SVM(Support Vector Machine)有监督的机器学习方法,可以做分类也可以做回归。SVM把分类问题转化为寻找分类平面的问题,并通过最大化分类边界点距离分类平面的距离来实现分类。
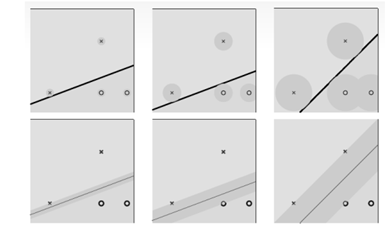
有好几个模型,SVM基本,SVM对偶型,软间隔SVM,核方法,前两个有理论价值,后两个有实践价值。下图来自龙老师整理课件。

基本概念
线性SVM,线性可分的分类问题场景下的SVM。硬间隔。
线性不可分SVM,很难找到超平面进行分类场景下的SVM。软间隔。
非线性SVM,核函数(应用最广的一种技巧,核函数的选择十分重要)。
SVR(支持向量回归)。可以做回归。
SVC,用SVM进行分类。
一、硬间隔的支持向量机
假设函数:可以与LR类比,只是外面是套的符号函数,wx+b>0认为是正类,wx+b<0认为是负类。

损失函数:
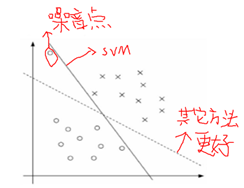
从中挑选出最好的能分离黑点点和白点点的直线(分离边界),是硬间隔所要解决的问题。
直观上:我们认为处在两个样本正中间的位置的分离边界最好。理论上,对训练样本的局部扰动的容忍性最好,鲁棒性最好,泛化能力好。几何上,两类支持向量的中间垂面。
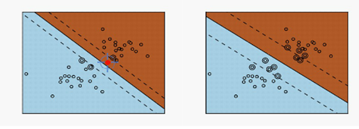
几何上:如下图所示,当考虑样本的误差增大时(认为所有样本的误差一样大),能完全分开圈圈和叉叉的直线减少。下图第一排等价于下图第二排。其实支持向量就是被下面那行胖胖的线穿过的点,只是这些点在高纬空间中对应着向量,所以叫支持向量。优化的目标就是找到一条最胖的线,刚好穿过我们的样本,同时又能把所有样本分离开,而那条胖胖线的中垂线,就是我们要找的直线,其实这样是考虑容错率,计算真实的样本测量错了,仍然能够分隔开;最胖的线左边和右边的距离就叫做间隔。间隔空间之内没有任何样本,即硬间隔。线的左边是一类样本,线的右边是另一类样本。
数学上:
那条中垂线:WtX+b=0,根据假设函数而来,既不为正,也不为负值。Wt为超平面法向量,法向量实际上就是与中垂线垂直的那个方向(想想b是标量,求解x,实际上能看出w与x就是垂直的,即内积,只是这里叫法向量)。b为原点到超平面的有向距离的放缩。w/|w|*x实际上就是内积,几何上就是投影(点到线的距离)。如果w和b同时放缩任意比例,原超平面不变。所以可以同时除以||w||。

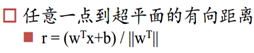
圈圈到超平面的距离,是胖胖线的一半r。叉叉到超平面的距离也是胖胖线的一半,但是是负向 -r。任意一点到超平面的距离大于r时,yi等于+1,属于正类,任意一点到超平面的距离小于-r时,属于负类。而我们的目标就是最大化r 同时要满足,将两类进行分割,所以有如下约束条件,具体如下。

