
论文源址:https://arxiv.org/abs/1506.02640
tensorflow代码:https://github.com/nilboy/tensorflow-yolo
摘要
该文提出一种新的目标检测网络,yolo,以前的目标检测问题偏向于分类,而本文将目标检测看作是带有类别分数的回归问题。yolo从整张图上预测边界框和类别分数。是单阶段网络,可以进行端到端的训练。yolo处理速度十分迅速,每秒处理45帧图片。yolo在准确率上有待提升,但很少预测出假正的样例。
介绍
yolo的结构十分简洁,如下,一个单独的卷积网络,用于预测框的边界及每个框的类别概率 。相比传统的目标检测方式,yolo有以下几点优点:(1)速度十分快,可以适用于视频流的输入。(2)yolo对图片整体进行推理预测,而不是像基于窗口滑动的区域框的方式。由于yolo在训练和测试时是对整张图片进行分析,因此可以像编码外形信息一样对类别等抽象信息进行编码。Fast R-CNN有时会将背景误分类为目标,是因为不够多的上下文信息,而YoLo可以减少一般的这种错误情形。(3)YoLo学习的是整体的表示特征,对于新的输入,YoLOh还是有效的。
准确率上,YOLO仍有待提升,虽然速度快,但对目标尤其是小目标位置的精确定位相比最好的检测方法仍存在差距。

方法
本文应用整个图片的特征预测每个边界框。可以同时预测所有类别的边界框。Yolo对整个图片和图片中的目标进行分析,YoLO的设计可以在保持较高平均准确率的基础上实时的进行预测,同时,可以进行端到端的训练。
Yolo将输入图片分为大小为SxS的格子,如果目标的中心落在了格子里,则这个格子就负责该目标的检测任务。每个网格单元预测B个边界框及对应的分数,表示该单元包含目标物体的置信度confident,同时,输出预测类别的分数。将置信度定义如下,
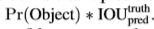
每个bounding box的预测5个值,(x,y,w,h)及confident,(x,y)为bounding box 的中心(相对于每个网格单元的偏移),预测出相对于整张图片的宽和高。
每个网格单元预测c个类别的条件概率,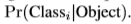 概率的计算的前提是,该网格单元包含目标物体。对于每个网格单元,不关预测出的B个bounding box,直接得到一系列类别的概率。
概率的计算的前提是,该网格单元包含目标物体。对于每个网格单元,不关预测出的B个bounding box,直接得到一系列类别的概率。
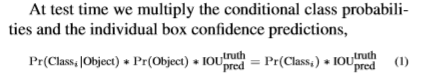
基于上式,可以得到每个框确定目标的confident 分数,同时,这个值也代表预测类别的准确率及预测框对目标物的符合程度。
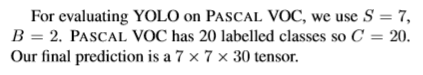
网络结构
模型为一个卷积网络,卷积层用于提取图像的特征,全连接层用于输出坐标和类别概率。该模型含有24层卷积层外加两层全连接层。结构如下
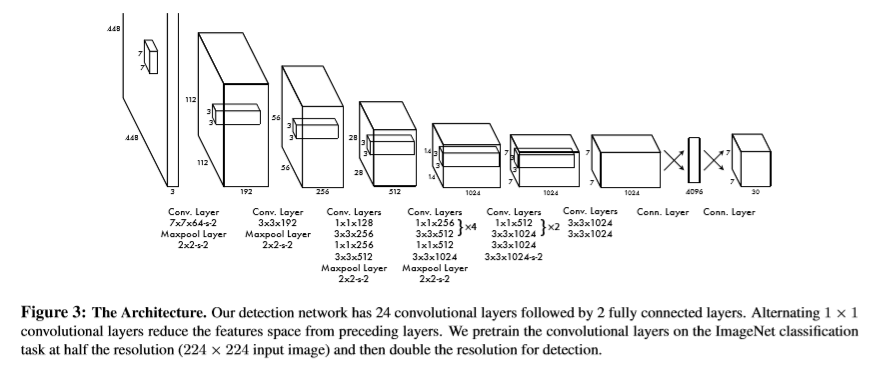
网络的训练
该文在ImageNet上预训练卷积网络,后增加4层卷积和两层全连接层,基于随机初始化操作。将预测框的宽和高用图片的原宽和高做归一化处理。将中心(x,y)作为单独网格单元的偏移量。本文对方差和误差进行优化处理,但由于参考了定位误差与类别误差,而许多bounding box中并未包含目标物,会使confidence变为0,从而对包含目标的检测误差的求导有影响,可能会导致收敛提前终止,进而 导致模型不稳定。
因此,本文增加了预测框损失的权重,而减少不包含目标的预测框损失的权重。在和平方误差中,大框和小框的误差权重是相同的。相比大框下的小偏差,小框的小偏差影响是较大的。因此,将预测边界框宽和高的平方根,而不是其直接得到的宽和高。

yolo对每个网格单元预测多个边界框,但训练时,只希望针对每个目标物体得到一个边界框预测器。该文将预测出的bounding box与ground truth IOU值最高的作为此目标的预测器。本文优化的损失函数如下:

