项目简介
爬取趣头条新闻(http://home.qutoutiao.net/pages/home.html),具体内容:1、列表页(json):标题,简介、封面图、来源、发布时间
2、详情页(html):详细内容和图片
目录结构
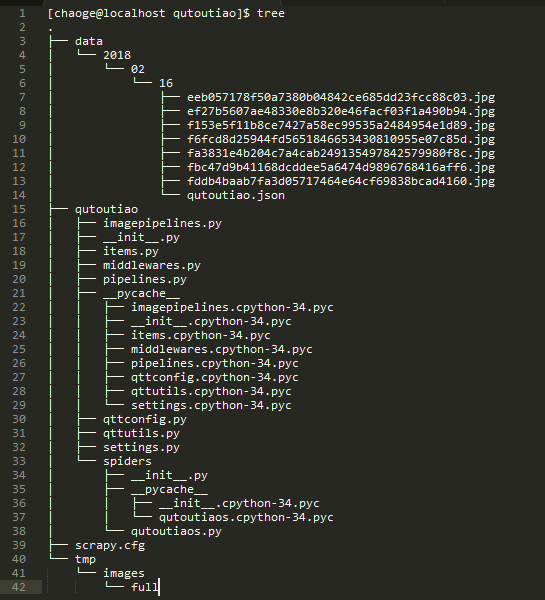
生成的数据文件-单条记录

主要代码说明
爬虫:#爬取趣头条列表和详情页
qutoutiao.spiders.qutoutiaos.QutoutiaosSpider
管道文件:
#封面图片处理类
qutoutiao.imagepipelines.CoverImagePipeline
#内容图片处理类
qutoutiao.imagepipelines.ContentImagePipeline
#数据处理类
qutoutiao.pipelines.QutoutiaoPipeline
中间件:
#请求头设置类-这里只设置了user agent
qutoutiao.middlewares.RandomUserAgent
#代理设置类
qutoutiao.middlewares.RandomProxy
自定义:
#配置文件
qutoutiao.qttconfig.py
#工具类
qutoutiao.qttutils.QttUtils
创建项目
cd /home/chaoge/mypython/crawler/scrapy startproject qutoutiao
创建爬虫类即(qutoutiao.spiders.qutoutiaos.QutoutiaosSpider)
cd qutoutiao/qutoutiao/spidersscrapy genspider qutoutiaos "api.1sapp.com"
执行
scrapy crawl qutoutiaos
#scrapy crawl qutoutiaos --nolog#不显示log
#scrapy crawl qutoutiaos -o qutoutiaos_log.json #将log输出到qutoutiaos_log.json
代码实现
qutoutiao.qttconfig.py# 爬取域名(趣头条)
DOMAIN = 'http://home.qutoutiao.net/pages/home.html'
#数据存储路径
DATA_STORE = '/home/chaoge/mypython/crawler/qutoutiao/data'
#列表:http://api.1sapp.com/content/outList?cid=255&tn=1&page=1&limit=10
#列表API
LIST_API = 'http://api.1sapp.com/content/outList?'