在此基础上,不妨另1/|W|=r,可以简化目标函数。其实损失函数就是对最优化的理解、对误差的理解、对数据的理解,根据这些而设计出来的。

而最终目标函数的求解,是一个在一次约束下,求二次最优的过程,即一个典型的凸二次规划问题,所以肯定是可以求解的,对偶方法可以求解。
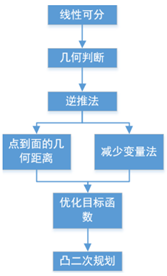
综合以上SVM的推导过程如下:首先假设是线性可分的,由此我们有一定的几何判断和认识,基于该几何判断和认识下,通过逆推法,我们假设找到了这个最优的分离边界,应该满足哪些特点,包括需要知道点到面的几何距离的概念,变量又比较多,最终通过一个减少变量法,然后就得到了优化目标函数。
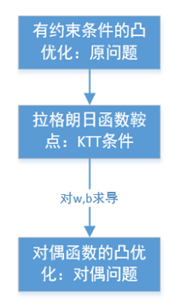
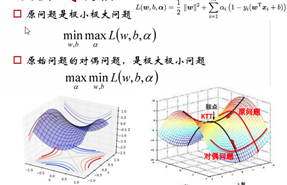
因为原问题为凸优化,所以原问题的凸优化问题与拉格朗日函数鞍点(又不是最大值又不是最小值,梯度是0的点),对偶函数(转化为对w,b求导)的凸优化问题的解一致。之所以还转化为对偶,就是为了好求。原问题是拉格朗日函数,在固定了w,b条件下,最大拉格朗日系数α条件下求解拉格朗日函数最小。对偶问题,是固定α,最小化w,b,这样通过求导可以算出w,b与α之间的关系,进而将目标函数转化为只有α,y,x。
根据KKT条件可知,需要满足yi*f(xi)=1,而满足这个条件的点,就是上文提到的支持向量点,f(x)是假设函数。
假设函数只与支持向量有关,更加体现了几何意义。SVM不受那种离分隔边界很远的极值点的影响,哪怕有个很远的叉叉点,对分离边界也不会有影响,而逻辑回归则会受影响。


硬间隔的局限性:
不一定分类完全正确的超平面最好
样本数据本身线性不可分
二、软间隔的支持向量机
正因为由上面硬间隔支持向量机的局限性,才有了软间隔支持向量机,一般实际中都不会用硬间隔,因为一般都不可能完全线性可分。软间隔支持向量机考虑了在间隔中间的点,以及间隔外被错分类的点,这些点都是支持向量点,都要计算损失函数。而之前硬间隔是要找到完全分开的分隔边界。


上面的损失函数,除以C可以类比于逻辑回归的损失函数,左边是正则项,右边是hinge损失函数(当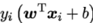 >1则没有任何损失,当
>1则没有任何损失,当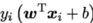 <1则有损失)。C越小考虑的点越多。C越大是硬间隔。
<1则有损失)。C越小考虑的点越多。C越大是硬间隔。
与上文一样,根据拉格朗日,用α表示w,b,求解损失函数最小:

看KKT条件,得出以下结论:

