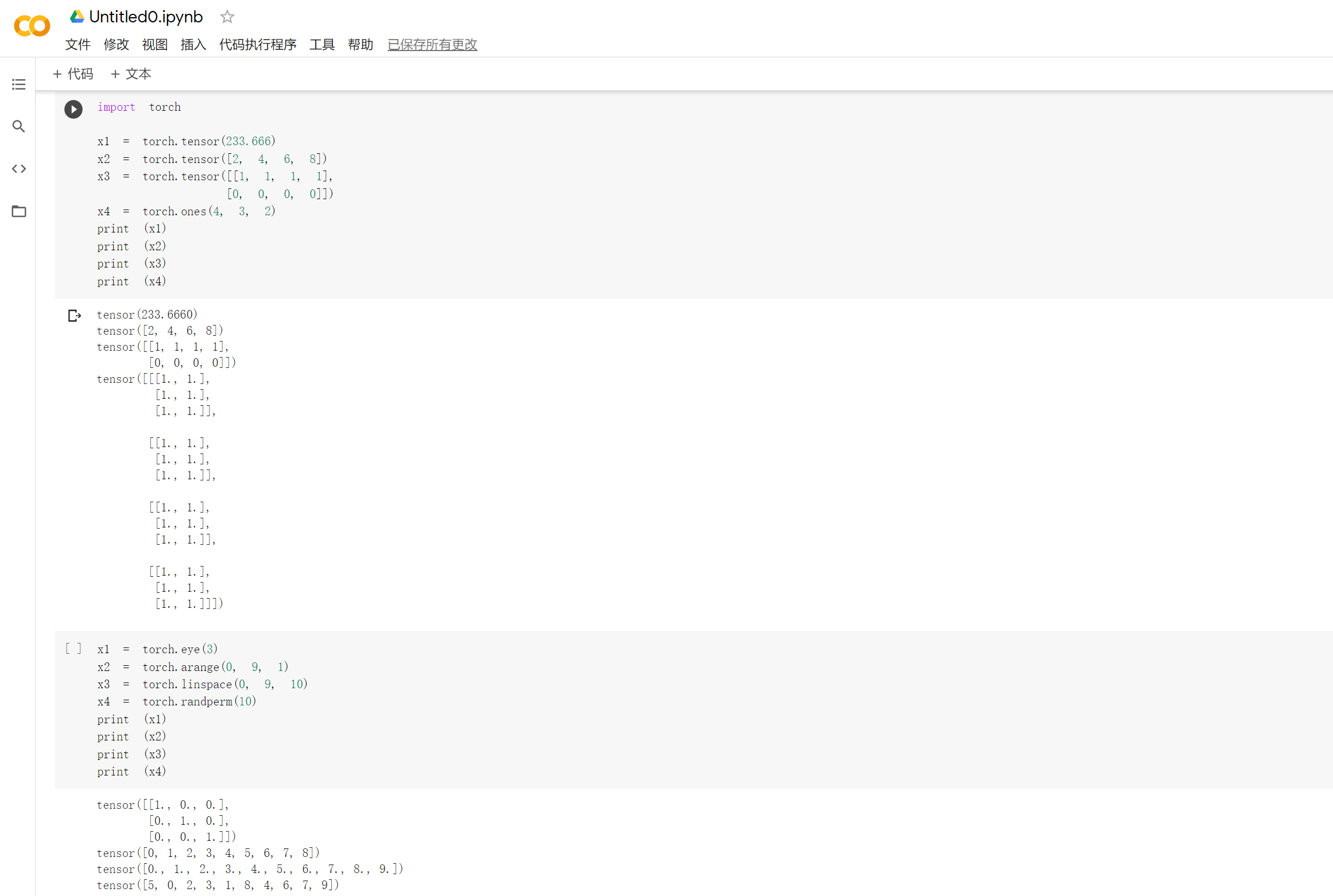
Tensor 和之前的 tensor 有何区别?
