最近在研究jstorm,看了很多资料,所以也想分享出来一些。
安装部署
zeromq
简单快速的传输层框架,安装如下:
wget http://download.zeromq.org/zeromq-2.1.7.tar.gz
tar zxf zeromq-2.1.7.tar.gz
cd zeromq-2.1.7
./configure
make
sudo make install
sudo ldconfig
jzmq
应该是zmq的java包吧,安装步骤如下:
git clone git://github.com/nathanmarz/jzmq.git
cd jzmq
./autogen.sh
./configure
make
make install
zookeeper
针对大型分布式系统提供配置维护、名字服务、分布式同步、组服务等,可以保证:
- 顺序性:客户端的更新请求都会被顺序处理
- 原子性:更新操作要不成功,要不失败
- 一致性:客户端不论连接到那个服务端,展现给它的都是同一个视图
- 可靠性:更新会被持久化
- 实时性:对于每个客户端他的系统视图都是最新的
在zookeeper中有几种角色:
- Leader:发起投票和决议,更新系统状态
- Follower:响应客户端请求,参与投票
- Observer:不参与投票,只同步Leader状态
- Client:发起请求
在启动之前需要在conf下编写zoo.cfg配置文件,里面的内容包括:
- tickTime:心跳间隔
- initLimit:Follower和Leader之间建立连接的最大心跳数
- syncLimit:Follower和Leader之间通信时限
- dataDir:数据目录
- dataLogDir:日志目录
- minSessionTimeout:最小会话时间(默认tickTime * 2)
- maxSessionTimeout:最大会话时间(默认tickTime * 20)
- maxClientCnxns:客户端数量
- clientPort:监听客户端连接的端口
- server.N=YYYY:A:B:其中N为服务器编号,YYYY是服务器的IP地址,A是Leader和Follower通信端口,B为选举端口
在单机的时候可以直接将zoo_sample.cfg修改为zoo.cfg,然后使用启动服务即可(如果报错没有目录,手动创建即可):
sudo ./zkServer.sh start
现在用netstat -na(或者是./zkCli.sh 127.0.0.1:2181)就能看到在监听指定的端口,那么zookeeper现在起来了。
参考:
- http://blog.csdn.net/shenlan211314/article/details/6170717
- http://blog.csdn.net/hi_kevin/article/details/7089358
- 下载地址:http://apache.dataguru.cn/zookeeper/zookeeper-3.4.6
jstorm
该系统是阿里巴巴在对storm做了重写和优化,在storm里面能运行的在jstorm里面也能运行,该系统擅长执行实时计算,而且基本上都在内存中搞定。进入正题,jstorm中有如下几种角色:
- spout:源头。
- bolt:处理器。
- topology:由处理器、源头组成的拓扑网络(每条边就是一个订阅关系)。
- tuple:数据。
- worker:执行进程。
- task:执行线程。
- nimbus:分发代码、任务,监控集群运行状态
- supervisor:监听nimbus的指令,接收分发代码和任务并执行
jstorm是用zookeeper来管理的,下面来看conf/storm.yaml中的常用配置:
- storm.zookeeper.servers:zookeeper集群地址。
- storm.zookeeper.root:zookeeper中storm的根目录位置。
- storm.local.dir:用来存放配置文件、JAR等。
- storm.messaging.netty.transfer.async.batch:在使用Netty的时候,设置是否一个batch中会有多个消息。
- java.library.path:本地库的加载地址,比如zeromq、jzmq等。
- supervisor.slots.ports:supervisor节点上的worker使用的端口号列表。
- supervisor.enable.cgroup:是否使用cgroups来做资源隔离。
- topology.buffer.size.limited:是否限制内存,如果不限制将使用LinkedBlockingDeque。
- topology.performance.metrics:是否开启监控。
- topology.alimonitor.metrics.post:是否将监控数据发送给AliMonitor。
- topology.enable.classloader:默认禁用了用户自定义的类加载器。
- worker.memory.size:worker的内存大小。
在把配置搞正确之后,就可以用bin中的脚本来启动节点服务了:
sudo ./jstorm nimbus
sudo ./jstorm supervisor
参考:
