子查询是强有力的工具,它可以书写许多表达式和许多复杂的查询。有很多不同类型的子查询和很多使用子查询的不同方式。
子查询是基本的连接。然而,一些子查询产生更复杂的连接使用非常不同寻常的连接特性。
在讨论具体例子之前,可以从不同方面对子查询进行分类。子查询采用3种计划来进行分类。
l 不相关 vs 相关子查询。不相关子查询不依赖外部查询,可以独立于外部查询而被评估,并且为外部查询的每一行返回相同的结果。只能从外部查询的上下文中来被估计,并且可能为外部查询的每一行返回不同的结果。
l 标量 vs 多行子查询。标量子查询返回或期望返回单一行(也就是单行),然而,多行子查询可能返回一个结果集。
l 有子查询出现的外部查询分句。子查询可以被用于几乎所有的上下文,包括SELECT列表和主查询中的FORM、WHERE、ON和HAVING子句。
不相关标量子查询
通过一些简单的不相关标量子查询来讨论子查询。下面的查询返回运费超过所有订单运费平均值的订单列表。
SELECT o1.[OrderId], o1.[Freight]
FROM [Orders] o1
where o1.[Freight] >
(
select AVG(o2.Freight) from [Orders] o2
)
注意到我们可以提取平均费用计算子句并作为完全独立的查询来执行。因此,这个子句查询不相关。同时,这个子查询使用了标量汇总,因此,返回正好是一行,这个子查询也是一个标量子查询。下面是这种查询计划:

正如你期望的,SQL Server首先计算嵌套循环连接外面的平均运费来执行这个查询。这个查询需要对Order表(alias[O2])执行一次扫描。因为这个查询计算得到精确的一行,SQL Server然后在内部连接上扫描Order表(alias[O1])一次。平均的运费计算结果被子查询(存储在[Expr1004]里)用来过滤来自第二次扫描的行。
另外,还有一种不相关标量子查询。这次希望找的哦啊那些已经根据名字选择的特定用户的订购订单。
SELECT o.[OrderId]
FROM [Orders] o
where o.[CustomerID] >
(
select C.[CustomerID] from [Customers] C
where C.[ContactName] = 'Maria Anders'
)
注意到这次子查询没有标量汇总来保证结果恰好是一行。此外ContactName上没有唯一索引,所以这个子查询实际返回多行是完全可能的。然而,该子查询被用在一个相等谓词上下文,是一个标量子查询,且必须返回单行。如果有两个客户都叫“Maria Anders”(没有这样的名字),这个查询一定失败。SQL Server保证子查询结果最多有一行,这是通过使用流汇总来计算行数的,然后给改计划添加一个断言操作:

如果断言操作符发现子查询返回多于一行(也就是说,如果[Expr1005]>(1)是真),将引发错误。
当子查询被当用一个表达式时,这是不被允许的。
注意到SQL Server使用断言操作符来检测其他条件,例如,约束条件(检查,参照完整性等),普通表达式的最大递归层次,警告重复键插入到建立在IGNORE_DUP_KEY选项的索引上。
ANY聚合是一种特殊的内部唯一聚合,返回任何行。因为这种计划如果扫描Customers表结果集多余一行将产生一个错误,对ANY汇总没有实际的影响。这种计划可以简单地使用MIN或MAX聚合得到同样的结果。然而,一些聚合是必须的,因为流聚合期望每一个输出列在聚合里或在GROUP BY子句里。下面的查询因为同样的原因不能被编译:
select COUNT(*), C.[CustomerId]
from [Customers] C
where C.[ContactName] = 'Maria Anders'
选择列表中的列'Customers.CustomerID' 无效,因为该列没有包含在聚合函数或GROUP BY 子句中。
相关标量子查询
SQL Server如何评估简单的不相关子查询,让我们探讨如果有一个相关标量子查询和尝试的第一个子查询相似,但是这次返回的是那些超过所有先前加入订单费用的平均值订单。
这次SQL Server不能独立地执行子查询。因为关联到列OrderDate上,子查询为主查询中每一行返回不同的结果。SQL Server首先、评估子查询,然后执行主查询。这次SQL Server首先评估主查询,然后根据主查询中的每一行评估一次子查询。

这个计划不是很复杂。Index spool立即在[02]上进行扫描,是一种及时index spool或临近索引轴。在Orders Date列上创建一个临时索引。被叫做及时index spool,因此它“及时”装入整个输入集,并且一被打开就建立临时索引。
这个索引使得子查询随后的评估更加高效,因为在列OrderDate上有一个谓词。流汇总为每一个子查询来计算平均运费。在流汇总上的索引spool是一个延迟的索引spool,它仅仅缓存子查询的结果。如果再次遇到任何OrderDate,将返回保存在缓存里的结果而不是重新计算子查询。它被叫做延迟的spool,因为“以延迟方式”只装载需要的结果。最后,最上面计划的过滤器与子查询结果集([Expr1004])的每一个订单进行运费比较,并返回满足要求的行。
下面是其他相关标量子查询的例子。假设要找到被同一个客户加入的超过所有订单平均值的订单。
SELECT o1.[OrderId], o1.[Freight]
FROM [Orders] o1
where o1.[Freight] >
(
select AVG(o2.[Freight]) from [Orders] o2
where o2.[CustomerID] = o1.[CustomerID]
)
这个查询和前面一个非常相似,但却得到一个本质上完全不同的计划:
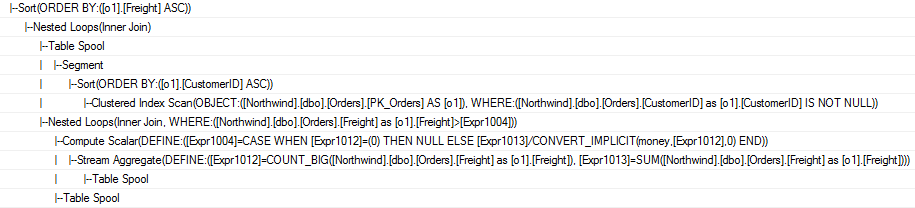
再次这个计划也不复杂。最外层的嵌套循环连接根据列CustomerId对聚集索引扫描的行进行分类。段操作符列CustomerId有相同值的行分成组(或段)。因为这些行都是被排序的,具有相同CustomerId值的行的集合将是连续的。接下来,表spool—一个段spool-读并保存其中一组拥有相同CustomerId值的行。
当spool完成载入一组行时,将为这个组返回单一的行(注意到段spool是唯一一种展示这种行为的spool类型,它不考虑读入多少行,而只显示单一的行)。这是最外层的嵌套循环连接执行内部的输入。两个页级表spools—-从属的spools—-重新执行原始段spool保存的组内的行。
通过使用段 spool,优化器创建一种仅需要扫描表Orders一次的计划。谈到spool时,有这样一个例子,在这种计划里重新计算在不同位置的相同行的集合作为一个普通的子表达式spool。不是所有的普通子查询spools都是段spools。