一、收缩索引
1、介绍
在大型的集群中,索引的分片也往往比较多,但是随着时间的推移,有一些索引慢慢的就会由“热”变“冷”,到最终基本上不再使用;还有一些索引,它本身的索引文档的数据量并不多,但是却还是使用了不少的分片。如果不对这些索引进行管理,这些索引的分片信息就会一直被集群所维护着,集群主节点维护分片的压力就会越来越大,如果是涉及到集群恢复,也会耗费更多的时间。
Elasticsearch本身提供了集群收缩的shrink API来执行这方面的操作,但不是针对源索引执行操作,它会创建一个和源索引除主分片数不一样的目标索引来存储数据,在收缩完成后,源索引就可以被删除了,这样就达到索引收缩的目的。
索引收缩工作过程
- 创建一个新的目标索引,其定义与源索引相同,只是主分片数量较少;
- 将源索引中的段硬链接到目标索引(如果文件系统不支持硬链接,则会将所有段复制到新索引中,这是一个更耗时的过程);
- 恢复目标索引,像重新打开一个关闭的索引一样;
索引被收缩需要满足的条件
- 目标索引必须是不存在;
- 源索引必须被设置为只读状态;
- 当前集群的健康状态须为绿色;
- 源索引必须比目标索引有更多的主分片数;
- 目标索引中的主分片数,必须是源索引的一个因子,或者可以理解为目标索引的分片数可以被源索引整除。如源索引有8个主分片,则目标索引的主分片可以是4个、2个或1个,如源索引有15个主分片本,则目标索引的主分片可以是5个、3个或1个,如源索引的主分片数是一个素数,如7个,则目标索引的主分片数则只能够是1个;
- 源索引的所有索引文档数量如果超过了2,147,483,519个,则不能够将其收缩为只有一个主分片的目标索引中,因为这已经超过了单个分片所能够存放的最大的索引文档数;
- 用于执行索引收缩的节点,必须有足够的硬盘空间,以便于存储新的索引;
- 在执行索引的收缩之前,需要确保当前索引的所有分片(分片可以是主分片或副本)必须存在于同一个节点之前,因而在执行索引的收缩之前,需要先执行分片的移动。如被收收缩的索引有5个主分片,其中有3个主分片:主分片1、主分片2、主分片3,和2个副本:副本4和副本5都已经迁移到了同一个节点上,则这个时候才可以执行索引的收缩操作。
下面是针对具有5个主分片1个副本的索引new_index的收缩过程,new_index所在的索引包括了三个节点:es-learnnode-1、es-learnnode-2和es-learnnode-3,使用节点es-learnnode-1来执行收缩操作,此时new_index的分片在集群中是如下分布的:

2、移动分片并设置源节点为只读状态
|
PUT /new_index/_settings { "settings": { "index.routing.allocation.require._name": "es-learnnode-1", "index.blocks.write": true } } |
该操作强制将new_index的每个分片的一份(可能是主分片或副本)都移动到了节点es-learnnode-1上,并将new_index设置为只读。
如果响应为:
|
{ "acknowledged" : true } |
则表示操作执行成功。
如果索引中索引文档的数量比较多,这个操作将会花费一定的时间,移动完成后,可以在head插件上直接观察到分片的分布情况,如下图所示:
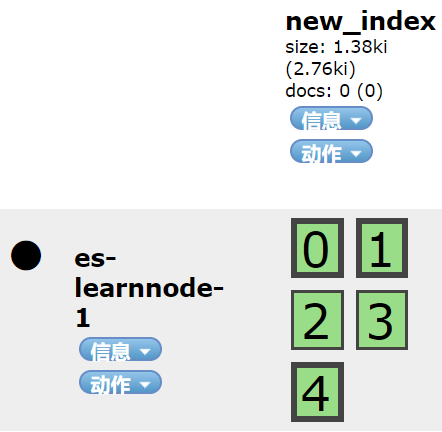
![]()
3、执行索引的收缩
执行如下请求:
|
POST /new_index/_shrink/new_index_target { "settings": { "index.routing.allocation.require._name": null, "index.blocks.write": null } } |
该操作执行了以下几个动作:
- 执行索引的压缩;
- 通过设置index.routing.allocation.require._name的值为null,清除了目标库中从源索引中带过来的强制索引分片的每一份都分配置到指定节点设置;
- 通过设置index.blocks.write属性,清除了目标库中从源过引库带过来的拒绝写入的设置;
响应如果为:
|
{ "acknowledged" : true, "shards_acknowledged" : true, "index" : "new_index_target" } |
则表示操作执行成功,再查看集群中的索引,发现目标索引new_index_target已经建立成功了。
上面执行的收缩过程中,创建了一个新的索引,其实这本身也确实是一个创建索引的过程,此时也可以指定一些参数目标索引,如指定主分片数(一定要注意目标索引的主分片数可以被源索引的主分片数给整除,且小于源索引的主分片数)和副本数、别名等,如下示例:
|
POST /new_index/_shrink/new_index_target { "settings": { "index.routing.allocation.require._name": null, "index.blocks.write": null, "number_of_shards":1, "number_of_replicas" : 2, "index.codec": "best_compression" } } |