答: torch.Tensor是主要的tensor类,所有的tensor都是torch.Tensor的实例。torch.tensor是一个函数,返回的是一个tensor. 所以torch.Tensor应该说是同时具有torch.tensor和torch.empty的功能,但是使用torch.Tensor可能会使你的代码confusing,所以最好还是使用torch.tensor和torch.empty,而不是torch.Tensor。

这个为什么会打出个点??
代码练习
2.1 基础练习
想法和解读:
pytorch中的tensor(张量)是特有的数据类型,它可以由各种各样的数据类型创建而成。查阅资料后发现,之所以引入tensor这个数据类型主要是由于深度学习中的训练的数据集的数量都特别巨大,利用tensor可以将这些数据集放在GPU中加速运算。
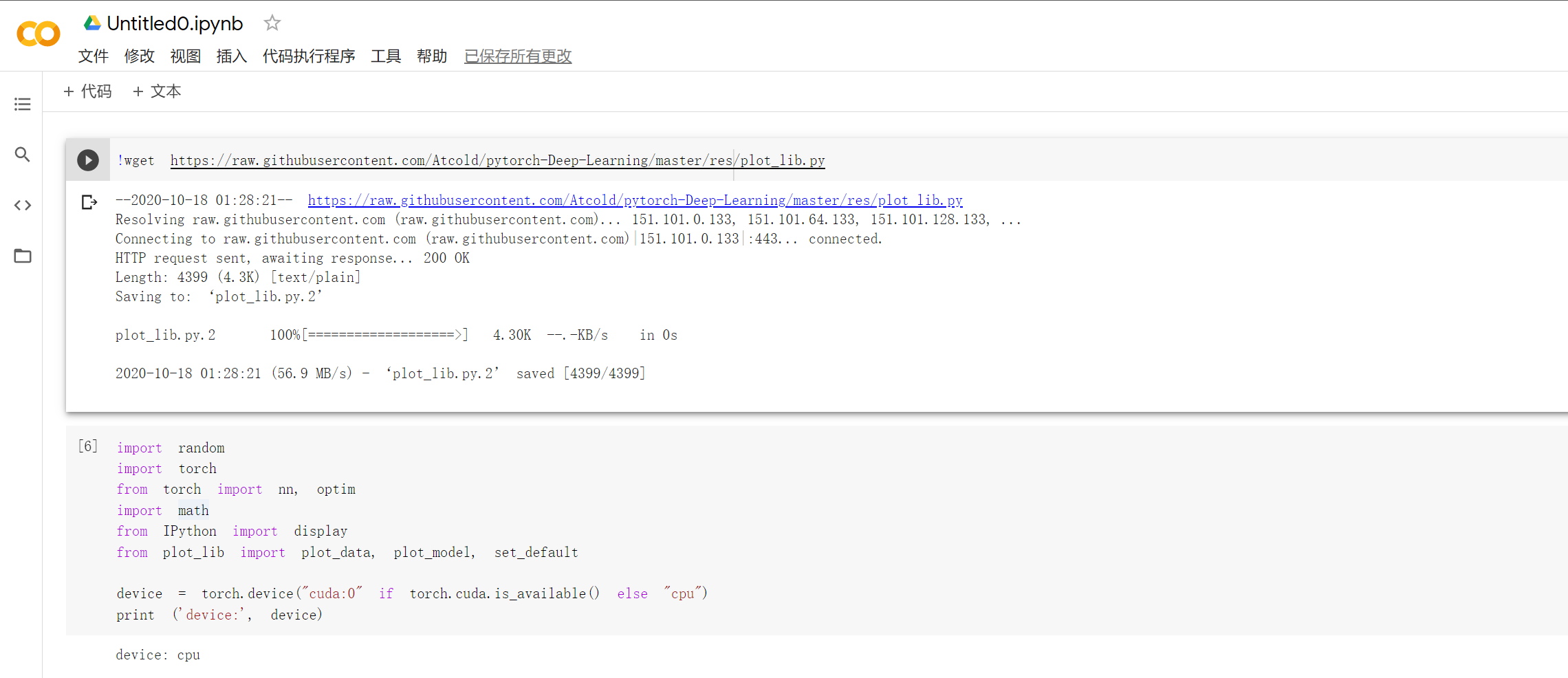
