一、归并排序
归并排序(MERGE-SORT)是利用归并的思想实现的排序方法,该算法采用经典的分治(divide-and-conquer)策略(分治法将问题分(divide)成一些小的问题然后递归求解,而治(conquer)的阶段则将分的阶段得到的各答案"修补"在一起,即分而治之)
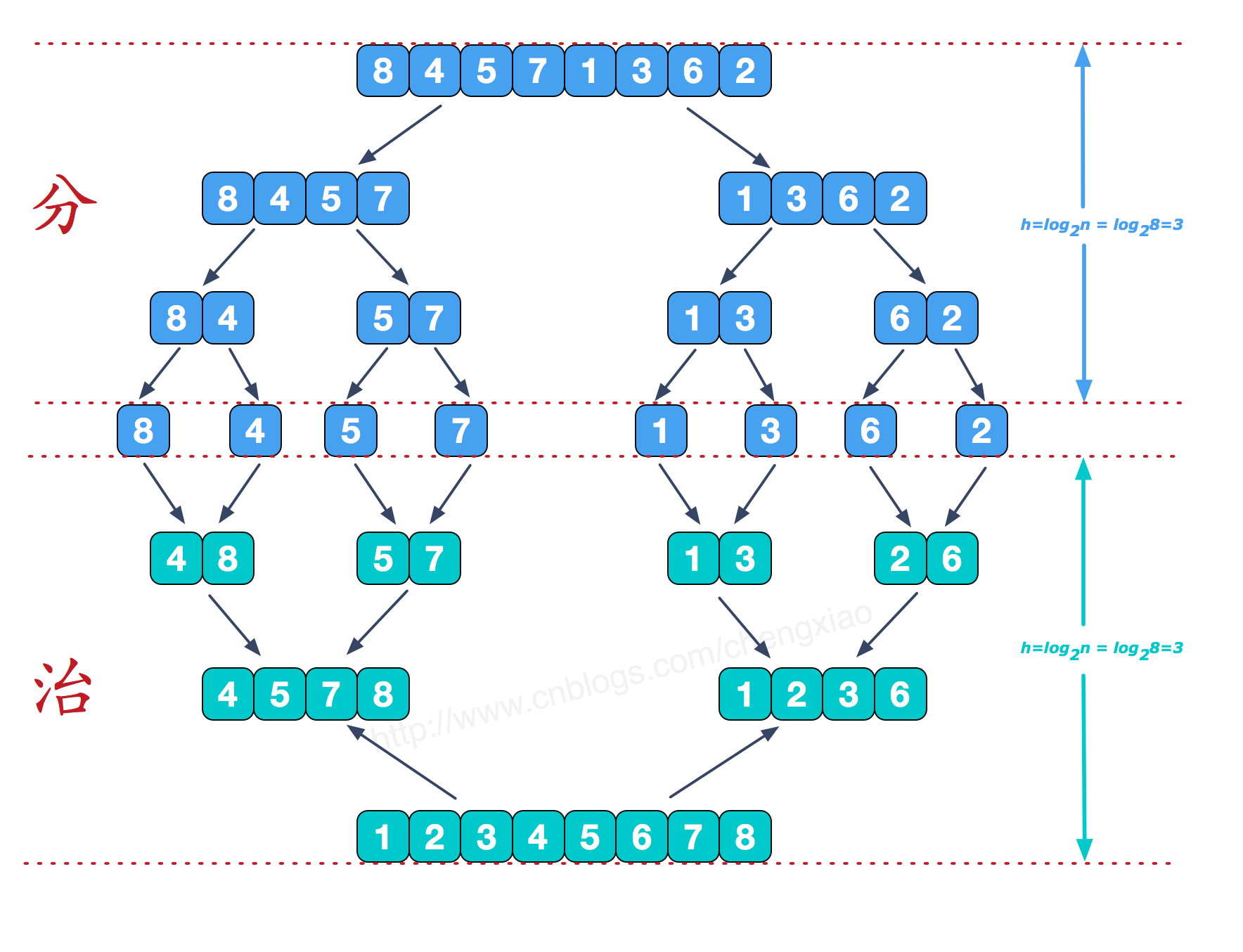
可以看到这种结构很像一棵完全二叉树,本文的归并排序我们采用递归去实现(也可采用迭代的方式去实现)。分阶段可以理解为就是递归拆分子序列的过程,递归深度为log2n。
再来看看治阶段,我们需要将两个已经有序的子序列合并成一个有序序列,比如上图中的最后一次合并,要将[4,5,7,8]和[1,2,3,6]两个已经有序的子序列,合并为最终序列[1,2,3,4,5,6,7,8],来看下实现步骤。

从上文的图中可看出,每次合并操作的平均时间复杂度为O(n),而完全二叉树的深度为|log2n|。总的平均时间复杂度为O(nlogn)。而且,归并排序的最好,最坏,平均时间复杂度均为O(nlogn)。
def mergedSort[T](le: (T, T) => Boolean)(list: List[T]): List[T] = {
def merged(xList: List[T], yList: List[T]): List[T] = {
(xList, yList) match {
case (Nil, _) => yList
case (_, Nil) => xList
case (x :: xTail, y :: yTail) =>
if (le(x, y)) x :: merged(xTail, yList)
