1、存储过程的介绍
对于存储过程,可以接收参数,其参数有三类:
in 仅用于传入参数用
out 仅用于返回值用
inout 既可以传入又可以当作返回值
存储过程包含了一系列可执行的sql语句,存储过程存放于MySQL中,通过调用它的名字可以执行其内部的一堆sql。 优点: 1. 用于替代程序写的SQL语句,实现程序与sql解耦 2. 基于网络传输,传别名的数据量小,而直接传sql数据量大 缺点: 1. 程序员扩展功能不方便 补充: 程序与数据库结合使用的三种方式 #方式一: MySQL:存储过程 程序:调用存储过程 评论: 应用程序与数据库解开耦合,效率高,发存储过程名就可以了, 但是实际情况:扩展性低,人为因素造成得! #方式二: MySQL: 程序:纯SQL语句 评论: 通常用这种方式,运行效率低一些,但扩展性方便。 #方式三: MySQL: 程序:类和对象,即ORM(本质还是纯SQL语句),Django框架里面有ORM框架,本质:应用程序控制sql 评论: 运行效率低,相比方式二,因为要转换,发送。 开发效率高,面向对象,可维护性高。
2、准备表
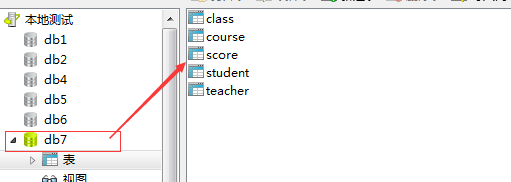
创建存储过程
无参数存储过程
#1、无参存储过程 delimiter // create procedure p1() BEGIN select * from db7.teacher; END // delimiter ; # MySQL中调用 call p1(); # Python中调用 cursor.callproc('p1')
# 在MySQL中调用

删除创建的存储过程:

在pycharm开发环境中调用

((1, '张磊老师'), (2, '李平老师'), (3, '刘海燕老师'), (4, '朱云海老师'), (5, '李杰老师'))
有参数存储过程
#2、有参存储过程 in n1 int,in n2 int,out res int in 指的是传入参数 out 指的是传出参数 delimiter // create procedure p2(in n1 int,in n2 int,out res int) BEGIN select * from db7.teacher where tid > n1 and tid < n2; set res = 1; END // delimiter ; # MySQL中调用 # 设定初始值 set @x=0 call p2(2,4,@x); select @x; # Python中调用 cursor.callproc('p2',(2,4,0))# @_p2_0=2,@_p2_1=4,@_p2_2=0 cursor.execute('select @_p3_2') cursor.fetchone()
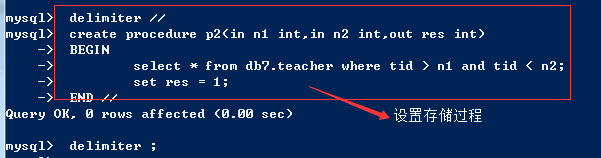
# MySQL中调用# 设定初始值


在pycharm开发环境中
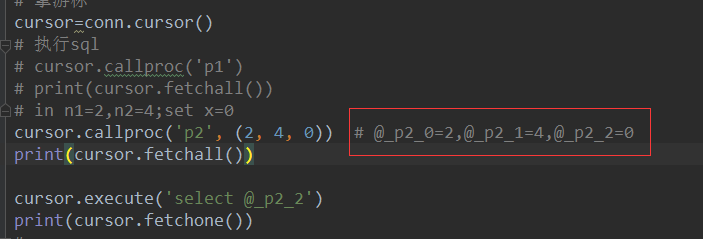
((3, '刘海燕老师'),) (1,)