数组存储数据的特点:有序、可重复,对于无序、不可重复的需要不能满足。
Collection接口:单列数据,定义了存取一组对象的方法的集合。
list:元素有序,可重复的集合;
set:元素无序,不可重复的集合;
Map接口:双列数据,保存具有映射关系“key-value对”的集合。
List集合:元素有序,可重复的
ArrayList、LinkList、vector三者的区别
相同点:都实现了list接口、存储数据有序的,可重复性的。
不同点:ArrayList:作为list接口的主要实现类,线程不安全,效率高,使用Object数组存储。
LinkList:对于频繁的插入、删除使用比ArrayList效率高,底层使用双线链表。
Vector:线程安全的,效率低。
ArrayList扩容:如果添加底层elementData数组容量不够,则扩容;默认情况下,扩容原来容量的1.5倍,同时将原有数组的数据复制到 新的数组中。
jdk1.8:底层Object类中elementData初始化为{},并没有创建数组,第一次调用add(),底层才创建长度为10的数组,并 将数据放入数组elementData[0]中。
LinkList:内部声明了Node类型的first和last属性,默认值为null,将数据封装到Node中,创建Node对象。Node的定义:体现了LinkList双向链表的说明。
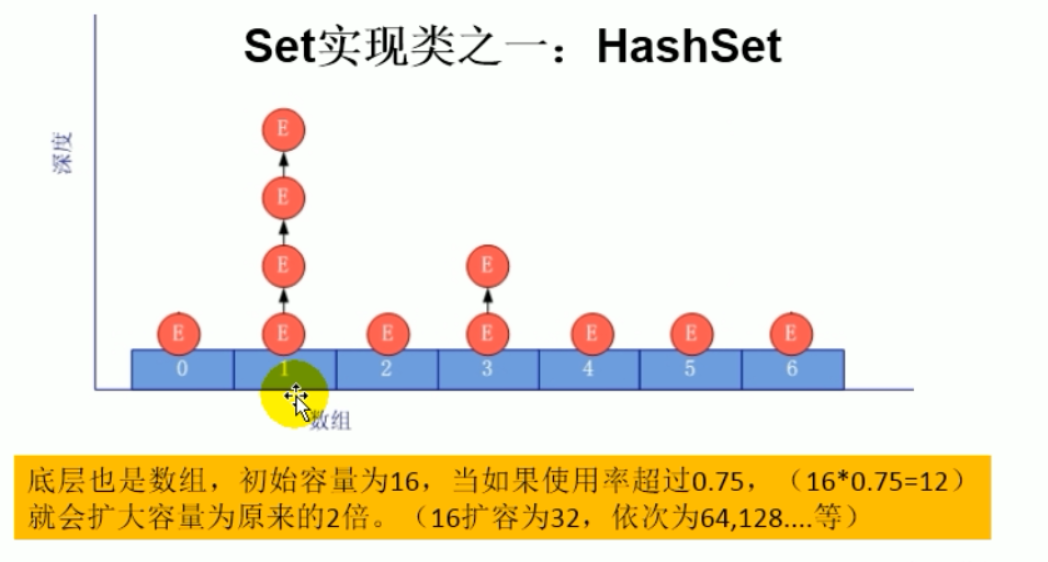
Set集合:存储无序的,不可重复的数据
1、无序性:不等于随机性,存储的数据在底层数组中并非按照数组索引顺序添加,而是根据数据的哈希值决定的。
不可重复性:保证添加的元素按照equas()判断时,不能返回true,即:相同的元素只能添加一个。
2、添加元素的过程,以hashSet为例:
我们向HashSet中添加元素a,首先调用元素a所在类的hashCode()方法,计算元素a的哈希值,此哈希值通过某种算法出在hashSet底层数组中的存放位置(即为:索引位置),判断数组此位置上是否已经有元素:
如果此位置上没有其它元素,则元素a添加成功。 ——>情况1
如果此位置上有其它元素b(或以链表形式存在多个元素),则对比元素a和元素b的hash值:
如果hash值不同,则元素a添加成功. ——>情况2
如果hash值相同,进而需要调用元素a所在类的equals()方法:
equals()返回true,元素a添加失败。
equals()返回false,则元素a添加成功。 ——>情况3
对于添加成功情况2和情况3而言:元素a与已存在指定位置上数据以链表的方式存储。
jdk7:元素a放到数组中,指向原来的元素。
jdk8:原来的元素在数组中,指向元素a。
总结:七上八下
1、Set接口中没有额外的定义新的方法,使用的都是collection中生命过的方法。
2、要求:向Set中添加的数据,其所在的类一定要重写hashCode()和equals();
要求重写的hashCode()和equals()尽可能保持一致性,相等的对象必须具有相等的散列码。