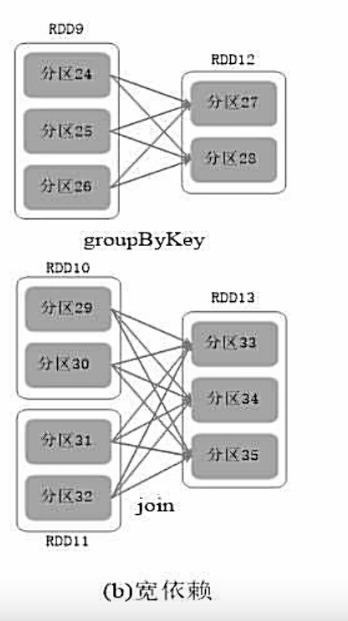
窄依赖与宽依赖的区别:
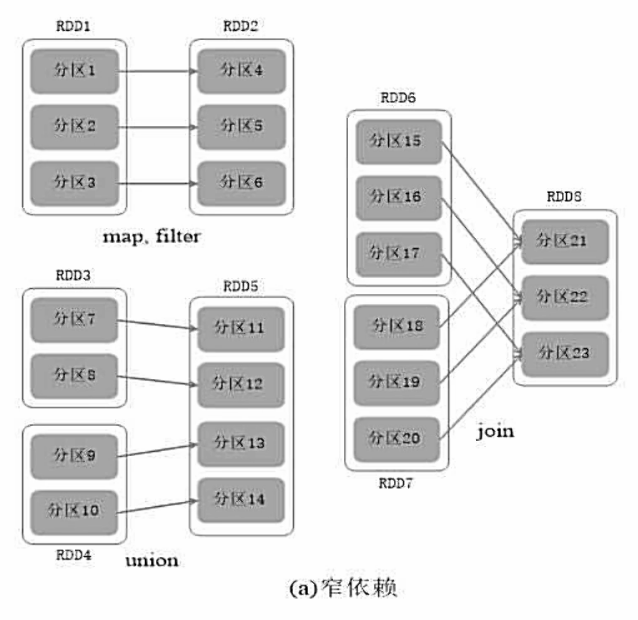
窄依赖:表现为一个父RDD的分区对应于一个子RDD的分区或多个父RDD的分区对应于一个子RDD的分区
宽依赖:表现为存在一个父RDD的一个分区对应一个子RDD的多个分区
Stage的划分:
Spark通过分析各个RDD的依赖关系生成了DAG再通过分析各个RDD中的分区之间的依赖关系来决定如何划分Stage
根据RDD分区的依赖关系划分Stage:
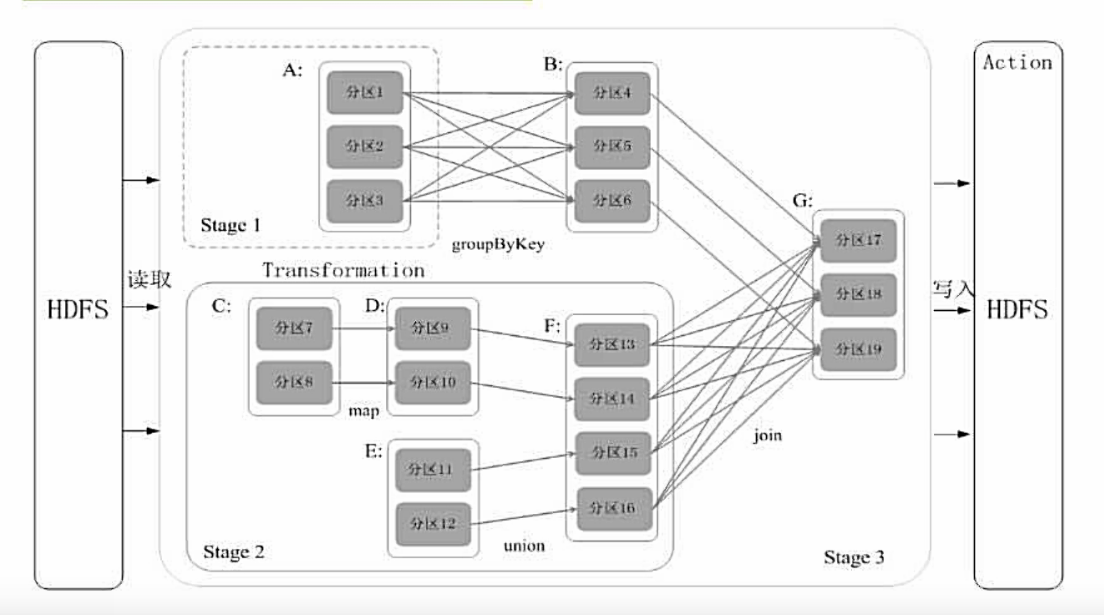
Stage的划分:
- 在DAG中进行反向解析,遇到宽依赖就断开
- 遇到窄依赖就把当前的RDD加入到Stage中
- 将窄依赖尽量划分在同一个Stage中,可以实现流水线计算
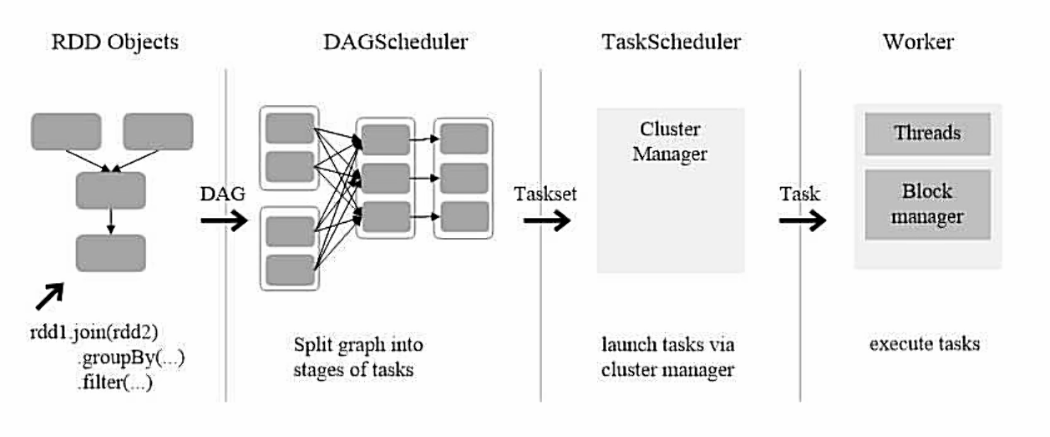
RDD运行过程:
- 创建RDD对象
- SparkContext负责计算RDD之间的依赖关系,构建DAG
- DAGScheduler负责把DAG图分解成多个Stage每个Stage中包含了多个Task每个Task会被TaskScheduler分发给各个WorkerNode上的Executor去执行
RDD在Spark中的运行过程: