1.概述
在进行数据传输中,批量加载数据到HBase集群有多种方式,比如通过HBase API进行批量写入数据、使用Sqoop工具批量导数到HBase集群、使用MapReduce批量导入等。这些方式,在导入数据的过程中,如果数据量过大,可能耗时会比较严重或者占用HBase集群资源较多(如磁盘IO、HBase Handler数等)。今天这篇博客笔者将为大家分享使用HBase BulkLoad的方式来进行海量数据批量写入到HBase集群。
2.内容
在使用BulkLoad之前,我们先来了解一下HBase的存储机制。HBase存储数据其底层使用的是HDFS来作为存储介质,HBase的每一张表对应的HDFS目录上的一个文件夹,文件夹名以HBase表进行命名(如果没有使用命名空间,则默认在default目录下),在表文件夹下存放在若干个Region命名的文件夹,Region文件夹中的每个列簇也是用文件夹进行存储的,每个列簇中存储就是实际的数据,以HFile的形式存在。路径格式如下:
/hbase/data/default/<tbl_name>/<region_id>/<cf>/<hfile_id>
2.1 实现原理
按照HBase存储数据按照HFile格式存储在HDFS的原理,使用MapReduce直接生成HFile格式的数据文件,然后在通过RegionServer将HFile数据文件移动到相应的Region上去。流程如下图所示:
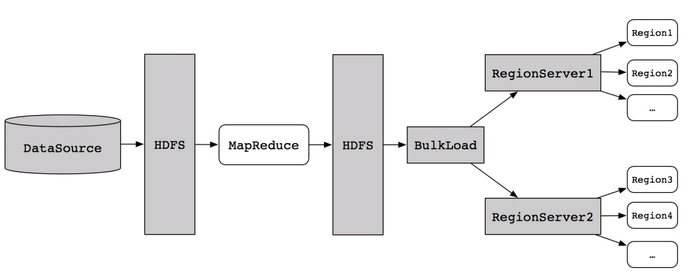
2.2. 生成HFile文件
HFile文件的生成,可以使用MapReduce来进行实现,将数据源准备好,上传到HDFS进行存储,然后在程序中读取HDFS上的数据源,进行自定义封装,组装RowKey,然后将封装后的数据在回写到HDFS上,以HFile的形式存储到HDFS指定的目录中。实现代码如下:
/** * Read DataSource from hdfs & Gemerator hfile. * * @author smartloli. * * Created by Aug 19, 2018 */public class GemeratorHFile2 { static class HFileImportMapper2 extends Mapper<LongWritable, Text, ImmutableBytesWritable, KeyValue> { protected final String CF_KQ = "cf"; @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); System.out.println("line : " + line); String[] datas = line.split(" "); String row = new Date().getTime() + "_" + datas[1]; ImmutableBytesWritable rowkey = new ImmutableBytesWritable(Bytes.toBytes(row)); KeyValue kv = new KeyValue(Bytes.toBytes(row), this.CF_KQ.getBytes(), datas[1].getBytes(), datas[2].getBytes()); context.write(rowkey, kv); } } public static void main(String[] args) { if (args.length != 1) { System.out.println("<Usage>Please input hbase-site.xml path.</Usage>"); return; } Configuration conf = new Configuration(); conf.addResource(new Path(args[0])); conf.set("hbase.fs.tmp.dir", "partitions_" + UUID.randomUUID()); String tableName = "person"; String input = "hdfs://nna:9000/tmp/person.txt"; String output = "hdfs://nna:9000/tmp/pres"; System.out.println("table : " + tableName); HTable table; try { try { FileSystem fs = FileSystem.get(URI.create(output), conf); fs.delete(new Path(output), true); fs.close(); } catch (IOException e1) { e1.printStackTrace(); } Connection conn = ConnectionFactory.createConnection(conf); table = (HTable) conn.getTable(TableName.valueOf(tableName)); Job job = Job.getInstance(conf); job.setJobName("Generate HFile"); job.setJarByClass(GemeratorHFile2.class); job.setInputFormatClass(TextInputFormat.class); job.setMapperClass(HFileImportMapper2.class); FileInputFormat.setInputPaths(job, input); FileOutputFormat.setOutputPath(job, new Path(output)); HFileOutputFormat2.configureIncrementalLoad(job, table); try { job.waitForCompletion(true); } catch (InterruptedException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } } catch (Exception e) { e.printStackTrace(); } } }
在HDFS目录/tmp/person.txt中,准备数据源如下:
11 smartloli 100 22 smartloli2 101 33 smartloli3 102
然后,将上述代码编译打包成jar,上传到Hadoop集群进行执行,执行命令如下:
hadoop jar GemeratorHFile2.jar /data/soft/new/apps/hbaseapp/hbase-site.xml
如果在执行命令的过程中,出现找不到类的异常信息,可能是本地没有加载HBase依赖JAR包,在当前用户中配置如下环境变量信息:
export HADOOP_CLASSPATH=$HBASE_HOME/lib/*:classpath