注意:只惩罚存在目标的网格单元的类别损失和对应负责检测目标边界框预测器的框损失函数,原文如下。

为防止过拟合,本文采用dropout和数据增强操作。
yolo的限制因素
yolo对增强了预测框的空间限制,因为,每个网格单元只能预测两个边界框,及一个类别,因此,yolo对相邻目标的检测有点难度,像鸟群等小目标的检测。yolo直接从数据中学习并预测边界框,对非正常宽高比的物体检测效果不是很好,yolo网络中包含很多下采样层,对特征的学习不是很精细,对检测结果造成一定影响。对于损失函数,大物体与小物体的IOU对损失的贡献度相差不大,对于小物体,很小的IOU也会对网络造成很大影响,影响检测的结果。
实验
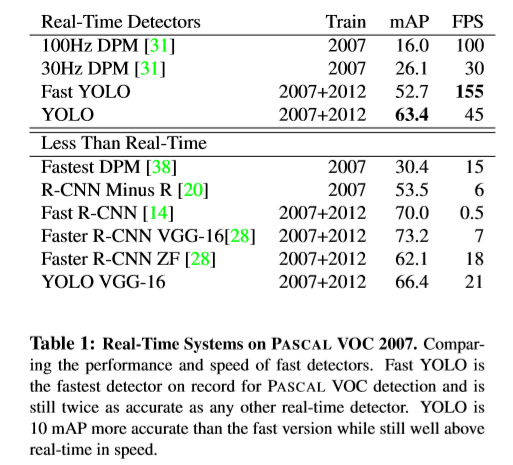
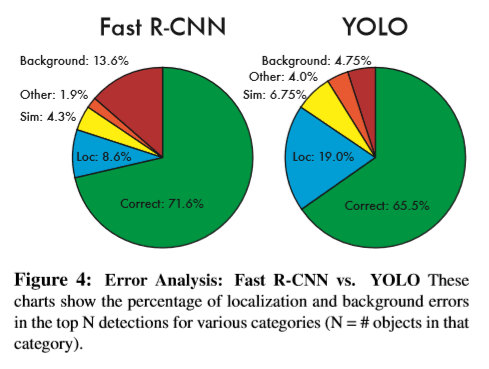
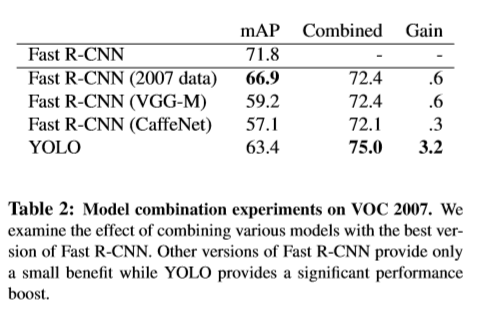
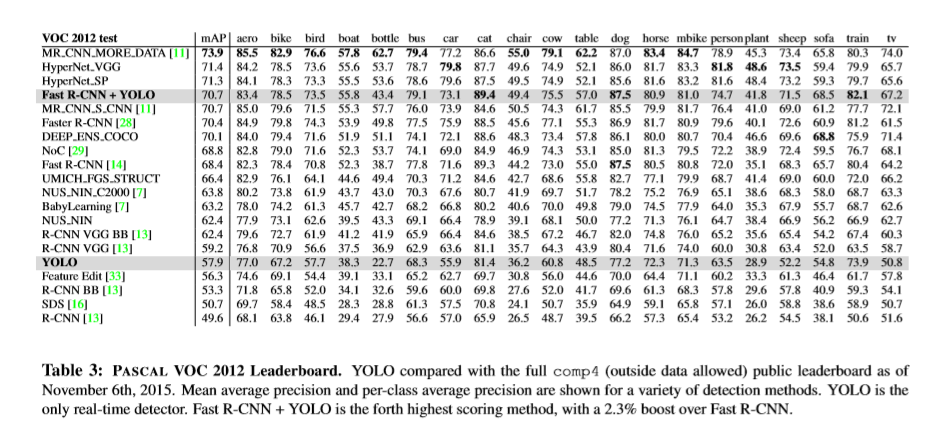

参考
[1] M. B. Blaschko and C. H. Lampert. Learning to localize objects with structured output regression. In Computer Vision– ECCV 2008, pages 2–15. Springer, 2008. 4
[2] L. Bourdev and J. Malik. Poselets: Body part detectors trained using 3d human pose annotations. In International Conference on Computer Vision (ICCV), 2009. 8
[3] H. Cai, Q. Wu, T. Corradi, and P. Hall. The crossdepiction problem: Computer vision algorithms for recognising objects in artwork and in photographs. arXiv preprint arXiv:1505.00110, 2015. 7