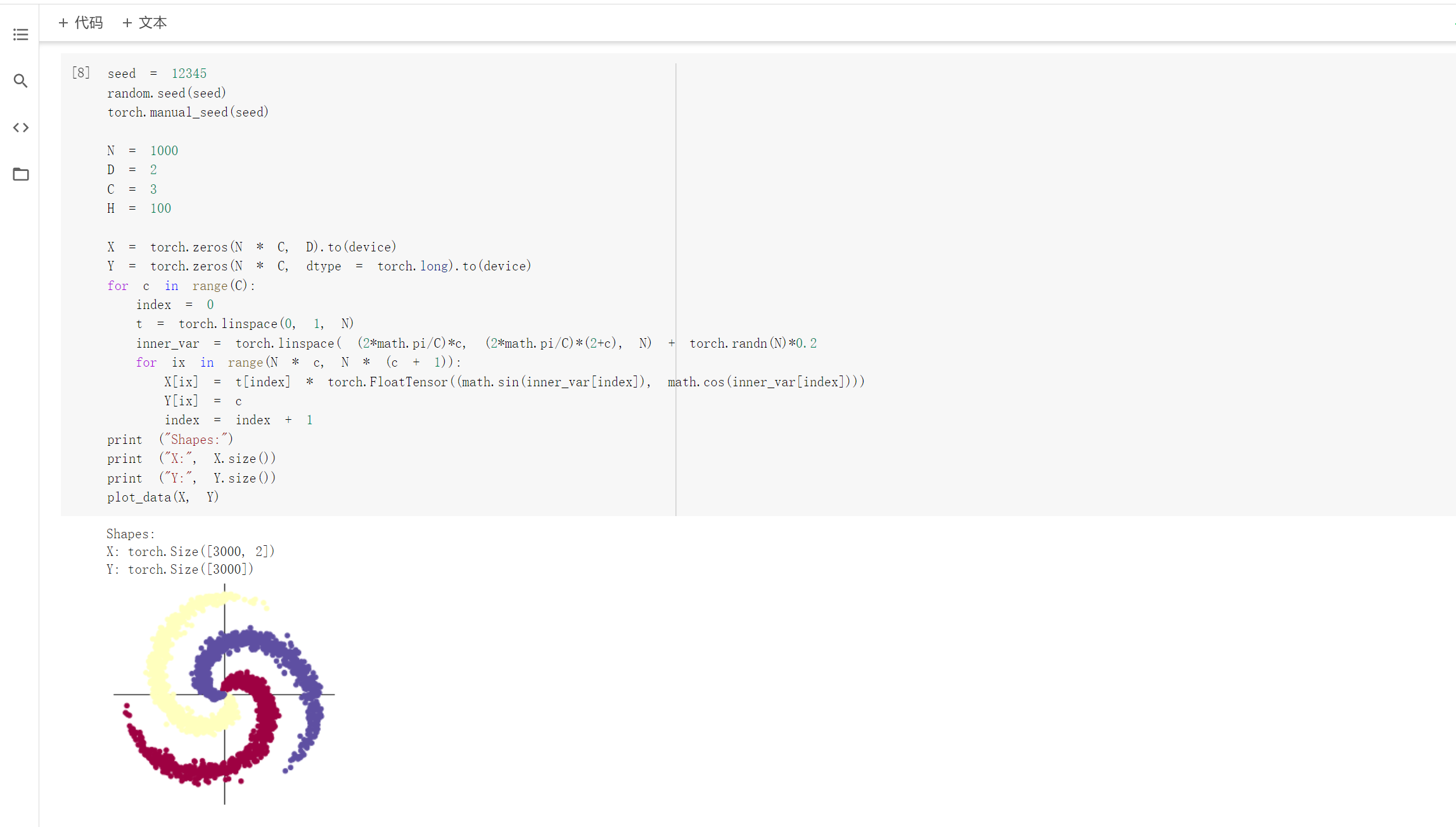
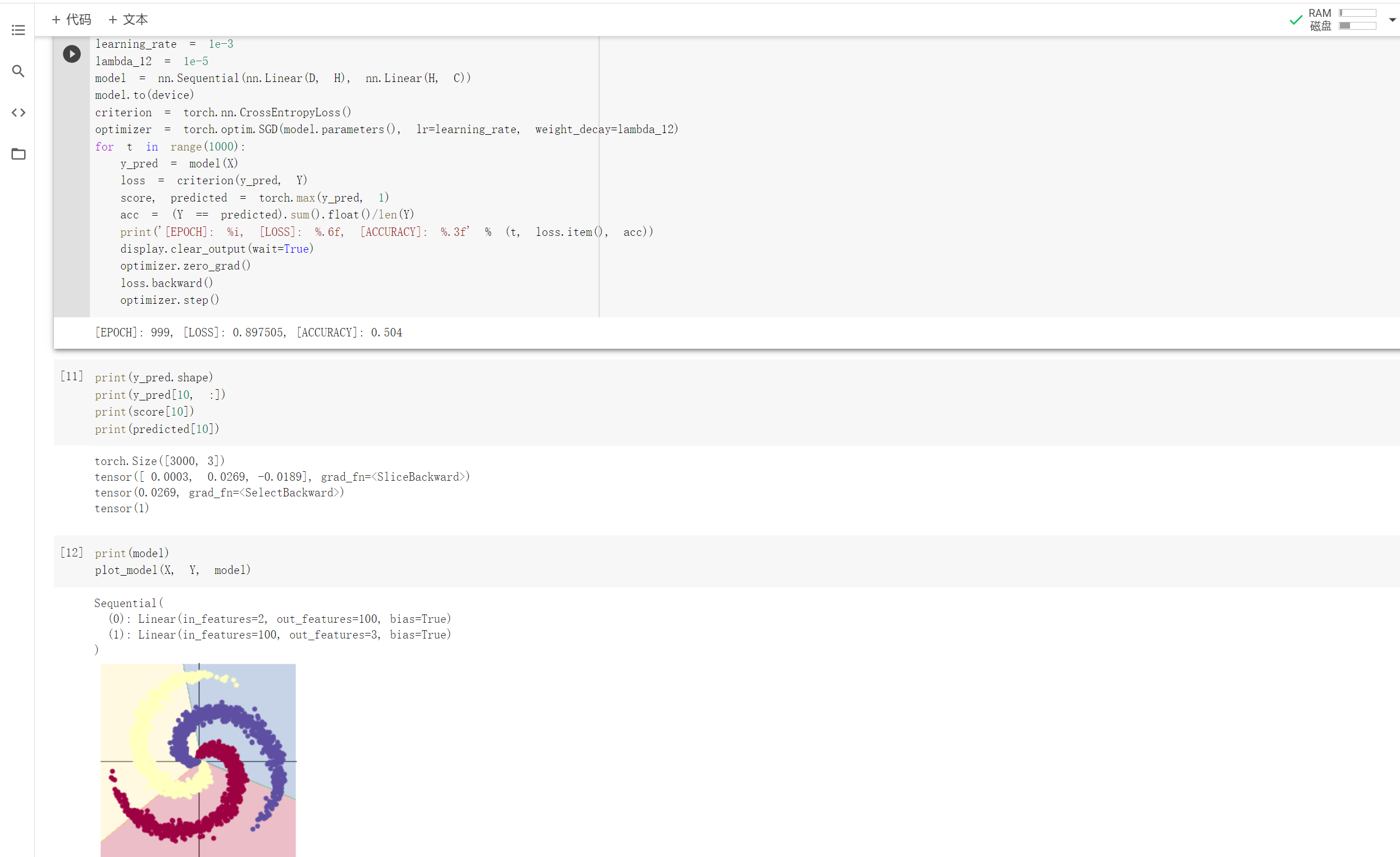
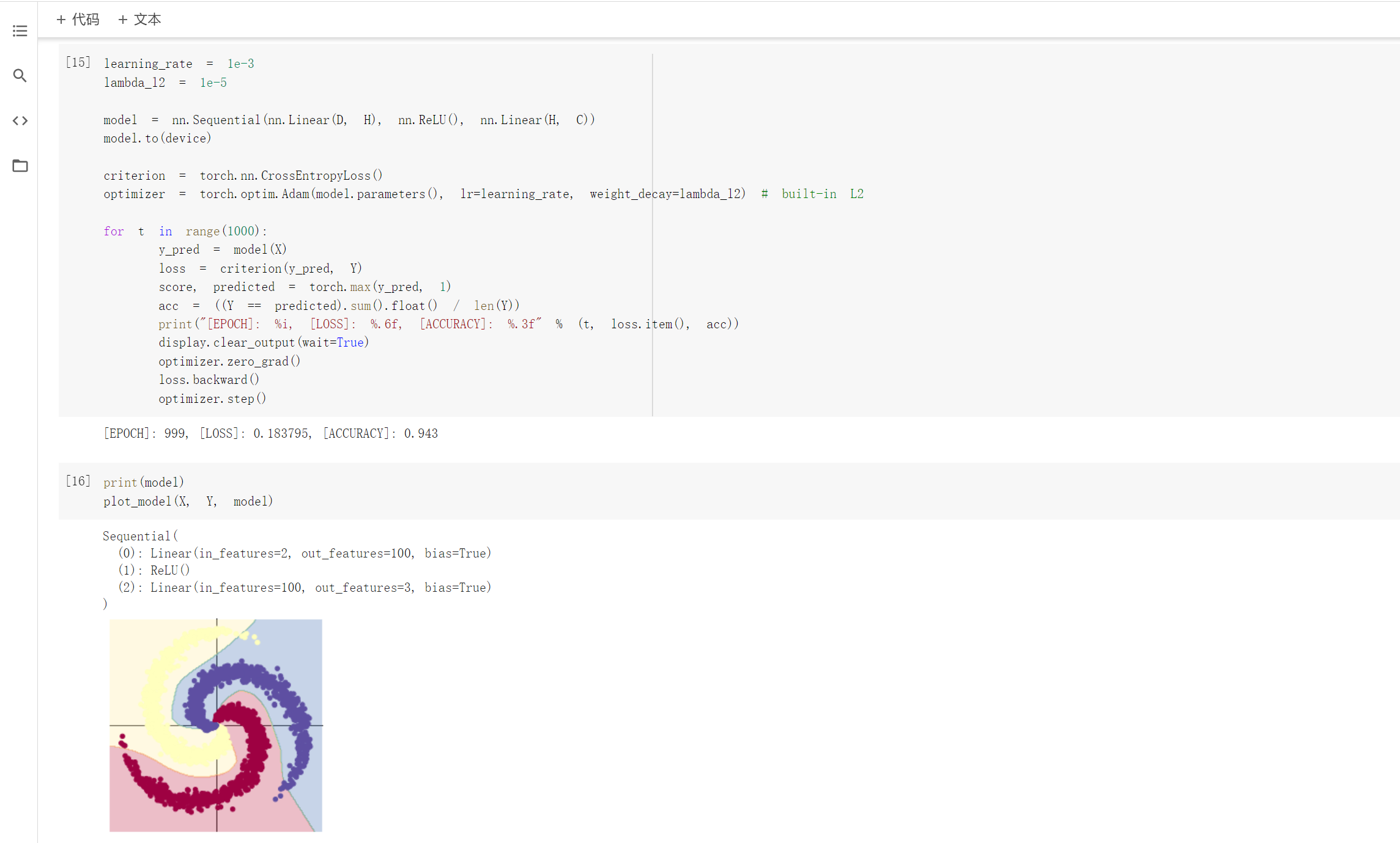
