#物化节点
顾名思义,物化节点是一类可缓存元组的节点。在执行过程中,很多扩展的物理操作符需要首先获取所有的元组后才能进行操作(例如聚集函数操作、没有索引辅助的排序等),这时要用物化节点将元组缓存起来。下面列出了PostgreSQL中提供的物化节点。
T_MaterialState,
T_SortState,
T_GroupState,
T_AggState,
T_WindowAggState,
T_UniqueState,
T_HashState,
T_SetOpState,
T_LockRowsState,
T_LimitState,
##1.Material节点 先上例子:
postgres=# explain select * from test_dm where id > any (select id from test_new);
QUERY PLAN
------------------------------------------------------------------------
Nested Loop Semi Join (cost=0.00..32201696.41 rows=333333 width=68)
Join Filter: (test_dm.id > test_new.id)
-> Seq Scan on test_dm (cost=0.00..22346.00 rows=1000000 width=68)
-> Materialize (cost=0.00..58.25 rows=2550 width=4)
-> Seq Scan on test_new (cost=0.00..35.50 rows=2550 width=4)
(5 行)
这里的子查询“select id from test_new”的结果在主查询中会使用多次,因此postgres将其查询结果缓存下来,避免多次重复的查询。
所以我们知道了,Material节点用于缓存子节点结果,对于需要重复多次扫描的子节点(特别是扫描结果每次都相同时)可以减少执行的代价。其实现方式在于将结果元组存储于状态节点MaterialState中的特殊的数据结构Tuplestorestate中。
typedef struct MaterialState
{
ScanState ss; /* its first field is NodeTag */
int eflags; /* capability flags to pass to tuplestore */
bool eof_underlying; /* reached end of underlying plan? */
Tuplestorestate *tuplestorestate;
} MaterialState;
如上下两个数据结构所示,Material节点并没有在Plan的基础上定义扩展属性,执行状态节点MaterialState扩展了ScanState节点的定义,增加了tuplestorestate字段用于缓存元组。eof_underlying则表示下层节点已经扫描完毕,从而避免重复调用下层节点的执行过程,eflags是一个状态变量,它表示当前节点是否需要支持反向扫描、标记扫描位置和重新扫描三种操作。
typedef struct Material
{
Plan plan;
} Material;
Material节点的初始化过程(ExecInitMaterial函数〉主要是初始化eflags信息,并调用左子节点的初始化过程。
在Material节点执行过程(ExecMaterial函数)中,首先判断是否已经初始化tuplestorestate,如没有,则会调用tuplestore_begin_heap创建Tuplestorestate结构。然后把当前缓存中未返回的元组取出并返回,若不存在未返回的元组,则需要进一步判断下层节点是否扫描完毕(eof_underiying为true表示扫描完毕)。如果下层节点没有扫描完成则会从下层节点获取元组放入缓存中,同时返回元组;如果下层节点已经完成扫描,则Material节点将返回空元组。
Material节点的清理工作(ExecEndMaterial函数)主要是对于元组缓存结构的清理,并调用左子节点的清理过程,最后释放MaterialState结构。
##2.Sort节点
关于Sort节点我在之前已经介绍过,这里是地址:
##3.Group节点
group子句大家应该不陌生,上例子:
postgres=# explain select id from test_dm group by id having id < 5;;
QUERY PLAN
-------------------------------------------------------------------
HashAggregate (cost=24846.25..24847.25 rows=100 width=4)
Group Key: id
-> Seq Scan on test_dm (cost=0.00..24846.00 rows=100 width=4)
Filter: (id < 5)
(4 行)
Group节点用于处理GROUP BY子句,将下层节点满足选择条件(HAVING子句)的元组分组后,只返回该分组的第一个元组。该节点只有一个左子节点,且子节点必须返回在分组属性上已排好序的元组。
typedef struct Group
{
Plan plan;
int numCols; /* number of grouping columns */
AttrNumber *grpColIdx; /* their indexes in the target list */
Oid *grpOperators; /* equality operators to compare with */
} Group;
上面是Group节点的结构,它在Plan的基础上扩展了以下几个字段:
