1.数组
int [] arr=new int[数组长度]
java中数组是引用类型,因此需要用new关键字声明内存
数组越界会产生ArrayIndexOutOfBoundsException
for each遍历数组
for(int item:arr){
System.out.println(e);
}
2.多维数组
int a[][]=new int[3][4]; //可以是规则的
int b[][]=new int[3][];
b[0]=new int[3];
b[1]=new int[4];
b[2]=new int [5]; //也可以是不规则的
3.JCF
JCF:java collection framwork
JCF主要的数据结构实现类:
列表:List、Vector、ArrayList、LinkedList
集合:Set、HashSet、TreeSet、LinkedHashSet
映射:Map、HashMap、TreeMap、LinkedHashMap
两个常用的工具类:Arrays、Collections,提供了一些常用查找和排序的算法
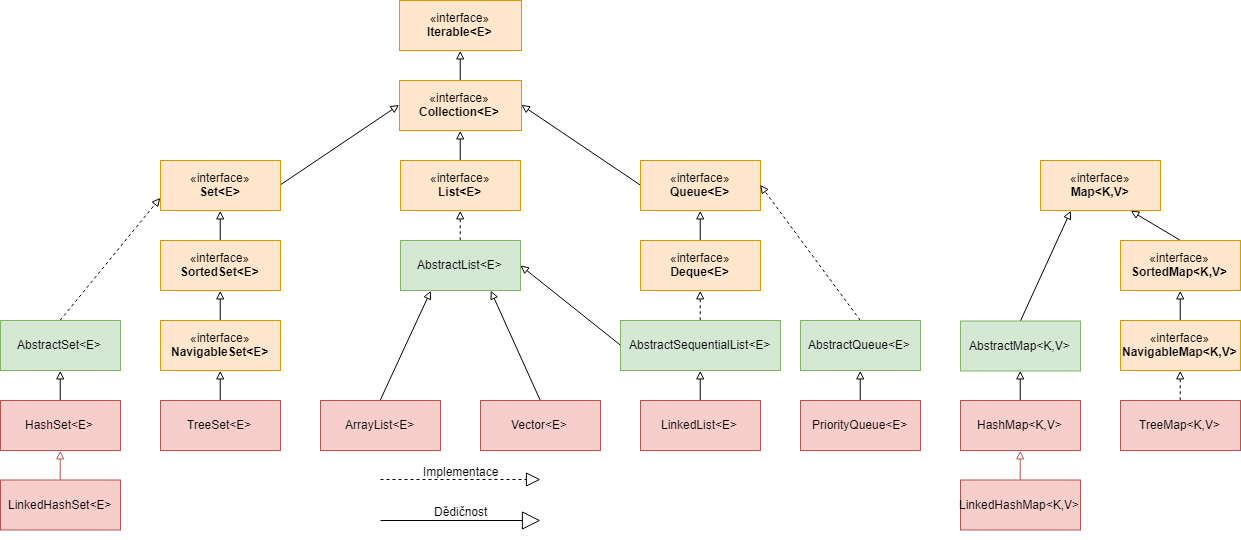
4.列表List
List:
有序的Collection
允许重复的元素
元素可以支持不同类型的
List的主要实现
ArrayList(非同步的)
LinkedList(非同步的)
Vector(同步的)
ArrayList:
与普通数组相比,ArrayList的大小可以动态调整,容器填满时,自动扩容50%
和普通数组一样,ArrayList不适合指定位置的插入和删除。主要用于存储查询数据。
遍历方式:
1)ArrayList.iterator会返回一个迭代器,通过这个迭代器的hasNext和next方法来遍历元素
2)for循环
3)for each循环(这种方式最快)
LinkedList:
以双向链表实现的列表,不支持同步
可以被用作堆栈、队列和双端队列进行操作
插入和删除比较高效,随机访问速度很慢,适用于经常变化的数据
遍历方式:
1)ArrayList.iterator会返回一个迭代器,通过这个迭代器的hasNext和next方法来遍历元素
2)for循环,不支持直接存取,但是可以用get(index)方法来找第index位置的元素,底层还是顺序查找(这种方式超级慢)
3)for each循环(这种方式最快)
Vector:
适合在多线程下使用,和ArrayList几乎一样
性能较差,在非同步的情况下,建议使用ArrayList
遍历方式:
与ArrayList相比多了一种Enumeration,通过Vector的elements()方法可以返回一个Enumeration对象,通过Enumeration对象的nextElement方法可以遍历。
不建议使用Enumeration方法遍历,推荐for each。
5.Set
集合Set:
确定性:对任意的对象都能判定其是否属于某一个集合
互异性:集合内的每个元素都是不相同的
无序性:集合内的元素顺序不确定
java中的集合类:
HashSet(基于散列函数的集合,无序,不支持同步)
TreeSet(基于树结构的集合,可排序的,不支持同步)
LinkedHashSet(基于散列函数和双向链表的集合,可排序的,不支持同步)
HashSet:
基于HashMap实现,可以容纳null元素,不支持同步
想要同步可以Set s=Collections.synchronizedSet(new HashSet(...));