#列表记录数
LIST_LIMIT = 10
#分类
CATEGORY_INFO = [
{"cid":255,"name":"推荐"},
{"cid":1,"name":"热点"},
{"cid":6,"name":"娱乐"},
{"cid":5,"name":"养生"},
{"cid":2,"name":"搞笑"},
{"cid":7,"name":"科技"},
{"cid":8,"name":"生活"},
{"cid":10,"name":"财经"},
{"cid":9,"name":"汽车"},
]qutoutiao.qttutils.py
# -*- coding: utf-8 -*-
# 趣头条工具类
import time
import os
import shutil
from qutoutiao import qttconfig as QttConfig
class QttUtils:
# 获取存储路径
#
# @param [string] action [remove删除目录,默认create]
# @return [string] path/year/month/day/*
@staticmethod
def getStorePath(action='create'):
localtimes = time.localtime()
year = time.strftime("%Y", localtimes)
month = time.strftime("%m", localtimes)
day = time.strftime("%d", localtimes)
store_path = QttConfig.DATA_STORE+"/%s/%s/%s"%(year,month,day)
#删除目录
if os.path.exists(store_path) and action == 'remove':
#os.rmdir(store_path)
shutil.rmtree(store_path)
#创建多级目录
if not os.path.exists(store_path) and action == 'create':
os.makedirs(store_path)
return store_pathqutoutiao.settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for qutoutiao project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'qutoutiao'
SPIDER_MODULES = ['qutoutiao.spiders']
NEWSPIDER_MODULE = 'qutoutiao.spiders'
#日志
#LOG_FILE = "qutoutiao.log"
#日志等级
#LOG_LEVEL = "DEBUG"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'qutoutiao (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36',
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
SPIDER_MIDDLEWARES = {
# 'qutoutiao.middlewares.QutoutiaoSpiderMiddleware': 543,
'scrapy.contrib.spidermiddleware.offsite.OffsiteMiddleware': None,#spider中的allowed_domains将不受限制
}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'qutoutiao.middlewares.RandomUserAgent': 100,
'qutoutiao.middlewares.RandomProxy': 200,
}
#中间件中的UserAgent池
USER_AGENTS = [
'User-Agent:Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'User-Agent:Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0',
'User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko',
'User-Agent:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;',
'User-Agent:Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11',
'User-Agent:Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16',
]
#中间件中的Proxy池
PROXIES = [
{'ip_port':'121.42.140.113:16816','user_password':'username-xxxx:password-xxxx'},
{'ip_port':'117.90.137.181:9000'},
{'ip_port':'117.90.2.151:9000'},
{'ip_port':'114.235.23.147:9000'},
]
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'qutoutiao.imagepipelines.CoverImagePipeline': 301,#封面图片下载
'qutoutiao.imagepipelines.ContentImagePipeline': 302,#内容图片下载
'qutoutiao.pipelines.QutoutiaoPipeline': 400,#数据处理
}
#图片存储路径
IMAGES_STORE = "/home/chaoge/mypython/crawler/qutoutiao/tmp/images"
#缩图设置
#IMAGES_THUMBS = {
# 'small':(50,50),
# 'big':(270,270),
#}
#图片宽和高在110*110以下忽略
IMAGE_MIN_HEIGHT = 110
IMAGE_MIN_WIDTH = 110
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'qutoutiao.items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class QutoutiaoItem(scrapy.Item): # define the fields for your item here like: #文章id aid = scrapy.Field() #来源 source_name = scrapy.Field() #标题 title = scrapy.Field() #详细页url url = scrapy.Field() #简介 introduction = scrapy.Field() #封面图 cover = scrapy.Field() #发布时间 publish_time = scrapy.Field() #分类ID cid = scrapy.Field() #内容 content = scrapy.Field() #内容-中的图片 content_images = scrapy.Field()
qutoutiao.middlewares.py
# -*- coding: utf-8 -*-
import random
import base64
from settings import USER_AGENTS
from settings import PROXIES
#随机User-Agent
class RandomUserAgent(object):
def process_request(self,request,spider):
useragent = random.choice(USER_AGENTS)
request.headers.setdefault('User-Agent',useragent)
#request.headers.setdefault('Host','html2.qktoutiao.com')
#request.headers.setdefault('Referer','http://home.qutoutiao.net/pages/home.html')
#随机代理
class RandomProxy(object):
def process_request(self,request,spider):
proxy = random.choice(PROXIES)
request.meta['proxy'] = 'http://'+proxy['ip_port']
#base64_user_password = base64.b64encode(bytes(proxy['user_password'], 'utf-8'))
#decodebs64 = base64.b64decode(base64_user_password)
#print(base64_user_password,decodebs64)
if 'user_password' in proxy and proxy['user_password']:#需要用户名密码的代理
base64_user_password = str(base64.b64encode(bytes(proxy['user_password'], 'utf-8')))
