- elasticsearch(双节点)我准备了两台服务器 160(es node1 + kibana ) 和161(es node2)
- 如下图是需要的资源文件
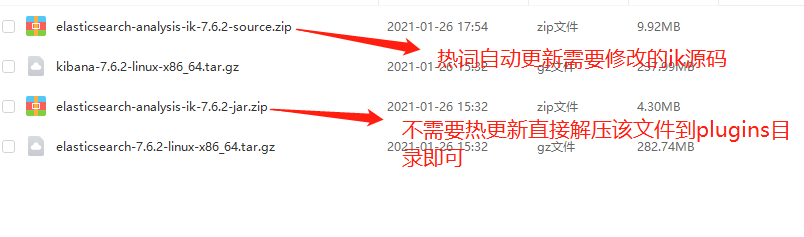
注意es kibana ik 版本要相同
修改/etc/security/limits.conf文件 增加配置
vi /etc/security/limits.conf * soft nofile 65536 * hard nofile 65536
在/etc/sysctl.conf文件最后添加一行 vm.max_map_count=655360 添加完毕之后,执行命令: sysctl -p
es默认必须用非root用户执行,所以将解压的es文件夹下所有文件交给非root用户:vi /etc/sysctl.conf sysctl -p
chown -R esuser.esuser ./es
切换用户,更改配置文件
su esuser - es node1 配置文件内容:
cluster.name: elasticsearch_cluster node.name: node-1 node.master: true node.data: true http.port: 9200 network.host: 0.0.0.0 network.publish_host: 192.168.209.160 discovery.zen.ping.unicast.hosts: ["192.168.209.160","192.168.209.161"] http.host: 0.0.0.0 http.cors.enabled: true http.cors.allow-origin: "*" bootstrap.memory_lock: false bootstrap.system_call_filter: false ## Uncomment the following lines for a production cluster deployment transport.tcp.port: 9300 cluster.initial_master_nodes: ["node-1","node-2"] discovery.zen.minimum_master_nodes: 1
es node2 配置文件内容:
cluster.name: elasticsearch_cluster node.name: node-2 node.master: true node.data: true http.port: 9200 network.host: 0.0.0.0 network.publish_host: 192.168.209.161 discovery.zen.ping.unicast.hosts: ["192.168.209.160","192.168.209.161"] http.host: 0.0.0.0 http.cors.enabled: true http.cors.allow-origin: "*" bootstrap.memory_lock: false bootstrap.system_call_filter: false ## Uncomment the following lines for a production cluster deployment transport.tcp.port: 9300 cluster.initial_master_nodes: ["node-1","node-2"] discovery.zen.minimum_master_nodes: 1
启动es:./elasticsearch
浏览器显示如下信息,es启动成功
{ "name" : "node-1", "cluster_name" : "elasticsearch_cluster", "cluster_uuid" : "zEUud3P4RWG6bFVvIAZUag", "version" : { "number" : "7.6.2", "build_flavor" : "default", "build_type" : "tar", "build_hash" : "ef48eb35cf30adf4db14086e8aabd07ef6fb113f", "build_date" : "2020-03-26T06:34:37.794943Z", "build_snapshot" : false, "lucene_version" : "8.4.0", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search" }
-
kibana配置文件内容(直接解压即可运行):
i18n.locale: "zh-CN" #开启中文界面 server.host: "192.168.209.160" elasticsearch.hosts: ["http://192.168.209.160:9200"]
kibana控制台执行如下语句:
GET _analyze { "analyzer":"ik_max_word", "text":"我叫冯文哲" }

然后就是动态新增热词了:ik支持http访问远程热词库,但是性能损耗很大,我们直接通过修改Ik源代码实现数据库热词动态更新
官网下载对应版本的source(本身就是一个maven工程),直接导入项目中,为了加快导入速度,可以直接将工程的pom.xml文件中的oss.sonatype.org地址改为阿里云的仓库地址:
https://maven.aliyun.com/repository/central
如果pom.xml头部报错,直接将本地仓库对应的jar包文件夹删除,重新下载一份
ik项目中需要修改的地方:
1:pom.xml修改版本号
2:config文件夹新增文件:hot-dic-db-source.properties并添加如下内容:
db.url=jdbc:mysql://192.168.1.105:3306/hotdic?useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT%2B8&useSSL=false&allowPublicKeyRetrieval=true db.username=root db.password=root db.reload.mainhotdic.sql=select word from tb_main_hot_dic db.reload.stopworddic.sql=select word from tb_stopword_dic
db.reload.removeworddic.sql=select word from tb_removeword_dic
3:plugin.xml新增mysql依赖:
<dependencySet>
<outputDirectory/>
<useProjectArtifact>true</useProjectArtifact>
<useTransitiveFiltering>true</useTransitiveFiltering>
<includes>
<include>mysql:mysql-connector-java</include>
</includes>
</dependencySet>
Dictionary类中新增如下内容:
private static ScheduledExecutorService hotDictionarytaskPool = Executors.newScheduledThreadPool(1);
