本文结合原理和源代码分析Google提出的Transformer机制
首先看一些Transformer的整体结构:
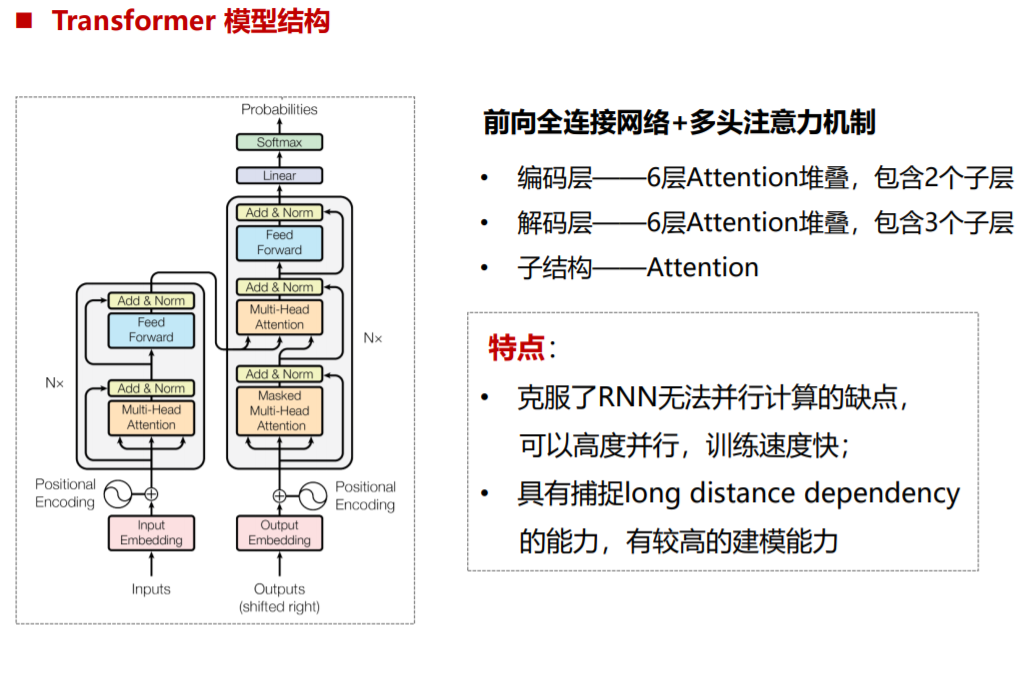
inputs:[batch_size,maxlen] #maxlen表示source文本的最大长度
经过一次Embedding,首先根据隐藏节点的数目将inputs的维度变成[batch_size,maxlen,num_units]
def embedding(lookup_table,inputs,num_units,scale=False,scope='embedding',reuse=None): """ 查询子词向量 :param lookup_table: :param inputs: :param num_units: :param scale: :param scope: :param reuse: :return: 词向量表示的输入 """ outputs = tf.nn.embedding_lookup(lookup_table, inputs) # 根据num_units对outputs进行缩放 if scale: outputs = outputs * (num_units ** 0.5) return outputs
接下来由于Transformer舍去了RNN或CNN的结构,也就失去了序列的位置信息,因此需要对输入进行位置编码,论文中
def positional_encoding(inputs, num_units, zero_pad=True, scale=True, scope="positional_encoding", reuse=None): """ 位置编码 :param inputs: :param num_units: :param zero_pad: :param scale: :param scope: :param reuse: :return: """ N, T = inputs.get_shape().as_list() with tf.variable_scope(scope, reuse=reuse): position_ind = tf.tile(tf.expand_dims(tf.range(T), 0), [N, 1]) # First part of the PE function: sin and cos argument position_enc = np.array([ [pos / np.power(10000, 2.*i/num_units) for i in range(num_units)] for pos in range(T)]) # Second part, apply the cosine to even columns and sin to odds. position_enc[:, 0::2] = np.sin(position_enc[:, 0::2]) # dim 2i position_enc[:, 1::2] = np.cos(position_enc[:, 1::2]) # dim 2i+1 # Convert to a tensor lookup_table = tf.convert_to_tensor(position_enc) if zero_pad: lookup_table = tf.concat((tf.zeros(shape=[1, num_units]), lookup_table[1:, :]), 0) outputs = tf.nn.embedding_lookup(lookup_table, position_ind) if scale: outputs = outputs * num_units**0.5 return outputs
接下来是论文的核心:Self-attention机制,在编码端,Q,K,V的值是相同的。作者并没有仅使用一个attention,而是使用了多个attention,称为Multi-Head Attention,具体的实现方式为:
(1)将Q,K,V输入到8个Self-Attention中,得到8个加权后的矩阵Zi
(2)将8个Zi拼接成一个大的特征矩阵(按列拼接)
(3)经过一层全连接得到输出Z
下图为一个Self-Attention的计算方式
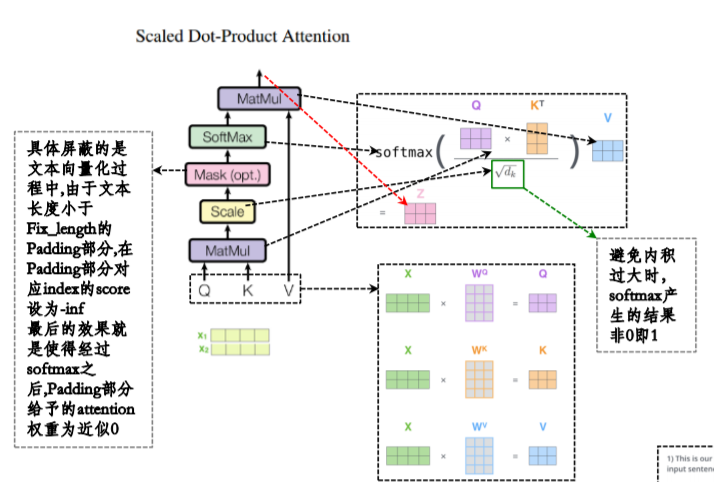
这里的mask操作体现在源码中对keys和query的屏蔽,方式都是将0的位置变为极小的数(接近于0),这样经过softmax后会变成一个接近于0的数字
key masking目的是让key值的unit为0的key对应的attention score极小,这样加权计算value时相当于对结果不产生影响。Query Masking 要屏蔽的是被<PAD>所填充的内容。