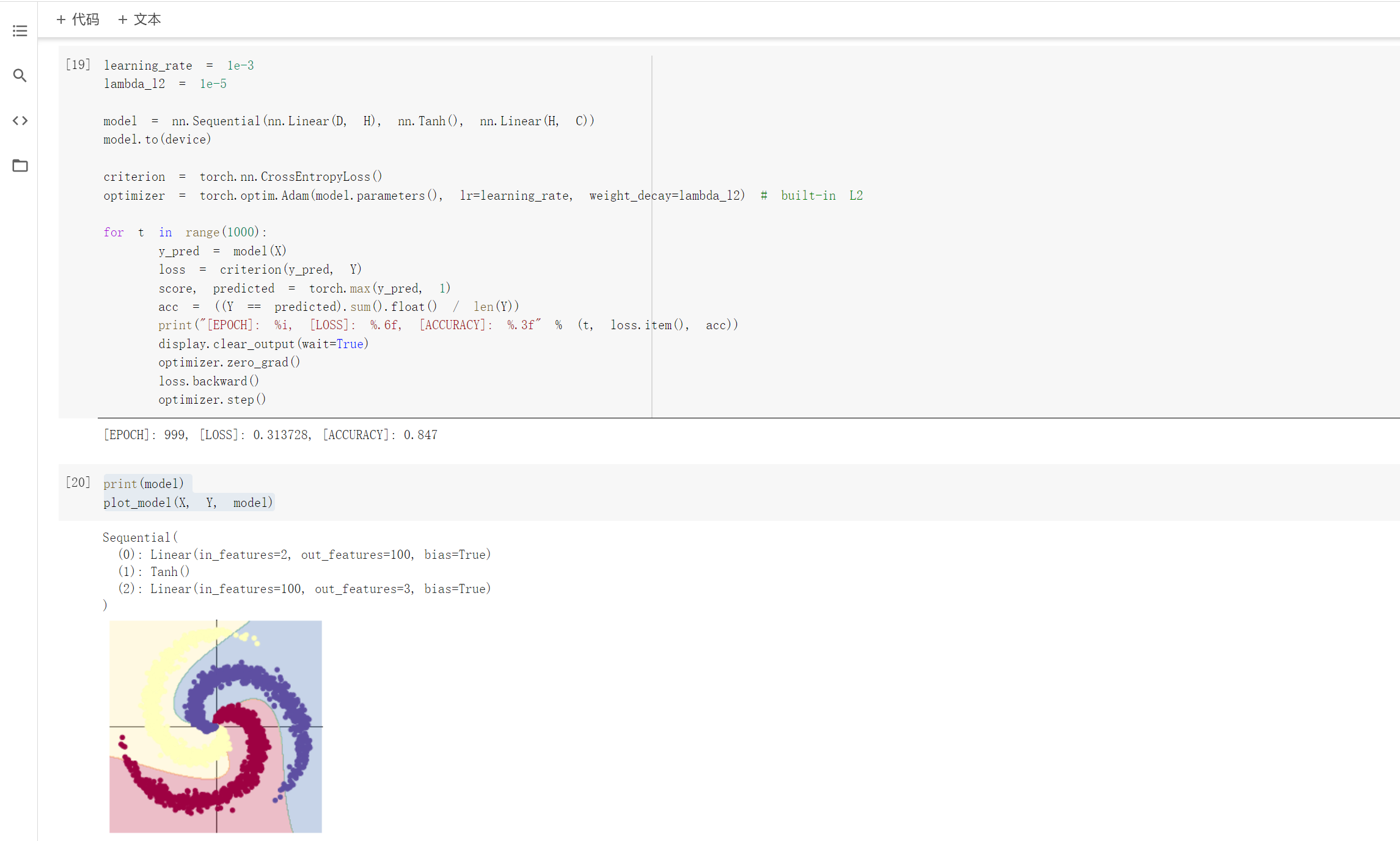
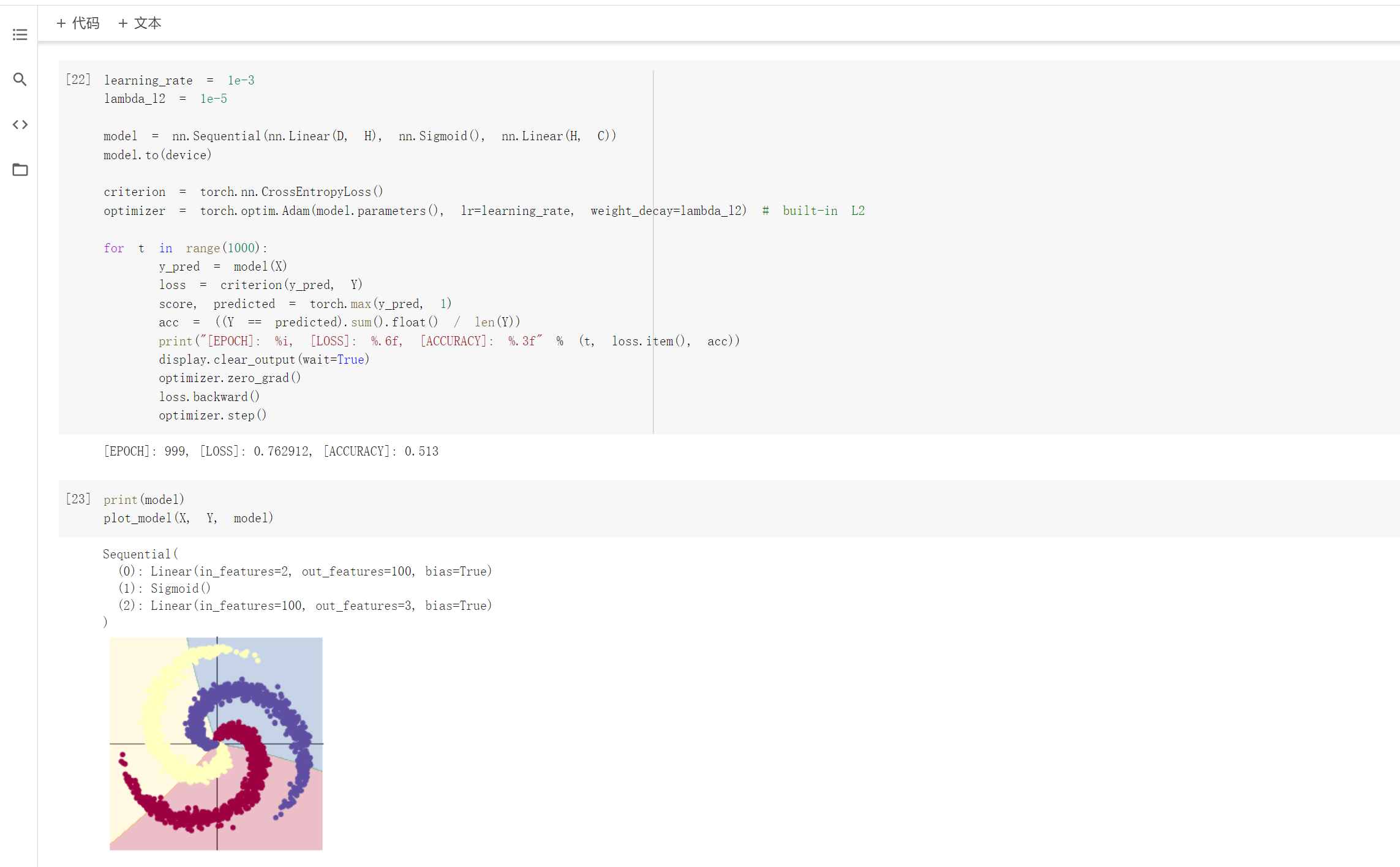
2.2 螺旋数据分类
想法和解读:
观察注释和代码发现,利用训练模型来数据分类是先将数据输入到模型中,得到预测结果,在将误差反向传播优化参数。而构建两层神经网络分类就是在上述线性模型的两层中加入激活函数,实现非线性转换。
此外,除了ReLU外,还测试了Tanh和sigmiod两个激活函数,发现ReLU和Tanh的效果都比较好,而sigmiod的效果不佳,推测是sigmoid函数梯度弥散的原因造成的,具体原因暂时不知道。