- https://github.com/alibaba/jstorm/wiki/%E5%A6%82%E4%BD%95%E5%AE%89%E8%A3%85
- storm编程入门:http://ifeve.com/getting-started-with-storm-5/
jstorm的架构
结构和hadoop的很像,整体看来如下(Nimbus负责控制、提交任务,Supervisor负责执行任务):

为了做实时计算你需要建立topology,由计算节点组成的图:

在JStorm上的topology的生命周期如下:
- 上传代码并做校验(/nimbus/inbox);
- 建立本地目录(/stormdist/topology-id/);
- 建立zookeeper上的心跳目录;
- 计算topology的工作量(parallelism hint),分配task-id并写入zookeeper;
- 把task分配给supervisor执行;
- 在supervisor中定时检查是否有新的task,下载新代码、删除老代码,剩下的工作交个小弟worker;
- 在worker中把task拿到,看里面有哪些spout/Bolt,然后计算需要给哪些task发消息并建立连接;
- 在nimbus将topology终止的时候会将zookeeper上的相关信息删除;
在集群运行的时候要明白Worker、Executor、Task的概念,当然消息被传递的时候其实发起者、接收者都是Task,而真正执行的是Executor(可以理解为一个线程),由它来轮询其中的Spout/Bolt:

在jstorm中通过ack机制来保证数据至少被处理一次,简单来说下ack:
在消息发、收的过程中会形成一棵树状的结构,在一个消息收的时候发一个验证消息,发的时候也发一个验证消息,那么总体上每个消息出现两次。那么ack机制就是将每个消息的随机生成的ID进行异或,如果在某一时刻结果为0,那就说明处理成功。
如下图所示:
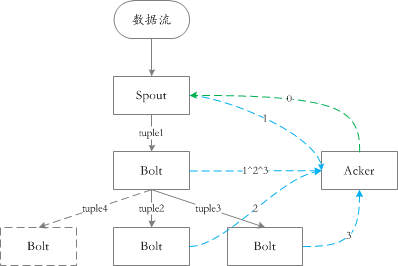
需要补充一下:虽然ack算是随机算法,但是出错的概率极低,但是系统应该具备在出错之后矫正的能力(甚至检查是否出错)。ack机制保证了消息会被处理,但是不能保证只处理一次&顺序处理,在需要的情形就有了事务的概念:

码代码
基本用法
所谓普通模式是指不去使用JStorm为开发人员提供的高级抽象,用其提供的原生的接口进行开发,主要涉及到的接口有:
- ISpout:数据源头接口,jstorm会不断调用nextTuple方法来获取数据并发射出去。
- open:在worker中初始化该ISpout时调用,一般用来设置一些属性:比如从spring容器中获取对应的Bean。
- close:和open相对应(在要关闭的时候调用)。
- activate:从非活动状态变为活动状态时调用。
- deactivate:和activate相对应(从活动状态变为非活动状态时调用)。
- nextTuple:JStorm希望在每次调用该方法的时候,它会通过collector.emit发射一个tuple。
- ack:jstorm发现msgId对应的tuple被成功地完整消费会调用该方法。
- fail:和ack相对应(jstorm发现某个tuple在某个环节失败了)。
- IBolt:数据处理接口,jstorm将消息发给他并让其处理,完成之后可能整个处理流程就结束了,也可能传递给下一个节点继续执行。
- prepare:对应ISpout的open方法。
- cleanup:对应ISpout的close方法(吐槽一下,搞成一样的名字会死啊...)。
- execute:处理jstorm发送过来的tuple。
- TopologyBuilder:每个jstorm运行的任务都是一个拓扑接口,而builder的作用就是根据配置文件构建这个拓扑结构,更直白就是构建一个网。
- setSpout:添加源头节点并设置并行度。
- setBolt:添加处理节点并设置并行度。
因为还存在多种其他类型的拓扑结构,那么在builder这个环节当然不能乱传,在基本用法要去实现IRichSpout、IRichBolt接口,他们并没有新增任何的方法,仅仅是用来区分类型。既然是拓扑结构那么应该是一个比较复杂的网络,其实这个是在builder中完成的,其中setSpout/setBolt返回的结果其实是InputDeclarer对象,在其中定义了N个流分组的策略:
|
1
2
3
4
5
6
7
8
9
10
11
|
public T fieldsGrouping(String componentId, String streamId, Fields fields); // 按字段分组,具有同样字段值的Tuple会被分到相同Bolt里的Task,不同字段值则会被分配到不同Task