#Key Maksing #这里的目的是让key值的unit为0的key对应的attention score极小,这样加权计算value时相当于对结果不产生影响 key_masks=tf.sign(tf.abs(tf.reduce_mean(keys,axis=-1))) #[N,T_k] key_masks=tf.tile(key_masks,[num_heads,1]) #[h*N,T_k] key_masks=tf.tile(tf.expand_dims(key_masks,1),[1,tf.shape(queries)[1],1]) #[h*N,T_q,T_k] # Query Masking # 要被屏蔽的,是本身不懈怠信息或暂时不利用其信息的内容 # query mask要将初始值为0的queries屏蔽 query_masks = tf.sign(tf.abs(tf.reduce_sum(queries, axis=-1))) # (N, T_q) query_masks = tf.tile(query_masks, [num_heads, 1]) # (h*N, T_q) query_masks = tf.tile(tf.expand_dims(query_masks, -1), [1, 1, tf.shape(keys)[1]]) # (h*N, T_q, T_k) # 前三步与Key Mask方法类似,这里用softmax后的outputs的值与query_masks相乘,因此这一步后需要mask的权值会乘0,不需要mask # 的乘以之前取的正数的sign为1所以权值不变,从而实现了query_mask目的 outputs *= query_masks # broadcasting. (N, T_q, C)
对比于解码器端,我们发现解码器端有两个Multi-Head,第一个Multi-Head使用了mask操作。原因在于我们训练的过程中,预测当前的值,是不能看到未来的词的,作者的实现方式是通过一个下三角矩阵
# Causality = Future blinding # Causality 标识是否屏蔽未来序列的信息(解码器self attention的时候不能看到自己之后的哪些信息) # 这里通过下三角矩阵的方式进行,依此表示预测第一个词,第二个词,第三个词... if causality: diag_vals = tf.ones_like(outputs[0, :, :]) # (T_q, T_k) tril = tf.linalg.LinearOperatorLowerTriangular(diag_vals).to_dense() # (T_q, T_k) masks = tf.tile(tf.expand_dims(tril, 0), [tf.shape(outputs)[0], 1, 1]) # (h*N, T_q, T_k) paddings = tf.ones_like(masks) * (-2 ** 32 + 1) outputs = tf.where(tf.equal(masks, 0), paddings, outputs) # (h*N, T_q, T_k)
对于第一个MultiHead Attention,Q,K,V都是解码器的输入,在训练阶段是目标(target),在预测阶段因为没有信息,全部填充<PAD>进行替代。
对于第二个MultiHead Attention,Q是第一个MultiHead Attention的输出,K和V都是编码器段的输出。
上述全部过程的源代码如下:
def multihead_attention(queries,keys,num_units=None,num_heads=8,dropout_rate=0,is_training=True, causality=False,scope='multihead_attention',reuse=None): """ :param queries:[batch_size,maxlen,hidden_unit] :param keys: 和value的值相同 :param num_units:缩放因子,attention的大小 :param num_heads:8 :param dropout_rate: :param is_training: :param causality: 如果为True的话表明进行attention的时候未来的units都被屏蔽 :param scope: :param reuse: :return:[bactch_size,maxlen,hidden_unit] """ with tf.variable_scope(scope,reuse=reuse): # Set the fall back option for num_units if num_units