主要记录自己踩到坑,空指针异常!
实验报告代码如下:
package Mapreduce; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.log4j.BasicConfigurator; public class Filter { public static class Map extends Mapper<Object , Text , Text , NullWritable>{ private static Text newKey=new Text(); public void map(Object key,Text value,Context context) throws IOException, InterruptedException{ String line=value.toString(); System.out.println(line); String arr[]=line.split(","); newKey.set(arr[1]); context.write(newKey, NullWritable.get()); System.out.println(newKey); } } public static class Reduce extends Reducer<Text, NullWritable, Text, NullWritable>{ public void reduce(Text key,Iterable<NullWritable> values,Context context) throws IOException, InterruptedException{ context.write(key,NullWritable.get()); } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{ System.setProperty("hadoop.home.dir", "D:\\qqdata\\1345272421\\FileRecv\\建民\\Mapreduce实验\\hadoop-common-2.2.0-bin-master"); Configuration conf=new Configuration(); BasicConfigurator.configure(); //自动快速地使用缺省Log4j环境 System.out.println("start"); Job job =Job.getInstance(conf,"word count"); job.setJarByClass(Filter.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); Path in=new Path("hdfs://hadoop102:8020/mymapreduce2/in/buyer_favorite1"); Path out=new Path("hdfs://hadoop102:8020/mymapreduce2/out3"); FileInputFormat.addInputPath(job,in); FileOutputFormat.setOutputPath(job,out); try { job.waitForCompletion(true); //这里的为true,会打印执行结果 } catch (ClassNotFoundException | InterruptedException e) { e.printStackTrace(); } } }
1.首先一个问题是日志生成不了:
添加BasicConfigurator.configure(); //自动快速地使用缺省Log4j环境
并新建如下文件夹
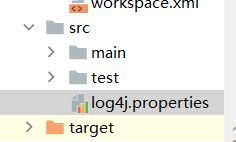
文件中加入:
### 设置### log4j.rootLogger = debug,stdout,D,E ### 输出信息到控制抬 ### log4j.appender.stdout = org.apache.log4j.ConsoleAppender log4j.appender.stdout.Target = System.out log4j.appender.stdout.layout = org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n ### 输出DEBUG 级别以上的日志到=E://logs/error.log ### log4j.appender.D = org.apache.log4j.DailyRollingFileAppender log4j.appender.D.File = E://logs/log.log log4j.appender.D.Append = true log4j.appender.D.Threshold = DEBUG log4j.appender.D.layout = org.apache.log4j.PatternLayout log4j.appender.D.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n ### 输出ERROR 级别以上的日志到=E://logs/error.log ### log4j.appender.E = org.apache.log4j.DailyRollingFileAppender log4j.appender.E.File =E://logs/error.log log4j.appender.E.Append = true log4j.appender.E.Threshold = ERROR log4j.appender.E.layout = org.apache.log4j.PatternLayout log4j.appender.E.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
2.job.waitForCompletion(true);报空指针异常
自己在网上找了很多解决方案,也不知道那个起到了关键作用,都写上了:
(1)下载对应版本的hadoop.dll,winutils.exe(https://github.com/steveloughran/winutils )找对应的版本, 放到C:\Windows\System32下面
(2) 然后就会报错hadoop.home未设置,https://github.com/srccodes/hadoop-common-2.2.0-bin下载解压
增加用户变量HADOOP_HOME,值是下载的zip包解压的目录,然后在系统变量path里增加%HADOOP_HOME%\bin 即可。
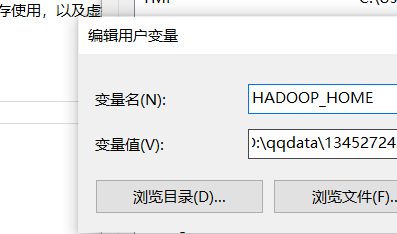
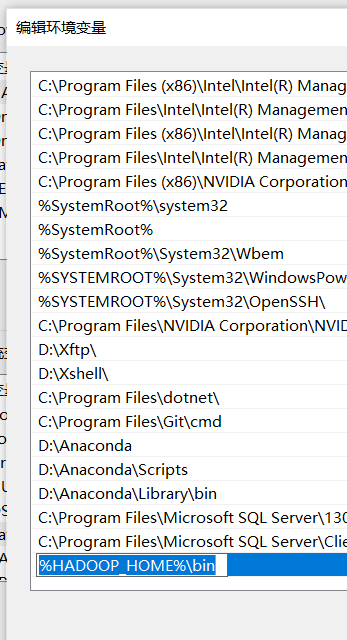
(3)结果发现还是不行,代码中加上
System.setProperty("hadoop.home.dir", "D:\\qqdata\\1345272421\\FileRecv\\建民\\Mapreduce实验\\hadoop-common-2.2.0-bin-master");
运行成功。
(4)还有一点 Path out=new Path("hdfs://hadoop102:8020/mymapreduce2/out3");中的地址不能存在,空文件夹也不行