- numCols用于记录分组属性的个数;
- grpColIdx数组记录了分组属性的属性号;
- grpOperaticms数组记录了在分组属性上进行等值判断的操作符的OID。
typedef struct GroupState
{
ScanState ss; /* its first field is NodeTag */
FmgrInfo *eqfunctions; /* per-field lookup data for equality fns */
bool grp_done; /* indicates completion of Group scan */
} GroupState;
Group节点因为只有一个输人节点,因此初始化过程(ExecInitGroup函数)只需调用左子节点的初始化过程。然后对每个属性上的比较操作符进行初始化,找到对应的操作符函数相关信息(用Fmgrlnfo结构保存,该结构实际上记录了对应的操作函数在系统表中的需要用到的字段的值,这些字段值在fmgr模块调用指定函数时需要用到)。
在执行过程中,由于左子节点返回的结果是按照分组属性排序的,因此只要发现连续的两个元组在分组属性上不等,即可判定前一个元组就是上一个分组的最后一个元组,而后一个元组是一个新分组的第一个元组(很显然不是么)。
Group节点的执行过程(ExecGroup函数)如下:
1)获取下层返回元组中符合HAVING子句条件(存储于Plan, qual选择条件链表中)的第一个元组,将其作为分组内的第一个元组,缓存该元组信息到状态节点的ss_ScanTupleSlot中,并输出该元组;
2)依次获取组内的所有元组,直到获取到一个在分组属性上与当前分组不等的元组,表明当前分组结束;若下层节点返回空元组,表示分组操作完成,则会设置状态节点的grp_done字段为true并结束执行;
3)扫描下一个满足HAVING条件的元纽,缓存元组作为新分组的开始,并返回该元组;
4)重复执行2),3);
5)结束。
由于执行过程中使用了状态节点中的ss_ScanTupleSlot,在Group节点的清理过程(ExecEndGroup函数)中需要调用ExecClearTuple进行元组的淸理工作。
##4.Agg节点
上例子:
postgres=# explain select max(name) from test_dm;
QUERY PLAN <--- Plain策略
------------------------------------------------------------------------
Aggregate (cost=24846.00..24846.01 rows=1 width=45)
-> Seq Scan on test_dm (cost=0.00..22346.00 rows=1000000 width=45)
(2 rows)
postgres=# explain select max(name) from test_dm group by id order by id;
QUERY PLAN <--- Sorted策略
------------------------------------------------------------------------------
GroupAggregate (cost=122003.84..139503.84 rows=1000000 width=49)
Group Key: id
-> Sort (cost=122003.84..124503.84 rows=1000000 width=49)
Sort Key: id
-> Seq Scan on test_dm (cost=0.00..22346.00 rows=1000000 width=49)
(5 rows)
postgres=# explain select max(name) from test_dm group by id;
QUERY PLAN <--- Hash策略
------------------------------------------------------------------------
HashAggregate (cost=27346.00..37346.00 rows=1000000 width=23)
Group Key: id
-> Seq Scan on test_dm (cost=0.00..22346.00 rows=1000000 width=23)
(3 rows)
Agg节点用于执行含有聚集函数的GROUP BY操作,该节点能够实现三种执行策略:Plain (不分组的聚集计算)、Sorted (下层节点提供排好序的元组,类似Group的分组方法,然后进行聚集计算)、Hash (首先对下层节点提供的未排序元组进行分组,然后进行计算)。
Agg的执行的一般方法是:首先初始化聚集计算的初始值,将其记录在中间结果中。然后,针对每一条输人元组使用迭代聚集函数进行迭代计算,得到新的中间结果。最后,如果有必要的话,使用结束函数进行处理。
我们可以看看代码中怎么说的:
src/backend/executor/nodeAgg.c
* ExecAgg evaluates each aggregate in the following steps:
*
* transvalue = initcond
* foreach input_tuple do
* transvalue = transfunc(transvalue, input_value(s))
* result = finalfunc(transvalue, direct_argument(s))
其中,initcond表示初始值,transvalue为中间结果,input_tuple是输人的元组,transfunc是迭代聚集函数,finalfunc是结束函数,result是最终的结果。(postgres可以自定义agg,那么我们也就知道了自定义agg需要哪些函数支持了。这个我在在PostgreSQL自定义一个“优雅”的type的第二节里写了一点用法)
