Pandas是基于NumPy的一种工具,该工具是为了解决数据分析任务而创建的。
1、导入pandas
import pandas as pd
2、pandas数据类型:
1)Series:一维数据类型,其中每个元素都有一个标签
2)DataFrame:二维数据类型,它可以存储各种不同类型的数据,每个元素都有自己的标签
3、Series对象的创建
s = pd.Series([-1.234,2.354,1.256,-5.235])

可以看到如果我们没有指定行索引,pandas将会默认给它创建0,1,2,...等作为行索引
当然我们也可以给它指定行索引index,如下:

注意上面两个例子中打印出来的的type,下面我们将其中一个数字改为字符串,这时候,它就不再是单纯的数字了,它的dtype就变成了object

也就是说,我们可以指定dtype输出,如下,指定dtype为int,输出值就全部去掉小数部分,只打印出了整数部分的值:

除了上面的以list创建Series外,还可以通过字典方式,常量值等来创建Series


4、Series对象的访问
s.values:获取所有的值列表
s.index:获取所有的行索引列表
s['a'] :访问索引为'a'的元素
s[0] : 访问第1个元素
s[['a', 'b']]:访问索引为a和b的两个元素
s[:2]:访问前两个元素
5、DataFrame对象的生成
pd.DataFrame(data, index, column)
data数据类型:列表嵌套的列表,列表组成的字典,Series组成的字典,字典组成的字典等
index:行索引列表
column:列索引列表
行索引和列索引都可以为为空,pandas会自动以0,1,2,...等为它创建索引
1)以列表嵌套列表的方式生成DataFrame,外层列表长度表示行数,内层列表最大长度表示列数

2)以列表组成的字典,列表长度需要相同,将会默认以字典的key作为列索引

3)Series组成的字典生成DataFrame

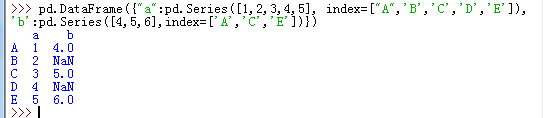
以字典形式生成的DataFrame对象,会以key的并集作为列索引,index的并集作为行索引,不存在的赋值为NaN
6、DataFrame对象的读取
df.index:获取行索引列表
df.values:获取值列表
df.columns:获取列索引列表
df.a/ df['a']:获取列索引为first的元素
df[0:1]:获取第一行元素
df[:3]:获取前三行元素
df.loc[:, :]:访问所有行,所有列元素
df.loc[:, ['a', 'b']]:访问所有行,列为a和b的元素
df.loc[['a'], ['b']]:访问行为a,列为b的元素
df.iloc[:,:]:访问所有行,所有列元素
df.iloc[0:2, :2]:访问前两行,前两列元素
df.iloc[[0,2], 0:2]:访问第1行,第3行及前两列元素
df.ix[:,:]:访问所有行,所有列元素
df.ix[:2, ['a','b']]:访问前两行,列索引为a和b的元素
df.ix[df.a>1, :2]:访问所有列索引为a的元素中,大于1的元素的行和前两列的元素
7、下面我们以股票交易数据为例来分析:
我这里有一个csv格式的近两年来的股票数据( table.csv )
1)读取csv文件
df = pd.read_csv("C:\Users\admin\Desktop\table.csv",parse_dates=True, header=0,index_col=0,encoding="gb2312")
2)数据内容查看方法:
df.head(n):查看前n行数据
df.tail(n):查看后n行数据
df.columns:查看所有的索引列列表
df.index:查看所有的行索引列表
df.values:查看所有的值列表
df.shape:查看行数和列数
df.describe():查看基本信息,如总条数,最小值,最大值,平均数等
df.info():可以查看有几条非空数据
df.isnull():查看所有数据是否为空
df[df.isnull().T.any()]:查看含有空元素的行
df.fillna(method='bfill', axis=0, inplace=True):用下一行的数据替换掉NaN(用上一行method='ffill', 指定值替换用value=指定值)
3、特殊值处理方法
df.round(n):四舍五入,保留n位小数
df.astype(type):按照指定的格式转换数值
df.Volume.astype(int):将volume列的数值转换为int类型
applymap:可以搭配lambda使用,做数据格式转换
df.applymap(lambda x: '%0.2f' % x):保留两位小数
df.ix[:, ['Volume']].apply(lambda x: '%0.0f' % x):保留0位小数
df[df.values==0]:查找值为0的数据
df.loc[df.loc[:, high]==0, 'High'] = df.High.median():将High列为0的数值替换为High列的中间值