将商家的特征值提取出来,转成CSV文件
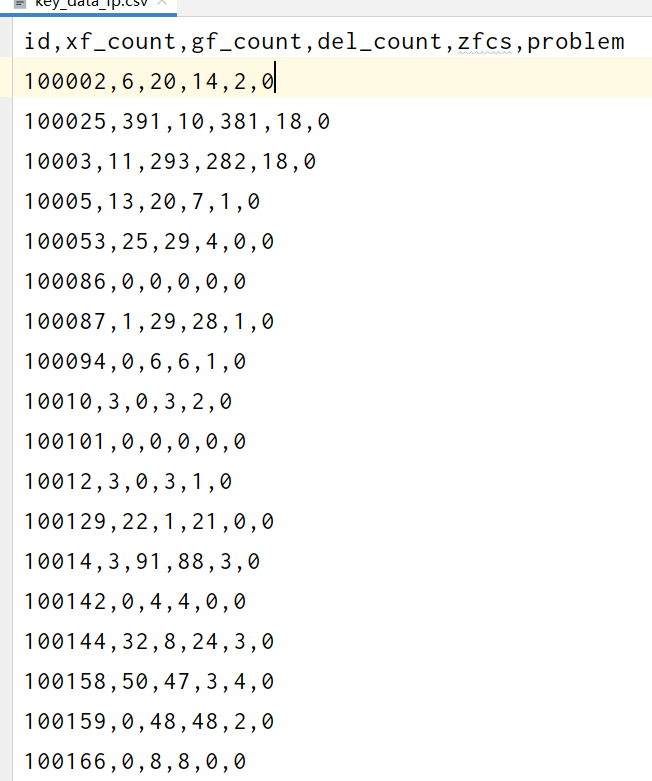
#问题企业决策树 def problem(): # 1.获取数据 data_titanic = pd.read_csv("key_data_fp.csv") # 2.获取目标值与特征值 x = data_titanic[[ "xf_count", "gf_count","del_count","zfcs"]] y = data_titanic["problem"] # 3.数据处理 # 1).缺失值处理 # x["age"].fillna(x["age"].mean(), inplace=True) # 填补处理dropna()删除缺失值所在的行 # 2).转换为字典 x = x.to_dict(orient="records") # 4.划分数据集 x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22) # 5.字典特征抽取 transfer = DictVectorizer() x_train = transfer.fit_transform(x_train) x_test = transfer.transform(x_test) # 6.决策树预估器 estimator = DecisionTreeClassifier(criterion="entropy") # criterion默认为gini系数,此处选择的为信息增益的熵 # max_depth:树深的大小,random_state:随机数种子 estimator.fit(x_train, y_train) # 7.模型评估 y_predict = estimator.predict(x_test) print("直接对比真实值和预测值: ", y_test == y_predict) score = estimator.score(x_test, y_test) print("准确率为: ", score) # # 8.决策树可视化 # export_graphviz(estimator, out_file="titanic_tree.dot", feature_names=transfer.get_feature_names()) # # 使用随机森林 # estimator = RandomForestClassifier()