else
y :: merged(xList, yTail)
}
}
val n = list.length / 2
if (n == 0) list
else {
val (x, y) = list splitAt n
merged(mergedSort(le)(x), mergedSort(le)(y))
}
}
二、快速排序
1.三步走:
(1) 选择基准值。
(2) 将数组分成两个子数组:小于基准值的元素和大于基准值的元素。
(3) 对这两个子数组进行快速排序。
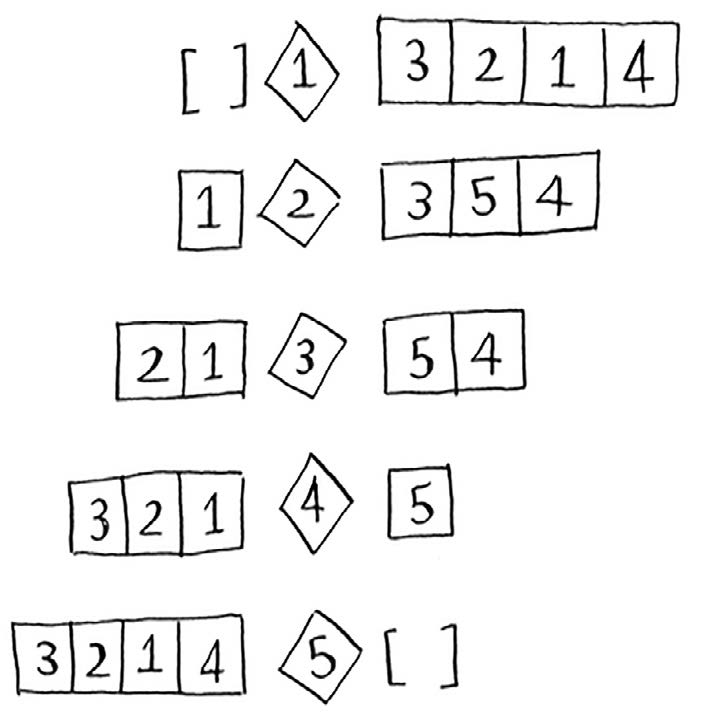
2.最简单是以第一个元素为基准
def qsort[T](list: List[T])(implicit t:T=>Ordered[T]):List[T]=list match {
case Nil=>Nil
case ::(pivot,tail) => qsort(tail.filter(_<=pivot)) ++ List(pivot) ++ qsort(tail.filter(_>pivot))
}
3.优化之三数取中法
就是取左端、中间、右端三个数,然后进行排序,将中间数作为基准值。
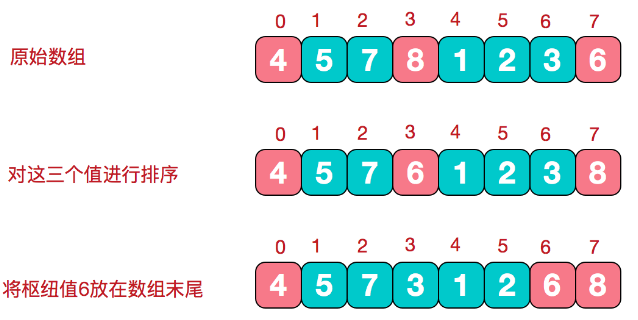
根据基准值进行分割
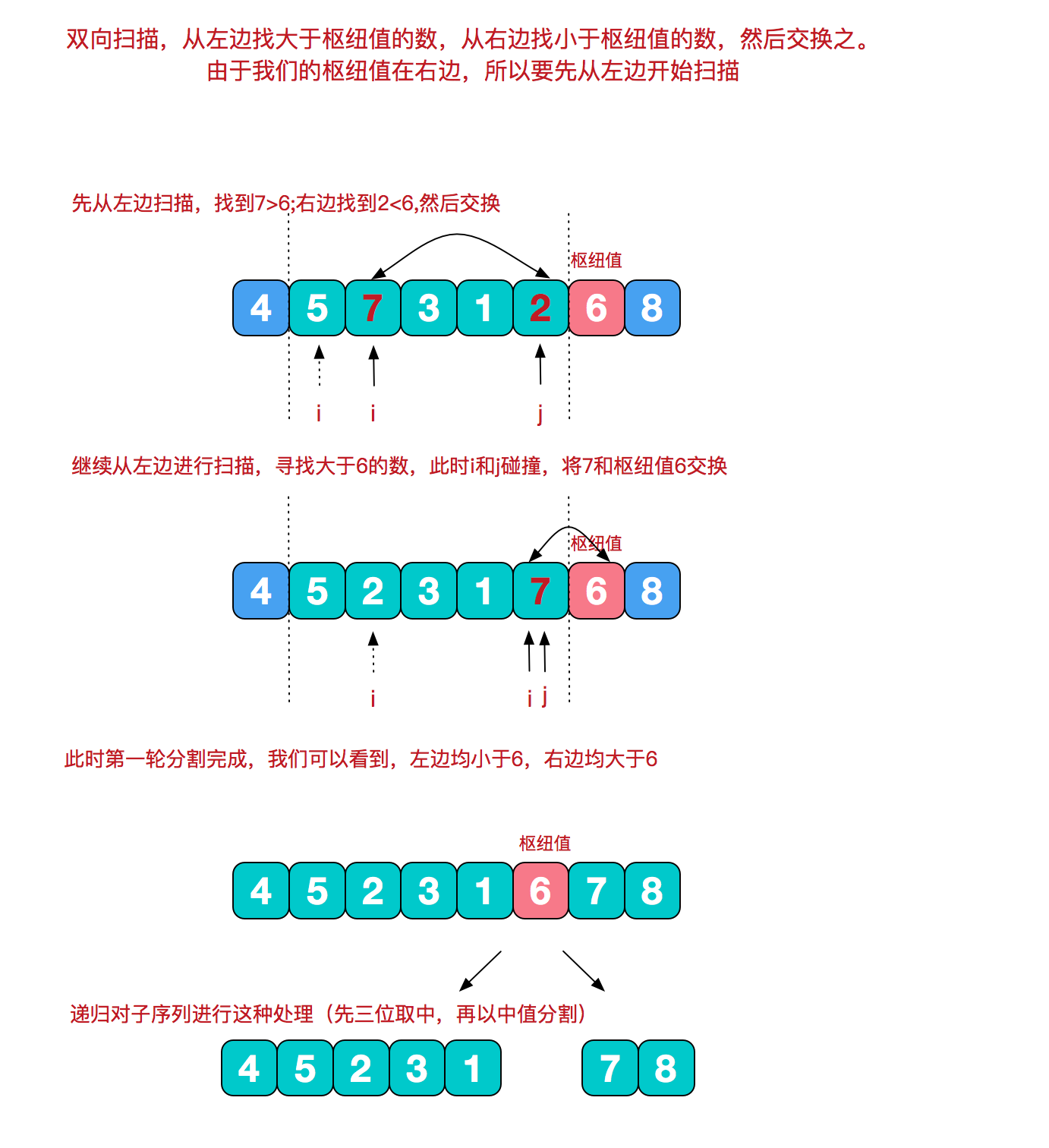

def quickSort(arr: Array[Int]): Unit = quickSort(arr,0,arr.length-1)
def quickSort(arr: Array[Int], left: Int, right: Int): Unit ={
if (left < right) {
dealPivot(arr, left, right)
//基准值放在倒数第二位
val pivot = right - 1
//左指针
var i = left
//右指针
var j = right - 1
while (i<j) {
while (arr(i) < arr(pivot)) {
i += 1}
while (j > left && arr(j) > arr(pivot)) {
j = j - 1}
swap(arr, i, j)
}
if (i < right) swap(arr, i, right - 1)
quickSort(arr, left, i - 1)
quickSort(arr, i + 1, right)
}
}
// 处理基准值
def dealPivot(arr: Array[Int], left: Int, right: Int): Unit = {
val mid = (left + right) / 2
if (arr(left) > arr(mid)) swap(arr, left, mid)
if (arr(left) > arr(right)) swap(arr, left, right)
if (arr(right) < arr(mid)) swap(arr, right, mid)
swap(arr, right - 1, mid)
}
// 交换元素通用处理
private def swap(arr: Array[Int], a: Int, b: Int) = {
val temp = arr(a)
arr(a) = arr(b)
arr(b) = temp
}