然后,执行source命令使配置的内容立即生生效。
2.3. 执行预览
在成功提交任务后,Linux控制台会打印执行任务进度,也可以到YARN的资源监控界面查看执行进度,结果如下所示:
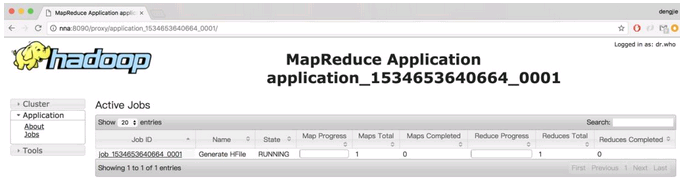
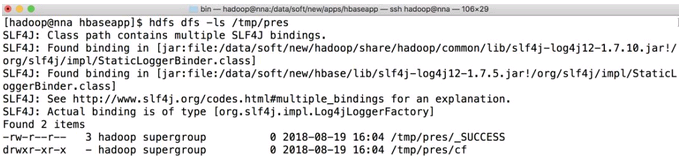
等待任务的执行,执行完成后,在对应HDFS路径上会生成相应的HFile数据文件,如下图所示:
2.4 使用BulkLoad导入到HBase
然后,在使用BulkLoad的方式将生成的HFile文件导入到HBase集群中,这里有2种方式。一种是写代码实现导入,另一种是使用HBase命令进行导入。
2.4.1 代码实现导入
通过LoadIncrementalHFiles类来实现导入,具体代码如下:
/** * Use BulkLoad inport hfile from hdfs to hbase. * * @author smartloli. * * Created by Aug 19, 2018 */public class BulkLoad2HBase { public static void main(String[] args) throws Exception { if (args.length != 1) { System.out.println("<Usage>Please input hbase-site.xml path.</Usage>"); return; } String output = "hdfs://cluster1/tmp/pres"; Configuration conf = new Configuration(); conf.addResource(new Path(args[0])); HTable table = new HTable(conf, "person"); LoadIncrementalHFiles loader = new LoadIncrementalHFiles(conf); loader.doBulkLoad(new Path(output), table); } }
执行上述代码,运行结果如下:
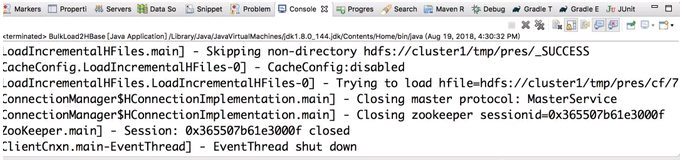
BulkLoad源码过程简述
程序中调用了LoadIncrementalHFiles的doBulkLoad方法进行HFile的移动。其主要流程如下:
1、初始化一个线程池,设置线程的最大数量
2、根据参数获取是否对HFile的格式进行验证
3、初始化一个queue,然后遍历MapReduce输出的目录下的所有HFIles文件,为每一个HFile包装一个LoadQueueItem,并加入到queue中
4、检查是否有非法的列簇名
5、遍历队列,尝试将HFie加载到一个region中,如果失败,它将返回需要重试的HFie列表。如果成功,它将返回一个空列表,整个过程是原子性的。
6、从RegionServer中获取到Region的名称后,检查是否可以安全的使用BulkLoad。如果为False,则使用ProtobufUtil的bulkLoadHFile。否则将使用SecureBulkLoadClient的bulkLoadHFile,将HFile Load到HBase目录下面。
7、如果HFile的BulkLoad失败了,将会尝试将失败的HFile将重新移回原来的位置。
其中需要注意的有:
1、当HFile的数量极大时,检查HFile的格式将会成为最耗时的阶段。可以通过设置hbase.loadincremental.validate.hfile来决定是否对HFile的格式进行检查(可见HBASE-13985)
2、BulkLoad阶段中,采用Callable和Future实现并发,一但BulkLoad失败,HFile需要重新排队,然后重试。重试次数可以通过hbase.client.retries.number进行设置,HBase1.2.5中默认为31次。
3、BulkLoad过程结束后,会发现MapReduce输出目录下的HFile文件都被移走了,说明全部的HFile都导入成功。如果想要试验的话,可以先备份一下,免得再跑一边MapReduce。
Load阶段为什么这么慢
1、在Load阶段阶段中,如果HFile文件过多,会触发hBase的compact和split操作。因此BulkLoad只是绕过了数据Put到Memstore和MemStoreFlush这个阶段。
2、当HFile的数量极大时,检查HFile的格式将会成为最耗时的阶段,可以设置不检查。
Bulk load的使用还是需要看场景,对于股市数据来说,使用Bulk load的导入效率可能没有直接写来得更快,但是其不占用 Region 资源和大量的IO资源,基本上不影响其它业务的运行,还是可以忍受的。
2.4.2 使用HBase命令进行导入
先将生成好的HFile文件迁移到目标集群(即HBase集群所在的HDFS上),然后在使用HBase命令进行导入,执行命令如下:
# 先使用distcp迁移hfile hadoop distcp -Dmapreduce.job.queuename=queue_1024_01 -update -skipcrccheck -m 10 /tmp/pres hdfs://nns:9000/tmp/pres # 使用bulkload方式导入数据 hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /tmp/pres person
最后,我们可以到指定的RegionServer节点上查看导入的日志信息,如下所示为导入成功的日志信息:
12018-08-19 16:30:34,969 INFO [B.defaultRpcServer.handler=7,queue=1,port=16020] regionserver.HStore: Successfully loaded store file hdfs://cluster1/tmp/pres/cf/7b455535f660444695589edf509935e9 into store cf (new location: hdfs://cluster1/hbase/data/default/person/2d7483d4abd6d20acdf16533a3fdf18f/cf/d72c8846327d42e2a00780ac2facf95b_SeqId_4_)
2.5 验证
使用BulkLoad方式导入数据后,可以进入到HBase集群,使用HBase Shell来查看数据是否导入成功,预览结果如下:

3.总结
本篇博客为了演示实战效果,将生成HFile文件和使用BulkLoad方式导入HFile到HBase集群的步骤进行了分解,实际情况中,可以将这两个步骤合并为一个,实现自动化生成与HFile自动导入。如果在执行的过程中出现RpcRetryingCaller的异常,可以到对应RegionServer节点查看日志信息,这里面记录了出现这种异常的详细原因。
https://mp.weixin.qq.com/s/0Eej-xzBVq3_Vw1y4tA4Dw