一.GC收集的工具
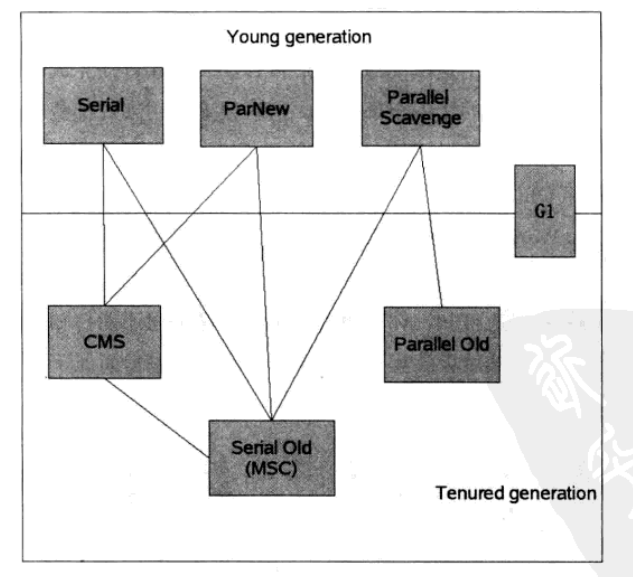
1.Servial收集器
特点:历史悠久,单线程收集,复制算法,,stop the world,收集新生代,简单高效,专心收集,没有线程切换开销
用在Client模式下是一个非常好的选择。

2.ParNew收集器
特点:就是serial收集器的多线程版本,可控参数回收算法都与serial一样,server模式下,新生代的首选
在单核的情况下,绝不会有serial收集的效果好,存在线程交互开销。

3.Parallel Scavenge收集器
特点:多线程,收集新生代,复制算法,注重吞吐量
吞吐量:就是用户执行代码的时间比上cpu总执行时间。
这个收集器提供了两个参数精准控制控制吞吐量
-xx:MaxGCPauseMillis最大的GC停顿时间
-xx:GCTimeRatio直接设置吞吐量大小
-xx:+UseAdapttiveSizePolicy开关参数
一些新生代中Eden,survivor比例,晋升老年代的年龄等
细节就可以自动设置,这个自动调节策略还是很优秀的,它是根据
当前运行的监控信息,动态调节的。
上面两个参数并不是很如意的
举例:即便最大停顿时间设置的很小,
那也是牺牲吞吐量或者新生代的空间换来的
4.Serial Old收集器
特点:老年代,单线程回收,标记-整理算法
用途:主要被用作Client模式下的虚拟机。
server模式下:jdk1.5与Parallel Scavenge搭配使用
作为CMS的后备方案

5.Parallel Old收集器
特点:Parallel Scavenge收集器的老年代版本,标记-整理算法,JDK1.6才出现
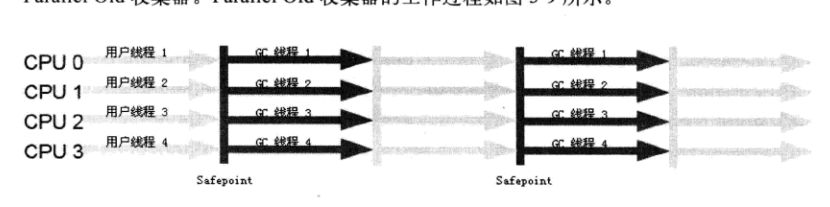
配合Parallel Scavenge收集器使用。
6.CMS收集器
特点:最短回收停顿时间,重视响应速度,带给用户高效体验
标记-清除算法,老年代,四个步骤收集(相对复杂)
四个收集步骤:
初始标记:简单标记GCRoots能直接关联到的对象(快)
并发标记:GC Roots Tracing(跟踪)过程(慢)
重新标记:修正并发标记时用户程序导致标记发生变化的那部分对象记录
并发清除:就是并发情况下然后清除。
初始标记,重新标记都会“stop the world”
CMS三个缺点:
1.对CPU资源敏感,并发阶段虽然不会导致用户线程停顿,但会占用cpu资源,导致变慢
总吞吐量降低。CMS默认启动的回收线程数是(CPU+3)/4,但CPU核数4个以上,并发
回收只占用25%,不足4个那就惨了,会占用50%。那用户线程就惨了哟。解决方法就是
i-CMS抢占式使线程交替,这样用户线程影响小点。(但是不推荐使用)
2.CMS无法收集浮动垃圾。
并发清理过程中,用户线程还是在不断生成垃圾,本次GC不能处理,只能等下GC。
所以,老年代空间不能太满才GC,要预留一些空间(68%),不然会产生的浮动垃圾没
地方存放,如果出现这种情况,虚拟机就会启动后备方案,临时使用Serial Old收集器重
新进行老年代的垃圾收集,这样时间就会更长。这个预留的空间设置多大还是看情况的好。
3.这个标记-清除算法会产生大量的空间碎片,空间碎片过多就会无法分配内存给大对象,CMS
提供一个-xx:UseCompactAtFullCollection参数(享受完FullGC后,送一次空间碎片整理)
7.G1收集器(简单介绍)
特点:标记-整理(不产生空间碎片),精准控制停顿,不牺牲吞吐量完成低停顿的内存回收
G1将新生代,老年代划分为多个固定独立区域,跟踪区域中垃圾堆积程度,在后台维护
一个优先列表,每次根据允许的收集时间,优先回收最多的区域。区域的划分及有优先级
的区域回收,保证了G1收集器在有限的时间内可以获得最高的收集效率。
到这里基本就介绍完常接触的几种收集器了。
参考:深入理解Java虚拟机