RDD创建:
从从文件系统中加载数据创建RDD:
1.Spark采用textFile()从文件系统中加载数据创建RDD 可以使本地,分布式系统等
2.把文件的url作为参数 可以是本地文件系统的地址,分布式文件系统HDFS的地址等等
从本地文件中加载数据:
sc为系统自动创建的sparkcontext,不用我们创建

从文件word.txt中加载数据生成RDD
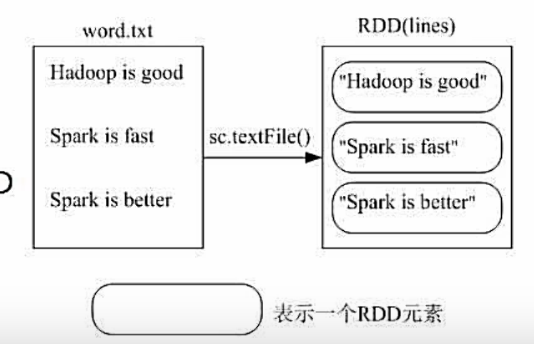
从分布式文件系统HDFS加载数据:
与上面同理,改变路径,注意端口号不一样
![]()

这三个是等价的,因为它会默认在用户登录的HDFS下寻找文件
RDD操作:
转换操作:
1.对于RDD来说每次转换都会生成不同的RDD,供一个操作使用
2.转换操作得到的RDD是惰性求值的,整个转换过程只是记录了转换的轨迹,并不会真正发生计算,只有遇到行动操作时才会发生计算。
常见的转换操作:
filter(func):筛选出满足函数func的元素,并返回一个新的数据集
map(func):将每个元素传递到函数func中,并将结果返回一新的数据集
flatMap(func):与map()相似,但是每个输入的元素都可以映射到0或多个输出结果
groupByKey():应用于(K,V)键值对的数据集时,返回一个新的(k,Iterable)形式的数据集
reduceByKey(func):应用于(K,V)键值对的数据集时,返回一个新的(K,V)形式的数据集,其中每个值是将每个key传递到函数func中聚合
行动操作:
行动操作是真正触发计算的地方。Spark程序执行到行动操作时,才会执行真正的计算,从文件中加载数据,完成一次又一次转换操作,最终,计算得到结果。
count()返回集合中元素个数
collect()以数组的形式返回数据集中所有元素
first()返回数据集中的第一个元素
take(n)以数组的形式返回数据集中的前n个元素
reduce(func)通过函数func(输入两个参数并返回一个值)聚合数据集中的元素
foreach(func)将数据集中的每个元素传递到函数func中运行
惰性机制:

第三行代码的reduce()方法是一个“行动(Action)”类型的操作,这时,就会触发真正的计算
这时,Spark会把计算分解成多个任务在不同的机器上执行,每台机器运行属于它自己的map和reduce,最后把结果返回给Driver