public void loadHotDictionary() { /** * 自定义远程词库加载方法,相当于加载main.dic */ this.loadMainHotDicFromDB(); /** * 加载自定义停用词库,中文介词 */ this.loadStopwordDicFromDB();
/**
* 删除_MainDict _StopWords 中的指定内容
*/
this.removeStopwordAndMainHotDicFromDB(); } /** * 用于记录配置文件 * */ private static Properties properties = new Properties(); /** * 一般来说,商业环境中,不会轻易修改数据库,所以注册JDBC驱动使用的是强编码 */ static { try { logger.info("regist database driver"); DriverManager.registerDriver(new com.mysql.jdbc.Driver()); } catch (Exception e) { // TODO: handle exception logger.error("regist database driver error: ", e); } }
private void removeStopwordAndMainHotDicFromDB() {
Connection connection = null;
Statement stmt = null;
ResultSet rs = null;
try {
/**
* getDictRoot() - Dictionary类中定义的一个用于获取IK基础路径的方法,就是$ES_HOME/plugins/ik
*/
Path file = PathUtils.get(getDictRoot(), "hot-dic-db-source.properties");
properties.load(new FileInputStream(file.toFile()));
logger.info("properties info :" + properties);
connection = DriverManager.getConnection(properties.getProperty("db.url"),
properties.getProperty("db.username"), properties.getProperty("db.password"));
logger.info("connection info :" + connection);
stmt = connection.createStatement();
logger.info("The sql for query remove word dictionary :"
+ properties.getProperty("db.reload.removeworddic.sql"));
rs = stmt.executeQuery(properties.getProperty("db.reload.removeworddic.sql"));
while (rs.next()) {
String word = rs.getString("word");
logger.info("remove word from DB: " + word);
/**
* _MainDict : 是IK中Dictionary类型中定义的一个变量,用于在内存中保存词典信息的 对应的是main.dic中的内容
*/
_MainDict.disableSegment(word.trim().toCharArray());
_StopWords.disableSegment(word.trim().toCharArray());
}
} catch (Exception e) {
// TODO: handle exception
logger.error("error:" + e);
} finally {
if (rs != null) {
try {
rs.close();
} catch (Exception e) {
// TODO: handle exception
logger.error("JDBC ResultSet Closing Error : ", e);
}
}
if (stmt != null) {
try {
stmt.close();
} catch (Exception e) {
// TODO: handle exception
logger.error("JDBC Statement Closing Error : ", e);
}
}
if (connection != null) {
try {
connection.close();
} catch (Exception e) {
// TODO: handle exception
logger.error("JDBC Connection Closing Error : ", e);
}
}
}
}
private void loadMainHotDicFromDB() { Connection connection = null; Statement stmt = null; ResultSet rs = null; try { /** * getDictRoot() - Dictionary类中定义的一个用于获取IK基础路径的方法,就是$ES_HOME/plugins/ik */ Path file = PathUtils.get(getDictRoot(), "hot-dic-db-source.properties"); properties.load(new FileInputStream(file.toFile())); logger.info("properties info :" + properties); connection = DriverManager.getConnection(properties.getProperty("db.url"), properties.getProperty("db.username"), properties.getProperty("db.password")); logger.info("connection info :" + connection); stmt = connection.createStatement(); logger.info("The sql for query main hot dictionary :" + properties.getProperty("db.reload.mainhotdic.sql")); rs = stmt.executeQuery(properties.getProperty("db.reload.mainhotdic.sql")); while (rs.next()) { String word = rs.getString("word"); logger.info("hot word from DB: " + word); /** * _MainDict : 是IK中Dictionary类型中定义的一个变量,用于在内存中保存词典信息的 对应的是main.dic中的内容 */ _MainDict.fillSegment(word.trim().toCharArray()); } } catch (Exception e) { // TODO: handle exception logger.error("error:" + e); } finally { if (rs != null) { try { rs.close(); } catch (Exception e) { // TODO: handle exception logger.error("JDBC ResultSet Closing Error : ", e); } } if (stmt != null) { try { stmt.close(); } catch (Exception e) { // TODO: handle exception logger.error("JDBC Statement Closing Error : ", e); } } if (connection != null) { try { connection.close(); } catch (Exception e) { // TODO: handle exception logger.error("JDBC Connection Closing Error : ", e); } } } } private void loadStopwordDicFromDB() { Connection connection = null; Statement stmt = null; ResultSet rs = null; try { /** * getDictRoot() - Dictionary类中定义的一个用于获取IK基础路径的方法,就是$ES_HOME/plugins/ik */ Path file = PathUtils.get(getDictRoot(), "hot-dic-db-source.properties"); properties.load(new FileInputStream(file.toFile())); logger.info("properties info :" + properties); connection = DriverManager.getConnection(properties.getProperty("db.url"), properties.getProperty("db.username"), properties.getProperty("db.password")); logger.info("connection info :" + connection); stmt = connection.createStatement(); logger.info( "The sql for query main hot dictionary :" + properties.getProperty("db.reload.stopworddic.sql")); rs = stmt.executeQuery(properties.getProperty("db.reload.stopworddic.sql")); while (rs.next()) { String word = rs.getString("word"); logger.info("stop word from DB: " + word); /** * _MainDict : 是IK中Dictionary类型中定义的一个变量,用于在内存中保存词典信息的 对应的是main.dic中的内容 */ _StopWords.fillSegment(word.trim().toCharArray()); } } catch (Exception e) { // TODO: handle exception logger.error("error:" + e); } finally { if (rs != null) { try { rs.close(); } catch (Exception e) { // TODO: handle exception logger.error("JDBC ResultSet Closing Error : ", e); } } if (stmt != null) { try { stmt.close(); } catch (Exception e) { // TODO: handle exception logger.error("JDBC Statement Closing Error : ", e); } } if (connection != null) { try { connection.close(); } catch (Exception e) { // TODO: handle exception logger.error("JDBC Connection Closing Error : ", e); } } } }
Dictionary类的initial方法中新增如下内容:
hotDictionarytaskPool.scheduleAtFixedRate(new HotDicLoadingTask(), 10, 5, TimeUnit.SECONDS); //定时查询数据库,实际应用中时间可以设置长一些
然后打包项目:
mvn clean package
然后就可以当插件直接解压到linux的plugins目录下了(如果无法连接mysql数据库,请检查是否是数据库权限未开启)
SHOW GRANTS FOR 'root'@'%' GRANT ALL PRIVILEGES ON `hotdic`.* TO 'root'@'%'
重新启动es可能会报错,因为jdk外部引用有权限问题,修改es目录下的/jdk/conf/security/java.policy
添加如下内容:
permission java.lang.RuntimePermission "createClassLoader"; permission java.lang.RuntimePermission "setContextClassLoader"; permission java.lang.RuntimePermission "getClassLoader"; permission java.net.SocketPermission "192.168.1.105:3306","connect,resolve";
ip换成自己的真实ip
数据库创建三张表(还有张tb_removeword_dic//重置hot 和stop 表中的热词)

tb_main_hot_dic表中新增数据:我叫冯文哲

动态更新热词成功,想禁用就在另一张表中加,如果一个词禁用后想再启用,就在tb_removeword_dic表中加入该词(重置数据)(ik必须部署在所有的es节点上)。
动态更新热词后,想要之前的数据生效必须重建索引(后插入的数据可以查询到),重建索引方法:
创建一个格式一样的索引
PUT /fwztest2_index {"settings": {"number_of_replicas": 1,"number_of_shards": 5} , "mappings": {"properties":{"author_id":{"type":"long"},"title":{"type":"text","analyzer":"standard","fields":{"keyword":{"type":"keyword","ignore_above":256}}},"content":{"type":"text","analyzer":"ik_max_word","fields":{"keyword":{"type":"keyword","ignore_above":256}}},"create_date":{"type":"date"}}} }
执行_reindex方法
POST _reindex { "source": { "index": "fwztest_index" }, "dest": { "index": "fwztest2_index" } }