由于业务需要调研数据湖的使用,这里以Hudi0.10为例,使用的是CDH6.2.1的集群。
一、编译Hudi0.10
在centos7上编译,需要配置maven,安装scala环境和docker环境,使用集群环境为CDH6.2.1
- maven配置
tar -zxvf apache-maven-3.6.1-bin.tar.gz -C /app
# 配置环境变量
export MAVEN_HOME=/app/apache-maven-3.6.1
export PATH=${MAVEN_HOME}/bin:$PATH# 添加阿里云的maven仓库
<mirror>
<id>alimaven</id>
<mirrorOf>central,!cloudera</mirrorOf>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</mirror> - 下载hudi0.10的源码包进行编译
# 修改packging/hudi-flink-bundle的pom.xml,替换hive为2.1.1-cdh6.2.1
# 编译
mvn clean install -DskipTests -DskipITs -Dcheckstyle.skip=true -Drat.skip=true -Dhadoop.version=3.0.0 -Pflink-bundle-shade-hive2
二、配置Flink环境(1.13.1)
- 将hudi-flink-bundle_2.11-0.10.0-SNAPSHOT.jar和hadoop-mapreduce-client*的jar放到flink1.13.1的lib目录下
mv ./hudi-flink-bundle_2.11-0.10.0.jar /app/flink-1.13.1/lib
cd /app/flink-1.13.1/lib
cd /opt/cloudera/parcels/CDH/jars/hadoop-mapreduce-client-common-3.0.0-cdh6.2.1.jar ./
cd /opt/cloudera/parcels/CDH/jars/hadoop-mapreduce-client-core-3.0.0-cdh6.2.1.jar ./
cd /opt/cloudera/parcels/CDH/jars/hadoop-mapreduce-client-jobclient-3.0.0-cdh6.2.1 ./ - 配置Flink On Yarn模式
# flink_conf.yaml
execution.target: yarn-per-job execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION execution.checkpointing.interval: 30000 execution.checkpointing.mode: EXACTLY_ONCE classloader.check-leaked-classloader: false jobmanager.rpc.address: hadoop001 jobmanager.rpc.port: 6123 jobmanager.memory.process.size: 1600m taskmanager.memory.process.size: 1728m taskmanager.numberOfTaskSlots: 1 parallelism.default: 1 state.backend: filesystem state.checkpoints.dir: hdfs://hadoop001:8020/flink-checkpoints jobmanager.execution.failover-strategy: region - 配置Flink,Hadoop,Hive,HBase的环境变量
export JAVA_HOME=/usr/java/jdk1.8.0_231 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH export HADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoop export HADOOP_CONF_DIR=/etc/hadoop/conf export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath` export FLINK_HOME=/app/flink-1.13.1 export PATH=${FLINK_HOME}/bin:$PATH export HIVE_HOME=/opt/cloudera/parcels/CDH/lib/HIVE export HIVE_CONF_DIR=/etc/hive/conf export HBASE_CONF_DIR=/etc/hbase/conf
三、部署同步hive环境
- 将hudi-hadoop-mr-bundle-0.10.0-SNAPSHOT.jar放到../CDH/jars 和 ../CDH/lib/hive/lib下面,每个节点都需要
cp hudi-hadoop-mr-bundle-0.10.0-SNAPSHOT.jar /opt/cloudera/parcels/CDH/jars/
cd ../lib/hive/lib
ln -ls ../../../jars/hudi-hadoop-mr-bundle-0.10.0-SNAPSHOT.jar hudi-hadoop-mr-bundle-0.10.0-SNAPSHOT.jar -