public T globalGrouping(String componentId, String streamId); // 全局分组,Tuple被分配到Bolt中ID值最低的的一个Task。public T shuffleGrouping(String componentId, String streamId); // 随机分组,随机派发Stream里面的Tuple,保证每个Bolt接收到的Tuple数目大致相同,通过轮询随机的方式使得下游Bolt之间接收到的Tuple数目差值不超过1。public T localOrShuffleGrouping(String componentId, String streamId); public T noneGrouping(String componentId, String streamId); public T allGrouping(String componentId, String streamId); // 广播分组,每一个Tuple,所有的Bolt都会收到。public T directGrouping(String componentId, String streamId); // 直接分组,Tuple需要指定由Bolt的哪个Task接收。 只有被声明为Direct Stream的消息流可以声明这种分组方法。// 自定义分组 public T customGrouping(String componentId, CustomStreamGrouping grouping); public T customGrouping(String componentId, String streamId, CustomStreamGrouping grouping); public T grouping(GlobalStreamId id, Grouping grouping); |
通过这些接口,我们可以一边增加处理节点、一边指定其消费哪些消息。
批量用法
基本的用法是每次处理一个tuple,但是这种效率比较低,很多情况下是可以批量获取消息然后一起处理,批量用法对这种方式提供了支持。打开代码可以很明显地发现jstorm和storm的有着不小的区别:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// storm 中的定义public interface IBatchSpout extends Serializable { void open(Map conf, TopologyContext context); void emitBatch(long batchId, TridentCollector collector);// 批次发射tuple void ack(long batchId); // 成功处理批次 void close(); Map getComponentConfiguration(); Fields getOutputFields();}// jstorm中的定义public interface IBatchSpout extends IBasicBolt, ICommitter, Serializable {} |
另外如果用批次的话就需要改用BatchTopologyBuilder来构建拓扑结构,在IBatchSpout中主要实现的接口如下:
- execute:虽然和IBolt中名字、参数一致,但是增加了一些默认逻辑
- 入参的input.getValue(0)表示批次(BatchId)。
- 发送消息时collector.emit(new Values(batchId, value)),发送的列表第一个字段表示批次(BatchId)。
- commit:批次成功时调用,常见的是修改offset。
- revert:批次失败时调用,可以在这里根据offset取出批次数据进行重试。
Transactional Topology
事务拓扑并不是新的东西,只是在原始的ISpout、IBolt上做了一层封装。在事务拓扑中以并行(processing)和顺序(commiting)混合的方式来完成任务,使用Transactional Topology可以保证每个消息只会成功处理一次。不过需要注意的是,在Spout需要保证能够根据BatchId进行多次重试,在这里有一个基本的例子,这里有一个不错的讲解。
Trident
这次一种更高级的抽象(甚至不需要知道底层是怎么map-reduce的),所面向的不再是spout和bolt,而是stream。主要涉及到下面几种接口:
- 在本地完成的操作
- Function:自定义操作。
- Filters:自定义过滤。
- partitionAggregate:对同批次的数据进行local combiner操作。
- project:只保留stream中指定的field。
- stateQuery、partitionPersist:查询和持久化。
- 决定Tuple如何分发到下一个处理环节
- shuffle:随机。
- broadcast:广播。
- partitionBy:以某一个特定的field进行hash,分到某一个分区,这样该field位置相同的都会放到同一个分区。
- global:所有tuple发到指定的分区。
- batchGlobal:同一批的tuple被放到相同的分区(不同批次不同分区)。
- partition:用户自定义的分区策略。
- 不同partition处理结果的汇聚操作
- aggregate:只针对同一批次的数据。
- persistentAggregate:针对所有批次进行汇聚,并将中间状态持久化。
- 对stream中的tuple进行重新分组,后续的操作将会对每一个分组独立进行(类似sql中的group by)
- groupBy
- 将多个Stream融合成一个
- merge:多个流进行简单的合并。
- join:多个流按照某个KEY进行UNION操作(只能针对同一个批次的数据)。