Agg节点的定义如下所示,除了定义执行的策略类型(aggstrategy),还定义了聚集属性的数量(mimCols)、聚集属性的属性号数组(gtpColIdx)、分组函数数组(grpOperators)以及估计的分组数量(numGroups)。
typedef struct Agg
{
Plan plan;
AggStrategy aggstrategy;
int numCols; /* number of grouping columns */
AttrNumber *grpColIdx; /* their indexes in the target list */
Oid *grpOperators; /* equality operators to compare with */
long numGroups; /* estimated number of groups in input */
Bitmapset *aggParams; /* IDs of Params used in Aggref inputs */
/* Note: planner provides numGroups & aggParams only in AGG_HASHED case */
List *groupingSets; /* grouping sets to use */
List *chain; /* chained Agg/Sort nodes */
} Agg;
在Agg节点的初始化过程(ExecInitAgg函数)中,首先对目标属性targetlist和査询条件qual进行初始化,并找到其中的Aggref节点(用于表示聚集函数的表达式节点)。然后根据每个Aggref节点中存储的聚集函数信息进行初始化,为其构造一个AggStatePerAgg结构,其中存储了聚集函数信息运算相关的信息和内存上下文。如果有多个相同的Aggref节点,只会构造一个AggStatePerAgg结构(例如“SELECT sum(x)... HAVING sum (x) >0”中的求和运算)。最后根据策略类塱对相应的状态信息进行初始化:
1)Plain (aggstrategy 值为 AGG_PLAIN)和 Sorted (aggstrategy 值为 AGG_SORTED)策略都不需复杂的分组过程,因此每次执行只需保存一个分组的中间结果,此时可使用pergroup结构数组保存一个分组的所有聚集函数的中间结果。由于Sorted方法与Group的分组方式一致,因此还需要eq_function用于判断分组的分界线,并用grp_firstTuple字段缓存分组的第一个元组。
2)Hash (aggstrategy值为AGG_HASHED)策略,Hash表中不缓存真正的元组,而只是使用元组计算得到的Hash值作为索引。Hash表(hasJitable)中只存储该分组的聚集函数中间值的数组(由AggStatePerGroup结构存储),而hashslot用于缓存Hash的元组中需要进行Hash的属性值,hash_needed则对应于需要进行Hash的属性序号的链表。在巳经获取了所有下层节点元组后,从Hash表中依次获取分组的中间结果时会用到hashiter。构造Hash函数信息从Agg节点的grpOperators获取,信息存放于hashfunctions数组中。初始化时会对涉及的这些属性进行初始化。
下图展示了 AGG_PLAIN/AGG_SORTED策略的执行状态。其中,peragg用于存储聚集函数(即transfunc),pergroup存储了当前所处理分组的状态,获取的元组将与每一个pergroup值一并被peragg中的函数处理,得到新的中间结果,重新存储于相应的pergroup中。AGG_HASHED过程则需要首先计算输人元组的Hash值,然后从Hash表中获取对应分组的中间结果记录数组,类似于pergroup,然后进行和以上两个策略相同的计算过程。(后续补充....)
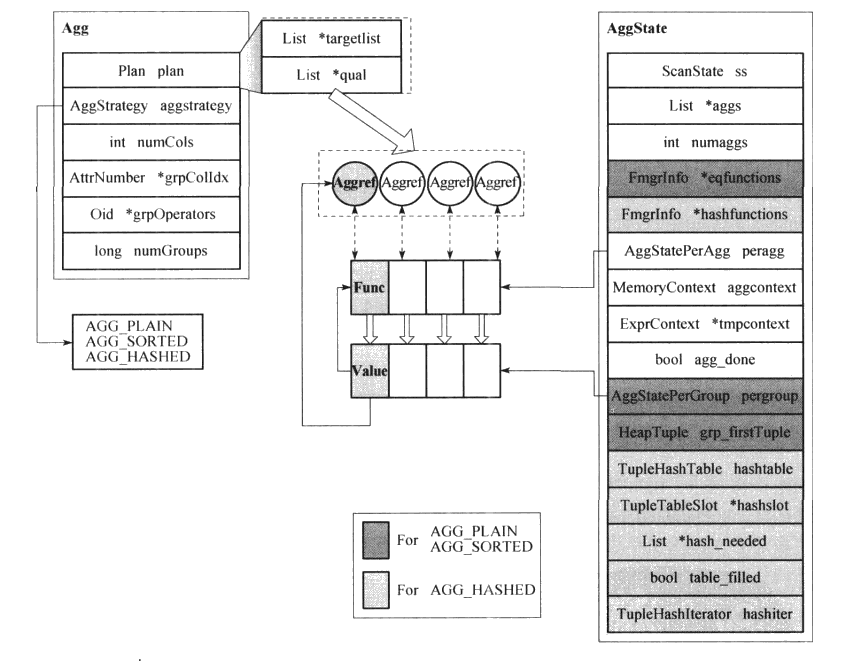
Agg节点清理过程需要对使用到的内存上下文进行回收,清理分配的TupleTableSlot结构,并调用下层节点的淸理过程。
##5.Unique 节点
Unique节点用于对下层节点返回的已排序元组进行去重操作。由于下层节点获取到的元组已经排序,因此在Unique节点的执行过程中只需要缓存上一个返回的元组,判断当前获f的元组是否和上一个元组在指定厲性上重复。如果重复,则忽略当前元组并继续从下层节点获取元组;如果不重复,则输出当前元组并用它替换缓存中的元组。Unique节点一般用于处理査询中的DISTINCT关键字,但这不是唯一的处理方式。如果要求去重的属性被“ORDER BY”子句引用时,一般会使用Unique节点进行处理(例如,“SELECT DISTINCT(x) … ORDER BY x”中的属性x)。
postgres=# explain select distinct(id) from test_dm order by id;
QUERY PLAN
-----------------------------------------------------------------------------
Unique (cost=122003.84..127003.84 rows=1000000 width=4)
-> Sort (cost=122003.84..124503.84 rows=1000000 width=4)
Sort Key: id
-> Seq Scan on test_dm (cost=0.00..22346.00 rows=1000000 width=4)
(4 rows)
postgres=# explain select distinct(id) from test_dm;