常用方法add、clear、contains、remove、retainAll(计算两个集合交集)
判定元素是否相同:先比较两个元素的hashCode返回值是否相同,若相同进一步判断equals方法的返回值是否相同,若仍相同,则这两个元素相同,只保留一个
遍历方法:
for each(更快)
iterator
LinkedHashSet:
继承HashSet,也是基于HashMap实现,可以容纳null元素,不支持同步
方法和HashSet基本一致
与HashSet最大的区别:通过双向链表来维护插入顺序(插入顺序是保留的)
判定元素是否相同:先比较两个元素的hashCode返回值是否相同,若相同进一步判断equals方法的返回值是否相同,若仍相同,则这两个元素相同,只保留一个
TreeSet:
基于TreeMap实现,不可以容纳null元素,不支持同步
方法和上述两种基本一致
根据compareTo方法或者指定Comparator排序,添加到TreeSet中的元素,必须已经实现了Compareable接口的compareTo方法
遍历方法和上述两种一样。
判定元素是否相同:需要元素继承Comparable接口,比较两个元素的compareTo方法
6.Map
Map:存储键值对
java中的Map:
Hashtable:同步,慢,数据量小
HashMap:不支持同步,快,数据量大
Properties:同步,文件形式,数据量小
Hashtable:
K-V都不允许为null
无序的
主要方法:clear,contains/containsValue(这两个一样),containsKey,get,put,remove,size
遍历方法:
Iterator<Entry<,>> iter=hashtable.entrySet().iterator; //.entrySet()方法会返回一个set
根据key的iterator迭代器遍历,先用keySet()方法返回keyset,然后通过keyset的iterator方法返回迭代器,最后通过get(iter.next())来得到值
HashMap:
K-V都允许为null
方法和Hashtable类似,遍历方法也一样
LinkedHashMap:
基于双向链表的维持插入顺序的hashmap,即遍历会按照插入顺序进行遍历
TreeMap:
基于红黑树的Map,可以根据key的自然排序或者compareTo方法进行排序输出
Properties:
继承于Hashtable,可以将K-V对保存在文件当中
适合数据量少的配置文件
方法和Hashtable类似,额外方法:
load:从文件中提取K-V对
store:将K-V对存入文件
getProperty:获取属性
setProperty:设置属性
7.工具类Collections和Arrays
Arrays:处理对象是数组
排序,sort/parallelSort
查找:binarySearch
批量拷贝:copyOf
批量赋值:fill
等价性比较,equals.判断两个数组内容是否相同
Collections:处理的对象是Collection及其子类
排序:sort
搜索:binarySearch
批量赋值:fill
最大最小:max,min
反序:reverse
8.Comparable接口
四大接口之一,接口中只有compareTo方法
大于 返回1,小于返回-1,等于返回0
Arrays和Collections在进行对象sort时,会自动调用该方法
Comparator接口适用于对象类不可更改的时候
改接口中的compare方法可以用户自定义
然后Comparator比较器可以作为参数传递给sort方法