注:mapping不可以在索引收缩的过程中指定。
这里举一个错误的示例,如果这里将目标索引的主分片数设置为2,则会报如下异常:
|
{ "error": { "root_cause": [ { "type": "remote_transport_exception", "reason": "[es-learnnode-2][indices:admin/resize]" } ], "type": "illegal_argument_exception", "reason": "the number of source shards [5] must be a multiple of [2]" }, "status": 400 } |
二、索引的拆分
1、介绍
索引可以被拆分的次数(以及每个原始分片可以拆分成的分片数)由路由分片的数量设置index.number_of_routing_shards的值确定,拆分后的总分片数不能够超过该值,路由分片的数量指定了内部可使用的最大散列空间,以便在具有一致性散列的分片中分发文档。例如,一个具有5个索引分片的索引其路由分片数量number_of_routing_shards设置为30,则可以按因子2或3分割。换句话说,它可以按如下方式拆分:
|
5→10→30(每个分片先拆分成2个,然后再把拆分后的分片每个拆分成3个) 5→15→30(每个分片先拆分成3个,然后再把拆分后的分片每个拆分成2个) 5→30(每个分片拆分成6个) |
路由分片数量的默认值为1024,也就是索引分片最多可以被拆分成1024个,但是这个还取决于原始主分片的数量。如原始主分片只有1个,则原始分片可被拆分成1-1024中任意数量的主分片数;如原始主分片的数量为5个,则主分片被拆分成的数量可以是10、20、40、80、160、320或最多640个分片,要达到最多的640个分片,可以通过一次拆分或者通过多次拆分。
也可以在创建索引时显式通过指定参数index.number_of_routing_shards进行设置,如下所示:
|
PUT /new_index_2 { "settings": { "number_of_shards":2, "number_of_replicas" : 2, "index.number_of_routing_shards": "1000" } } |
拆分的工作过程
- 创建一个新的目标索引,其定义与源索引相同,但主分片数量比源索引多;
- 将源索引中的段硬链接到目标索引(如果文件系统不支持硬链接,则会将所有段复制到新索引中,这是一个比硬链接耗时的多过程);
- 创建低级文件后,将再次对所有文档进行哈希处理,以删除不属于当前分片的文档;
- 恢复了目标索引,像重新打开原来关闭的索引一样;
索引可以被拆分的条件
- 索引需要被设置为只读;
- 当前集群的健康状况须为绿色;
- 目录索引必须是不存在的;
- 源索引的主分片须小于目标索引的主分片数;
- 目标索引的主分片数须是源索引分片数的倍数;
- 用于执行拆分的节点须有足够的硬盘空间,以便于保留拆分出来的新的索引;
还是以有5个主分片1个副本的索引new_index为例。
2、将源索引设为只读状态
执行如下语句:
|
PUT /new_index/_settings { "settings": { "index.blocks.write": true } } |
响应:
|
{ "acknowledged" : true } |
表示执行成功,将索引new_index设置为只读状态。
3、索引拆分
将目标索引的主分片数设置为源索引的2倍即10个,执行如下语句:
|
POST /new_index/_split/new_index_split { "settings":{ "index.number_of_shards":10 } } |
响应:
|
{ "acknowledged" : true } |
表示执行成功,再查看elasticsearch-head中new_index和new_index_split的集群分片分布如下:
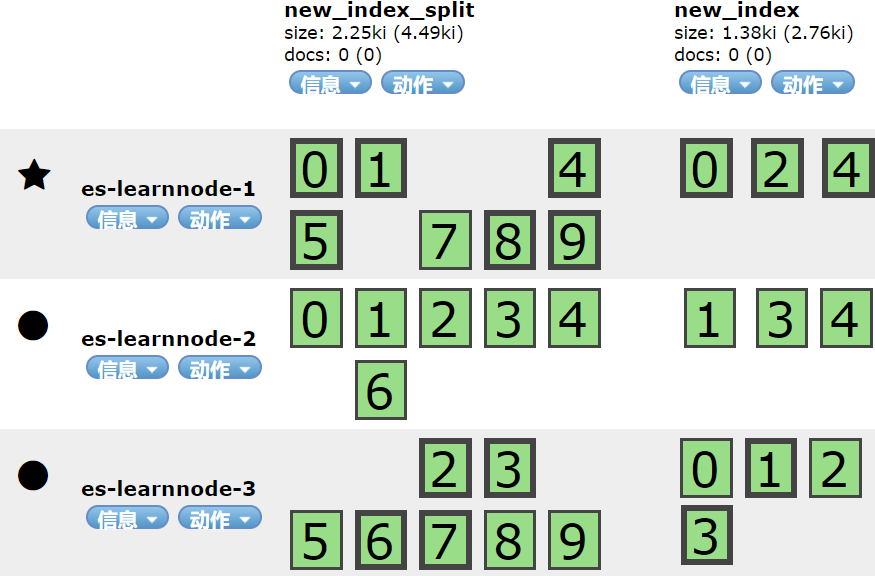
![]()
可以看到new_index_split的分片数量已经是new_index的2倍了,再次确认执行拆分成功。
以下执行一下错误的示例,把目标索引的主分片数量设置为不是源索引主分片数量的倍,如设置为11个,则会报如下错误信息:
|
{ "error": { "root_cause": [ { "type": "illegal_argument_exception", "reason": "the number of source shards [5] must be a factor of [11]" } ], "type": "illegal_argument_exception", "reason": "the number of source shards [5] must be a factor of [11]" }, "status": 400 } |