is None: num_units = queries.get_shape().as_list[-1] #线性映射 #先对Q,K,V进行全连接变化 Q=tf.layers.dense(queries,num_units,activation=tf.nn.relu) K=tf.layers.dense(keys,num_units,activation=tf.nn.relu) V=tf.layers.dense(keys,num_units,activation=tf.nn.relu) #Split and concat #将上一步的Q,K,V从最后一维分成num_heads=8份,并把分开的张量在第一个维度拼接起来 Q_=tf.concat(tf.split(Q,num_heads,axis=2),axis=0) #[h*N,T_q,C/h] K_=tf.concat(tf.split(K,num_heads,axis=2),axis=0) #[h*N,T_k,C/h] V_=tf.concat(tf.split(V,num_heads,axis=2),axis=0) #[h*N,T_k,C/h] #Multiplication #Q*K转置: 这一步将K转置后和Q_进行了矩阵乘法的操作,也就是在通过点成方法进行attention score的计算 outputs=tf.matmul(Q_,tf.transpose(K_,[0,2,1])) #[0,2,1]表示第二维度和第三维度进行交换[h*N,C/h,T_k] 三维矩阵相乘变为[h*N,T_q,T_k] #scale 除以调节因子 outputs=outputs/(K_.get_shape().as_list()[-1]**0.5) #开根号 #Key Maksing #这里的目的是让key值的unit为0的key对应的attention score极小,这样加权计算value时相当于对结果不产生影响 key_masks=tf.sign(tf.abs(tf.reduce_mean(keys,axis=-1))) #[N,T_k] key_masks=tf.tile(key_masks,[num_heads,1]) #[h*N,T_k] key_masks=tf.tile(tf.expand_dims(key_masks,1),[1,tf.shape(queries)[1],1]) #[h*N,T_q,T_k] paddings=tf.ones_like(outputs)*(-2 **32+1) #创建一个全为1的tensor变量 outputs=tf.where(tf.equal(key_masks,0),paddings,outputs) #对为0的位置,用很小的padding进行替代 为1的地方返回padding,否则返回outputs # Causality = Future blinding # Causality 标识是否屏蔽未来序列的信息(解码器self attention的时候不能看到自己之后的哪些信息) # 这里通过下三角矩阵的方式进行,依此表示预测第一个词,第二个词,第三个词... if causality: diag_vals = tf.ones_like(outputs[0, :, :]) # (T_q, T_k) tril = tf.linalg.LinearOperatorLowerTriangular(diag_vals).to_dense() # (T_q, T_k) masks = tf.tile(tf.expand_dims(tril, 0), [tf.shape(outputs)[0], 1, 1]) # (h*N, T_q, T_k) paddings = tf.ones_like(masks) * (-2 ** 32 + 1) outputs = tf.where(tf.equal(masks, 0), paddings, outputs) # (h*N, T_q, T_k) # Activation # 对Attention score进行softmax操作 outputs = tf.nn.softmax(outputs) # (h*N, T_q, T_k) # Query Masking # 要被屏蔽的,是本身不懈怠信息或暂时不利用其信息的内容 # query mask要将初始值为0的queries屏蔽 query_masks = tf.sign(tf.abs(tf.reduce_sum(queries, axis=-1))) # (N, T_q) query_masks = tf.tile(query_masks, [num_heads, 1]) # (h*N, T_q) query_masks = tf.tile(tf.expand_dims(query_masks, -1), [1, 