一、创建goroutine
1)在go语言中,每一个并发的执行单元叫做一个goroutine;
2)当一个程序启动时,其主函数即在一个单独的goroutine中运行,一般这个goroutine是主goroutine;如果想要创建新的goroutine,只需要再执行普通函数或者方法的的前面加上关键字go。
3)go是如何实现一个多线程程序?
go语言中很简单,加一个go关键字即可,就变成了一个多线程程序(一个进程跑多个线程)
下面通过一个完整实例来了解一下goroutine:
实例1-1 实例1
1)未加go关键字;
package main import ( "fmt" ) func hello() { fmt.Printf("hello ") } func main() { hello() fmt.Printf("main exited") }
执行结果如下图所示:

解释:
可以发现hello函数和main函数是同一个线程串行执行,先输出hello,在输出main exited
2) 加上go关键字;
package main import ( "fmt" ) func hello() { fmt.Printf("hello ") } func main() { go hello() fmt.Printf("main exited") }
执行结果如下:

解释:
加上go关键字后,可以发现hello函数还未执行,程序就退出了。
hello函数加上go关键字后,可以发现其不再是和main函数同步的执行(串行)了,应该是并发执行了,hello函数相当于是新起了一个线程,和main函数这个线程是独立的,一共是两个线程在执行;
在go语言中,以main函数所运行的主线程为准,如果main函数线程(主线程)执行完毕,还有其他线程(附属主线程的子线程)在执行,这些未执行完毕的线程也会被强制关闭。(main函数所在的主线程一旦退出,就相当于整个进程退出,进程一退出,这个进程中的其他线程也会被强制关闭退出)
针对我们这个实例:其实就是main函数所在的主线程已经执行完毕了,hello函数所在的线程效率没有main函数所在的主线程高,所以输出结果没有hello函数的内容。
3) 加上go关键字完整版代码;
package main import ( "fmt" "time" ) func hello() { fmt.Printf("hello ") } func main() { go hello() time.Sleep(1 * time.Second) //通过睡1秒,保证hello函数所在线程执行 fmt.Printf("main exited") }
执行结果如下图所示:

解释:
通过sleep 1秒,hello函数所在线程得以执行完毕。
实例1-2 实例2
1)不加go关键字
package main import ( "fmt" "time" ) func hello() { for i := 0; i < 4; i++ { fmt.Printf("hello:%d ", i) time.Sleep(time.Millisecond * 10) } } func main() { hello() for i := 0; i < 4; i++ { fmt.Printf("main:%d ", i) time.Sleep(time.Millisecond * 10) } time.Sleep(time.Second) }
执行结果如下图所示:

解释:
可以看到不加go关键字,是串行执行。
2)加上go关键字
package main import ( "fmt" "time" ) func hello() { for i := 0; i < 4; i++ { fmt.Printf("hello:%d ", i) time.Sleep(time.Millisecond * 10) } } func main() { go hello() for i := 0; i < 4; i++ { fmt.Printf("main:%d ", i) time.Sleep(time.Millisecond * 10) } time.Sleep(time.Second) }
执行结果如下图所示:
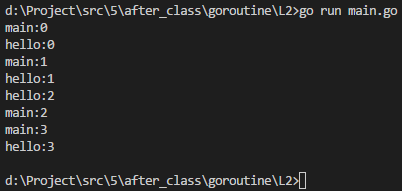
解释:
通过打印结果可以看到hello函数所在的线程和main函数所在的主线程是并行执行的。
二、创建多个goroutine
实例如下:
package main import ( "fmt" "time" ) func numbers() { for i := 1; i <= 5; i++ { time.Sleep(250 * time.Millisecond) //每隔250ms打印一个整数 fmt.Printf("%d ", i) } } func alphabets() { for i := 'a'; i <= 'e'; i++ { //字符的底层也是一个整数 time.Sleep(400 * time.Millisecond) //每隔400ms打印一个字母 fmt.Printf("%c ", i) } } func main() { go numbers() go alphabets() time.Sleep(3000 * time.Millisecond) //主线程等待3秒在退出 fmt.Println("main terminated") }
执行结果如下:

解释:
根据输出结果,可以看到numbers函数、alphabets函数所在的线程是并行执行的。
(补充:numbers函数、alphabets函数都是新起一个线程,至于哪个线程先启动,这是不一定的,不是说number函数在前,其的就先启动,具体看cpu的调度策略的)
三、进程和线程
1)进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的
一个独立单位。
2)线程是进程的一个执行实体,是CPU调度和分派的基本单位,它是比进程更
小的能独立运行的基本单位。
3)一个进程可以创建和撤销多个线程;同一个进程中的多个线程之间可以并发
执行
图示:

四、并发和并行
1)多线程程序在一个核的cpu上运行,就是并发
2)多线程程序在多个核的cpu上运行,就是并行
图示:

解释:
左图(单核)为并发,右图(多核)为并行。
x轴为时间轴,左图并发,同一时间段只能有一个程序在执行,右图并行,同一时间段内可以有多个程序执行。
五、协程和线程
协程:
独立的栈空间,共享堆空间,调度由用户自己控制,本质上有点类似于
用户级线程,这些用户级线程的调度也是自己实现的
线程:
线程是操作系统起的,由操作系统进行管理;
一个线程上可以跑多个协程,协程是轻量级的线程。
葵花宝典:
操作系统起的线程有一个问题:
操作系统就是内核,操作系统起的线程执行在内核态,用户的程序应用运行在用户态,这是两个不同的形态,如果我们是创建线程的话,线程是操作系统在管理,如果我们在应用程序中创建线程,线程之间要进行切换的话,就需要进入内核态去进行切换,因为这个线程是内核去控制管理的,如果在一个应用程序中创建了几千个线程,这样线程之间的切换每次都要从用户态到内核态去切换,上下文切换比较频繁,用户态到内核态切换是需要消耗资源的,最终的结果就是,上千个线程,上下文切换会造成系统变得非常缓慢,这也是线程的一个缺点,这也是其他语言的缺点,跑几千个线程就跑不动了,所以其他语言是需要搞一个线程池。
但是在go语言的话,go语言已经帮助我们解决了上述问题,协程是用户态的一个概念,协程和操作系统的线程是两回事,一个操作系统的线程可能执行多个协程,协程是go语言帮我们抽象出来的一个东西,可以发现,协程之间的切换不用和内核态去做一个相互切换,仅仅只在用户态进行切换(线程是需要内核来进行控制切换)。用户态切换要比到内核态进行切换性能要高非常多,所以,go语言中,起上千个协程是完全没有问题的,上万个都没问题(起上万个协程的话,对应的可能就是操作系统的几十个线程)。所以说在go语言中,完全不用担心起上千个线程会影响系统,特别是在高并发领域http服务,基本上都是来一个请求,就会起一个协程的。这样你同时有几万个并发请求过来,就有几万个goroutine再跑,这个性能是非常高的。(nginx并不是每一个请求起一个线程,而是通过异步进行处理,一个线程异步的处理多个请求,这对go来说,写一个高并发程序太简单了。http、tcp服务,来一个请求起一个goroutine即可。)
六、goroutine调度模型
图示1:

解释:
M是操作系统的线程,P是一个上下文,G是goroutine
图示2:

解释:
1)goroutine必须要有上下文才会执行,左边蓝色的可以看见已经有一个goroutine在执行了,右边灰色的是等待被执行的goroutine,一个物理线程可以执行多个goroutine,一个goroutine执行完,下一个等待的goroutine被执行,这其实就是go语言中的一个线程调度情况。
2)比如说一个正在执行的goroutine,其需要暂停,这个时候就要做一个上下文切换(语句执行到哪里等的上下文要保存起来)
3)目前上图情况是:一个程序跑了两个物理线程,一个物理线程跑多个goroutine
图示3:

解释:
M0(物理线程)跑了一个G0(goroutine),同时还有3个goroutine在等待执行,当G0有IO操作或者有网络操作时,此时要进行一个写文件操作,写文件是一个慢操作,磁盘和内存写数据速度相差很多倍(磁盘写文件5ms,内存读数据不到1微妙),此时我们花5ms去同步等待时,cpu的资源就浪费了,这种情况的,发现G0是做IO操作的话,就会把G0和M0给剥离出来,然后会新建一个线程M1,接着执行后面的goroutine。
注意:
go语言:一个cpu同一时间一个线程只能跑一个goroutine,其牛逼的地方在于减少了用户态和内核态的切换。
七、设置golang运行的cpu核数
1、主要借助的是runtime包的NumCPU函数;
2、可以通过runtime包中的GOMAXPROCS函数来控制使用cpu的个数;
3、新版本默认跑满所有cpu个数
注意:
在golang1.6版本之前,goroutine程序默认只能跑在1个cpu上,如果要想多核跑的话,就需要利用GOMAXPROCS函数来控制CPU核数,新版本目前是不用设置了,默认是将计算机所有cpu核数跑满。
实例:
我们下面通过一个实例来对比一下:
1)限制使用的cpu核数为1
package main import ( "fmt" "runtime" "time" ) func main() { cpu := runtime.NumCPU() runtime.GOMAXPROCS(1) //只限制使用cpu的1个核 for i := 0; i < 8; i++ { //起8个goroutine,每个goroutine来跑一个无限循环的匿名函数 go func() { for { } }() } fmt.Printf("%d ", cpu) time.Sleep(15 * time.Second) }
执行结果:

CPU示意图:

我们可以发现cpu是没有跑满的,达到了预计效果。
2) 不限制cpu的使用核数
package main import ( "fmt" "runtime" "time" ) func main() { cpu := runtime.NumCPU() //不限制CPU使用个数 for i := 0; i < 8; i++ { //起8个goroutine,每个goroutine来跑一个无限循环的匿名函数 go func() { for { } }() } fmt.Printf("%d ", cpu) time.Sleep(15 * time.Second) }
执行结果:

CPU示意图:
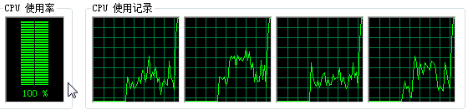
我们可以发现CPU已将完全跑满了。
总结:
我们日后使用时,如果只是一个监控、收集日志小程序,要适当控制一下CPU使用个数,如果不控制的话,程序出现bug,而且把机器核数也跑满了,最后连业务程序也跑不了了。