request.headers['Proxy-Authorization'] = 'Basic '+base64_user_passwordqutoutiao.imagepipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import scrapy
from scrapy.utils.project import get_project_settings
from scrapy.pipelines.images import ImagesPipeline
import os
from qutoutiao.qttutils import QttUtils
#封面图下载
class CoverImagePipeline(ImagesPipeline):
#获取settings中的常量
IMAGES_STORE = get_project_settings().get('IMAGES_STORE')
#下载图片
def get_media_requests(self, item, info):
cover_images = item['cover']
if cover_images:
for image_url in cover_images:
yield scrapy.Request(url=image_url)
#下载完成
def item_completed(self, results, item, info):
#print('*'*20,results,item,info)
image_path = [x['path'] for ok, x in results if ok]
#获取自定义存储路径
store_path = QttUtils.getStorePath()
coverImages = []
#将图片移动到新的路径
if image_path:
for image_url in image_path:
file_name = os.path.split(str(image_url))
new_image = store_path+"/"+file_name[1]
coverImages.append(new_image)
os.rename(self.IMAGES_STORE+"/"+image_url,new_image)
item['cover'] = coverImages
return item
#内容图片下载
class ContentImagePipeline(ImagesPipeline):
#获取settings中的常量
IMAGES_STORE = get_project_settings().get('IMAGES_STORE')
#下载图片
def get_media_requests(self, item, info):
content_images = item['content_images']
if content_images:
for image_url in content_images:
yield scrapy.Request(image_url)
#下载完成
def item_completed(self, results, item, info):
image_info = [(x['path'],x['url']) for ok, x in results if ok]
#获取自定义存储路径
store_path = QttUtils.getStorePath()
contentImages = []
#将图片移动到新的路径
if image_info:
for value in image_info:
image_url = value[0]
image_source = value[1]
file_name = os.path.split(str(image_url))
new_image = store_path+"/"+file_name[1]
contentImages.append((new_image,image_source))
os.rename(self.IMAGES_STORE+"/"+image_url,new_image)
item['content_images'] = contentImages
return itemqutoutiao.pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
from qutoutiao.qttutils import QttUtils
class QutoutiaoPipeline(object):
def __init__(self):
#获取自定义存储路径
store_path = QttUtils.getStorePath()
json_path = store_path+"/"+"qutoutiao.json"
self.filename = open(json_path,"wb")
def process_item(self, item, spider):
text = json.dumps(dict(item),ensure_ascii=False)+"
"
self.filename.write(text.encode("utf-8"))
return item
def close_spider(self,spider):
self.filename.close()qutoutiao.spiders.qutoutiaos.py
# -*- coding: utf-8 -*-
#web site:http://home.qutoutiao.net/pages/home.html
import scrapy
#通过CrawlSpider,Rule类爬取
#-*-from scrapy.spiders import CrawlSpider,Rule-*-
#-*-from scrapy.linkextractors import LinkExtractor-*-
from qutoutiao.items import QutoutiaoItem
import json
import re
from qutoutiao import qttconfig as QttConfig
#-*-class QutoutiaosSpider(CrawlSpider):-*-
class QutoutiaosSpider(scrapy.Spider):
name = 'qutoutiaos'
allowed_domains = ['api.1sapp.com']
#爬取地址
start_urls = []
categoryInfo = QttConfig.CATEGORY_INFO
limit = QttConfig.LIST_LIMIT
for value in categoryInfo:
url = QttConfig.LIST_API+"cid=%s&tn=1&page=1&limit=%s"%(str(value['cid']),str(limit))
start_urls.append(url)
#response里链接的提取规则
# -*-pageLink = LinkExtractor(allow=("start=d+"))-*-
# -*-rules = [
# -*- #用pageLink提取规则跟进,通过parseQtt进行解析
# -*- Rule(pageLink,callback="parseQtt",follow=True)
# -*-]
def parse(self, response):
response_url = response.url
#分类id从url又获取了一次
searchObj = re.search( r'(.*)cid=(d+)', response_url)
cid = searchObj and searchObj.group(2) or 0
data = json.loads(response.text)['data']['data']
for value in data:
#初始化模型对象
item = QutoutiaoItem()
#来源
item['source_name'] = value['source_name']
#标题
item['title'] = value['title']
#详细页url
url = item['url'] = value['url']
#url = url[0:url.find('?')]
#简介
item['introduction'] = value['introduction']
#封面图
item['cover'] = value['cover']
#发布时间
item['publish_time'] = value['publish_time']
#分类
item['cid'] = cid
#爬取详情页
yield scrapy.Request( url = item['url'], meta={'meta_item': item}, callback=self.detail_parse)
#详情页
def detail_parse(self, response):
# 提取每次Response的meta数据
meta_item = response.meta['meta_item']
#取内容
content_selector = response.xpath('//div[@class="content"]')
meta_item['content_images'] = content_selector.xpath('//img/@src|//img/@data-src').extract()
meta_item['content'] = content_selector.extract()[0]
yield meta_item