1, tf.shape(keys)[1]]) # (h*N, T_q, T_k) # 前三步与Key Mask方法类似,这里用softmax后的outputs的值与query_masks相乘,因此这一步后需要mask的权值会乘0,不需要mask # 的乘以之前取的正数的sign为1所以权值不变,从而实现了query_mask目的 outputs *= query_masks # broadcasting. (N, T_q, C) # Dropouts outputs = tf.layers.dropout(outputs, rate=dropout_rate, training=tf.convert_to_tensor(is_training)) # Weighted sum # 用outputs和V_加权和计算出多个头attention的结果 outputs = tf.matmul(outputs, V_) # ( h*N, T_q, C/h) # Restore shape # 上步得到的是多头attention的结果在第一个维度叠着,所以把它们split开重新concat到最后一个维度上 outputs = tf.concat(tf.split(outputs, num_heads, axis=0), axis=2) # (N, T_q, C) # Residual connection # outputs加上一开始的queries, 是残差的操作 outputs += queries # Normalize outputs = normalize(outputs) # (N, T_q, C) return outputs
最后经过一个前向神经网络和layer Norm操作,我们可以得到最终输出
在前向神经网络部分,用一维卷积替代全连接操作:
def feedforward(inputs,num_units=[2048,512],scope='multihead_attention',reuse=None): """ 将多头attention的输出送入全连接网络 :param inputs: shape的形状为[N,T,C] :param num_units: :param scope: :param reuse: :return: """ with tf.variable_scope(scope,reuse=reuse): # Inner layer params={ "inputs":inputs, "filters":num_units[0], "kernel_size":1, "activation":tf.nn.relu, "use_bias":True } #利用一维卷积进行网络的设计 outputs=tf.layers.conv1d(**params) #一维卷积最后一个维度变为2048 #Readout layer params={ "inputs": outputs, "filters": num_units[1], "kernel_size": 1, "activation": None, "use_bias": True } outputs=tf.layers.conv1d(**params) #Residual connection #加上inputs的残差 outputs+=inputs #Normalize outputs=normalize(outputs) return outputs
layer normalization:(归一化,模型优化)https://zhuanlan.zhihu.com/p/33173246
def normalize(inputs,epsilon=1e-8,scope="ln",reuse=None): """ :param inputs:[batch_size,..]2维或多维 :param epsilon: :param scope: :param reuse:是否重复使用权重 :return: A tensor with the same shape and data dtype as `inputs`. """ with tf.variable_scope(scope,reuse=reuse): inputs_shape=inputs.get_shape() params_shape=inputs_shape[-1:] mean,variance=tf.nn.moments(inputs,[-1],keep_dims=True) beta=tf.Variable(tf.zeros(params_shape)) gamma=tf.Variable(tf.ones(params_shape)) normalized=(inputs-mean)/((variance+epsilon)**(.5)) outputs=gamma*normalized+beta return outputs