类别变量、独热编码
一组数据:
data = [
{'name':'张天','born':1996,'died':2077},
{'name':'李地','born':1986,'died':2067},
{'name':'吴中','born':1976,'died':2057}
]
其中born和died是数字,对于name要进行文本处理。直观的方式是给每个名字加上一个数字代码,{'张天':1,'李地':2,'吴中':3},这样使名字之间会有大小之分。对于类别变量,往往寻找二值编码,要么是,1,要么不是,0,在机器学习中称独热编码。
上述data的独热编码结果,列名中,对于value是字符串的数据,进行了一些拼接处理:
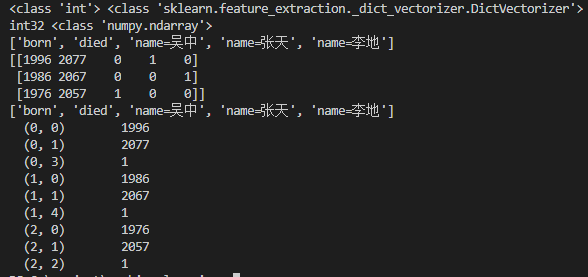
['born', 'died', 'name=吴中', 'name=张天', 'name=李地']
[[1996 2077 0 1 0]
[1986 2067 0 0 1]
[1976 2057 1 0 0]]
利用scikit-learn中的DictVectorizer转换为独热编码,以及系数矩阵的紧凑形式(三元组表示法):
from sklearn.feature_extraction import DictVectorizer
data = [
{'name':'张天','born':1996,'died':2077},
{'name':'李地','born':1986,'died':2067},
{'name':'吴中','born':1976,'died':2057}
]
# sparse=False 稀疏矩阵
vec = DictVectorizer(sparse=False, dtype=int)
# 将矢量化的字典转换成numpy.ndarray。转化后才能用get_feature_names()。
transdata = vec.fit_transform(data)
print(vec.dtype,type(vec))
print(transdata.dtype, type(transdata))
print(vec.get_feature_names())
print(transdata)
# sparse=True 稀疏矩阵的紧凑表示方法
vec2 = DictVectorizer(sparse=True, dtype=int)
transdata2 = vec2.fit_transform(data)
print(vec2.get_feature_names())
print(transdata2)
文本特征
处理文本特征时,较方便的方是用数字计数方式来表示单词或短语
from sklearn.feature_extraction.text import CountVectorizer
# data = ['一个','两个','三个'] 中文不太合适
data = ['feature engineering','feature selection','feature extraction feature']
vect = CountVectorizer()
# 计算逆文档频率TF-IDF
Ttransdata = vect.fit_transform(data)
print('Ttransdata:
',Ttransdata)
print('faeture name:
',vect.get_feature_names())
print('Ttransdata.toarray:
',Ttransdata.toarray())
out:
Ttransdata:
(0, 2) 1
(0, 0) 1
(1, 2) 1
(1, 3) 1
(2, 2) 2
(2, 1) 1
faeture name:
['engineering', 'extraction', 'feature', 'selection']
Ttransdata.toarray:
[[1 0 1 0]
[0 0 1 1]
[0 1 2 0]]
另一种,根据单词频率计算权重的技术为逆文档频率TF-IDF (term frequency-inverse document frequency)
from sklearn.feature_extraction.text import TfidfVectorizer
# data = ['一个','两个','三个'] 中文不太合适
data = ['feature engineering','feature selection','feature extraction feature']
vect = TfidfVectorizer()
# 计算逆文档频率TF-IDF
Ttransdata = vect.fit_transform(data)
print('Ttransdata:
',Ttransdata)
print('faeture name:
',vect.get_feature_names())
print('Ttransdata.toarray:
',Ttransdata.toarray())
out:
Ttransdata:
(0, 0) 0.8610369959439764
(0, 2) 0.5085423203783267
(1, 3) 0.8610369959439764
(1, 2) 0.5085423203783267
(2, 1) 0.6461289150464732
(2, 2) 0.7632282916276542
faeture name:
['engineering', 'extraction', 'feature', 'selection']
Ttransdata.toarray:
[[0.861037 0. 0.50854232 0. ]
[0. 0. 0.50854232 0.861037 ]
[0. 0.64612892 0.76322829 0. ]]
那么,这些东西有什么用呢?
两个医疗诊断的决策树构建-sklearn、python