QUERY PLAN
-----------------------------------------------------------------------
HashAggregate (cost=24846.00..34846.00 rows=1000000 width=4)
Group Key: id
-> Seq Scan on test_dm (cost=0.00..22346.00 rows=1000000 width=4)
(3 rows)
Unique节点的定义如下,其中numCols表示用于去重的属性数量,uniqColIdx数组和uniqOperators数组分别存储了去重属性的属性号和对应的判断操作符。
typedef struct Unique
{
Plan plan;
int numCols; /* number of columns to check for uniqueness */
AttrNumber *uniqColIdx; /* their indexes in the target list */
Oid *uniqOperators; /* equality operators to compare with */
} Unique;
在初始化过程中,会根据中的操作符列表初始化UniqueState结构中用于保存判断函数信息的eqfunctions字段。
typedef struct UniqueState
{
PlanState ps; /* its first field is NodeTag */
FmgrInfo *eqfunctions; /* per-field lookup data for equality fns */
MemoryContext tempContext; /* short-term context for comparisons */
} UniqueState;
Unique节点的执行过程会首先从下层节点获取一个元组,如果是第一个元组,则直接输出。否则将使用eqfunctions中的函数判断当前元组与上次返回的元组在去重属性上是否相等,如果当前元组与上次返回的元组在去重属性上不相等则输出当前元组,如果相等则再从下层节点获取下一个元组进行同样的判断。
##6.Hash节点
Hash节点作为Hashjoin节点的辅助节点,共同完成Hash连接方法。Hash节点利用Hash方法(这个后面再讲吧,目前没看到),将从左子节点获取的元组放人构造好的 Hash 表中。 Hash 节点也只有一个左子节点。 例子如下:
postgres=# explain select a.id,b.id from test_dm a join test_new b on a.id = b.id;
QUERY PLAN
-------------------------------------------------------------------------------
Hash Join (cost=34846.00..34916.56 rows=2550 width=8)
Hash Cond: (b.id = a.id)
-> Seq Scan on test_new b (cost=0.00..35.50 rows=2550 width=4)
-> Hash (cost=22346.00..22346.00 rows=1000000 width=4)
-> Seq Scan on test_dm a (cost=0.00..22346.00 rows=1000000 width=4)
(5 rows)
如下所示,Hash节点定义了skew方法(主要用于Hashjoin节点)需要使用的相关信息。这些信息用于构造Hash表时,使用外连接表的元组统计信息来优化Hash表的组织结构,将最常用的Hash值单独存放,保持在内存中,以优化连接时Hash匹配的过程。这些信息包括了属性偏移量和属性的类型等。
typedef struct Hash
{
Plan plan;
Oid skewTable; /* outer join key's table OID, or InvalidOid */
AttrNumber skewColumn; /* outer join key's column #, or zero */
bool skewInherit; /* is outer join rel an inheritance tree? */
Oid skewColType; /* datatype of the outer key column */
int32 skewColTypmod; /* typmod of the outer key column */
/* all other info is in the parent HashJoin node */
} Hash;
Hash节点的初始化过程仅构造HashState节点,并未构建Hash表和hashkeys (将由Hashjoin节点进行初始化)。
typedef struct HashState
{
PlanState ps; /* its first field is NodeTag */
HashJoinTable hashtable; /* hash table for the hashjoin */
List *hashkeys; /* list of ExprState nodes */
/* hashkeys is same as parent's hj_InnerHashKeys */
} HashState;
Hash节点在执行时会从下层节点获取元组,并使用hashkeys中的表达式计箅元组的Hash值,通过Hash值中的块号判断是否需要放人缓存文件中(Hash表一次只能将一个块的内容放人内存中),然后将元组保存在Hash表相应的块中。Hash节点的清理过程会调用下层左子节点的清理过程。
剩下的下篇再说吧~