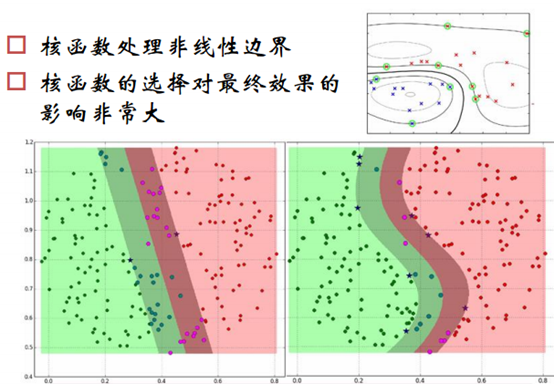
三、 核函数
核函数处理线性不可分问题。核函数目的就是使得线性不可分的问题,用非线性的边界更好的分离开。
核函数即为下图的,把原来的x映射到高纬空间的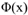 ,原来可能是10维*10维,映射到高维空间可能是100维*100维,但通过kernel技巧,两个高维
,原来可能是10维*10维,映射到高维空间可能是100维*100维,但通过kernel技巧,两个高维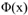 的内积可以转化为低维x的内积,大大简化了计算。核函数就是为了映射到高维空间求内积而产生的,而我们上面的提到分离边界要是曲线,就必须是高维,而同时我们的损失函数就是内积的一个函数,所以这就完美的解决了上面的问题呢~把上面wx+b都可以转化为w
的内积可以转化为低维x的内积,大大简化了计算。核函数就是为了映射到高维空间求内积而产生的,而我们上面的提到分离边界要是曲线,就必须是高维,而同时我们的损失函数就是内积的一个函数,所以这就完美的解决了上面的问题呢~把上面wx+b都可以转化为w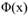 +b。在原来样本做一个无穷维的空间映射,再做分类。下图为多项式核。
+b。在原来样本做一个无穷维的空间映射,再做分类。下图为多项式核。
![]()
![]()
另一个应用广泛的核函数(径向基核函数,也称为高斯核)如下,可以映射到无限高维空间。
![]()
![]()
四、 LR与SVM的异同
相同:都可以做分类;假设函数都是连续、线性的wx+b,只是一个在外面套了simoid函数,一个套了sign函数;正则项处理方式类似。
不同:SVM要考虑支持向量本身,而逻辑回归是不只考虑支持向量,而考虑所有点。损失函数不一样,一个叫对数几率损失函数,一个是hinge损失函数。支持向量机要用对偶法,逻辑回归没必要用对偶法。硬间隔的SVM,的损失函数是有约束条件下的凸优化问题(所以不能用梯度下降法,而要考虑对偶法等考虑约束的最优化求解方法),而逻辑回归是没有约束条件下的凸优化问题(所以可以用梯度下降法,走到的一定是最优点)。逻辑回归比较好解释,SVM没有那么好解释。
在线性边界情况,LR与SVM效果差不多,在非线性分离边界,SVM由于有核技巧,所以分得会更好点,但也有可能过拟合,核函数的选择时关键而且很复杂。
优点:可以解决小样本下机器学习问题;提高泛化性能,一般不会过拟合;可以解决文本分类、文字识别、图像分类等方面受欢迎;避免神经网络结构选择和局部极小值问题;不怕维度灾难。
缺点:缺失值敏感;内存消耗大,难以解释。
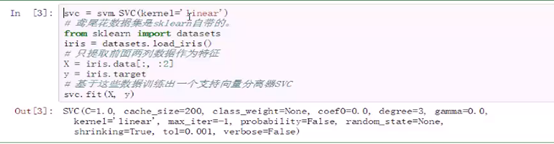
Python:
在Python中SVM包天生就带了正则,而LR需要自己添加正则,如果不加的化鲁棒性会差。

SVC中的参数,C就是损失函数里面那个C;class_weigh是类别的权重;kernel选择核函数;最大迭代次数-1指的是无穷大;probability是否需要输出概率形式;tol损失函数要收敛到一个合适的值,前后两个损失函数的差距小于tol就收敛。
上面说了这么多。。。那么SVM用通俗的语言再解释下到底是什么呢。。。看到有篇博客写的很不错呢,拷过来
http://www.cnblogs.com/jerrylead/archive/2011/03/18/1988419.html#2200002
SVM的思想确实那么简单。它不再像logistic回归一样企图去拟合样本点(中间加了一层sigmoid函数变换),而是就在样本中去找分隔线,为了评判哪条分界线更好,引入了几何间隔最大化的目标。之后所有的推导都是去解决目标函数的最优化上了。在解决最优化的过程中,发现了w可以由特征向量内积来表示,进而发现了核函数,仅需要调整核函数就可以将特征进行低维到高维的变换,在低维上进行计算,实质结果表现在高维上。由于并不是所有的样本都可分,为了保证SVM的通用性,进行了软间隔的处理,导致的结果就是将优化问题变得更加复杂,然而惊奇的是松弛变量没有出现在最后的目标函数中。最后的优化求解问题,也被拉格朗日对偶和SMO算法化解,使SVM趋向于完美。