安装YARN-MapReduce的jar
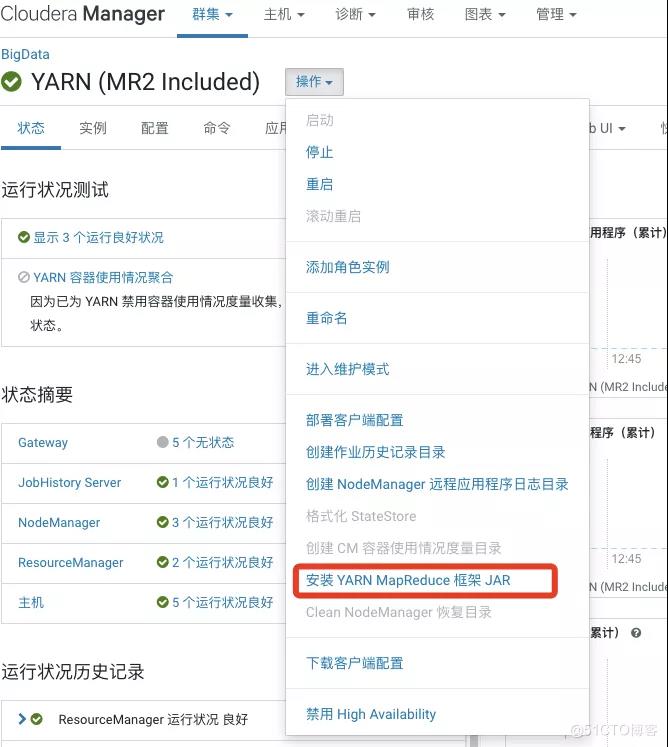
-
设置hive辅助jar

将hudi-hadoop-mr-bundle-0.10.0-SNAPSHOT.jar放到hive辅助jar路径下面, 上述步骤后需要重启hive meta和server2服务
-
cp hudi-hadoop-mr-bundle-0.10.0-SNAPSHOT.jar /usr/local/src/hook/hive
四、测试用例
1)测试Kafka数据往Hudi写,并且同步到Hive
- 创建Kafka Topic
cd /opt/cloudera/parcels/CDH/lib/kafka/bin
./kafka-topics.sh --zookeeper hadoop001:2181,hadoop002:2181,hadoop003:2181 --create --topic hudi_sync --replication-factor 1 --partitions 1 -
启动flink sql client
cd /app/flink ./bin/sql-client.sh embedded
-
创建source,sink表,执行插入操作
# kafka source 表, 需要将kafka-connector放到flink lib下
CREATE TABLE t_source ( id STRING ,name STRING ,age INT ,create_time STRING ,par STRING ) WITH ( 'connector' = 'kafka', -- 使用 kafka connector 'topic' = 'hudi_sync', -- kafka topic名称 'scan.startup.mode' = 'earliest-offset', -- 从起始 offset 开始读取 'properties.bootstrap.servers' = 'hadoop001:9092,hadoop002:9092,hadoop003:9092', -- kafka broker 地址 'properties.group.id' = 'group2', 'value.format' = 'json', 'value.json.fail-on-missing-field' = 'true', 'value.fields-include' = 'ALL' );
# hudi表:这里创建的是COW表,适用于离线批量 CREATE TABLE t_hdm( id VARCHAR(20) ,name VARCHAR(30) ,age INT ,create_time VARCHAR(30) ,par VARCHAR(20) ) PARTITIONED BY (par) WITH ( 'connector' = 'hudi' , 'path' = 'hdfs://hadoop001/hudi/hdm6' , 'hoodie.datasource.write.recordkey.field' = 'id' -- 主键 , 'write.precombine.field' = 'age' -- 相同的键值时,取此字段最大值,默认ts字段 , 'write.tasks' = '1' , 'compaction.tasks' = '1' , 'write.rate.limit' = '2000' -- 限制每秒多少条 , 'compaction.async.enabled' = 'true' -- 在线压缩 , 'compaction.trigger.strategy' = 'num_commits' -- 按次数压缩 , 'compaction.delta_commits' = '5' -- 默认为5 , 'hive_sync.enable' = 'true' -- 启用hive同步 , 'hive_sync.mode' = 'hms' -- 启用hive hms同步,默认jdbc , 'hive_sync.metastore.uris' = 'thrift://hadoop001:9083' -- required, metastore的端口 , 'hive_sync.jdbc_url' = 'jdbc:hive2://hadoop001:10000' -- required, hiveServer地址 , 'hive_sync.table' = 'hdm' -- required, hive 新建的表名 , 'hive_sync.db' = 'hudi' -- required, hive 新建的数据库名 , 'hive_sync.username' = '' -- required, HMS 用户名 , 'hive_sync.password' = '' -- required, HMS 密码 , 'hive_sync.skip_ro_suffix' = 'true' -- 去除ro后缀 ); -- 写入数据 insert into t_hdm select id, name, age, create_time, par from t_source; - 测试数据
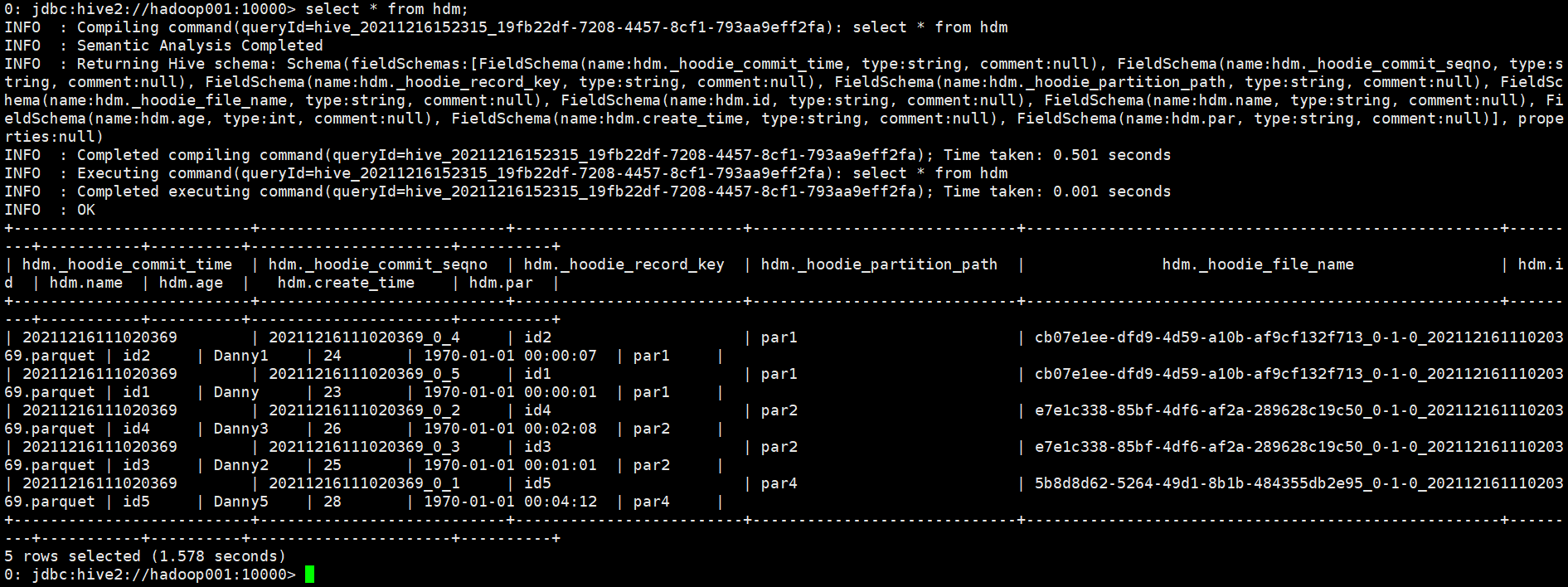
{"id": "id1", "name": "Danny", "age": 23, "create_time": "1970-01-01 00:00:01", "par": "par1"} {"id": "id2", "name": "Danny1", "age": 24, "create_time": "1970-01-01 00:00:07", "par": "par1"} {"id": "id3", "name": "Danny2", "age": 25, "create_time": "1970-01-01 00:01:01", "par": "par2"} {"id": "id4", "name": "Danny3", "age": 26, "create_time": "1970-01-01 00:02:08", "par": "par2"} {"id": "id5", "name": "Danny5", "age": 28, "create_time": "1970-01-01 00:04:12", "par": "par4"} - hudi中存储为parquet


- hive beeline查询,记得设置input format:
set hive.input.format = org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat;
2)MySQL CDC 入湖
- 将CDC jar放到Flink lib目录下
cd /app/flink mv /opt/softwares/flink-sql-connector-mysql-cdc-2.1.0.jar ./ mv /opt/softwares/flink-format-changelog-json-2.1.0.jar ./
-
SQL Client提交任务
-- mysql source CREATE TABLE mysql_users ( userId STRING PRIMARY KEY NOT ENFORCED , userName STRING ) WITH ( 'connector'= 'mysql-cdc', 'hostname'= 'node', 'port'= '3306', 'username'= 'root', 'password'= '123456', 'server-time-zone'= 'Asia/Shanghai', 'debezium.snapshot.mode' = 'initial', 'database-name'= 'aucc', 'table-name'= 'dim_user' ); -- 创建临时视图, 主要为了添加part字段,用于hive分区 create view user_view AS SELECT *, DATE_FORMAT(now(), 'yyyyMMdd') as part FROM mysql_users; -- hudi sink CREATE TABLE t_cdc_hdm( userId STRING, userName STRING, par VARCHAR(20), primary key(userId) not enforced ) PARTITIONED BY (par) with( 'connector'='hudi', 'path'= 'hdfs://hadoop001/hudi/hdm8' , 'hoodie.datasource.write.recordkey.field'= 'userId'-- 主键 , 'write.precombine.field'= 'ts'-- 自动precombine的字段 , 'write.tasks'= '1' , 'compaction.tasks'= '1' , 'write.rate.limit'= '2000'-- 限速 , 'table.type'= 'MERGE_ON_READ'-- 默认COPY_ON_WRITE,可选MERGE_ON_READ , 'compaction.async.enabled'= 'true'-- 是否开启异步压缩 , 'compaction.trigger.strategy'= 'num_commits'-- 按次数压缩 , 'compaction.delta_commits'= '1'-- 默认为5 , 'changelog.enabled'= 'true'-- 开启changelog变更 , 'read.streaming.enabled'= 'true'-- 开启流读 , 'read.streaming.check-interval'= '3'-- 检查间隔,默认60s , 'hive_sync.enable'= 'true'-- 开启自动同步hive , 'hive_sync.mode'= 'hms'-- 自动同步hive模式,默认jdbc模式 , 'hive_sync.metastore.uris'= 'thrift://hadoop001:9083'-- hive metastore地址 -- , 'hive_sync.jdbc_url'= 'jdbc:hive2://hadoop:10000'-- hiveServer地址 , 'hive_sync.table'= 't_mysql_cdc'-- hive 新建表名 , 'hive_sync.db'= 'hudi'-- hive 新建数据库名 , 'hive_sync.username'= ''-- HMS 用户名 , 'hive_sync.password'= ''-- HMS 密码 , 'hive_sync.support_timestamp'= 'true'-- 兼容hive timestamp类型 ); insert into t_cdc_hdm select userId, userName, part as par from user_view;