采集需求:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs,使用agent串联
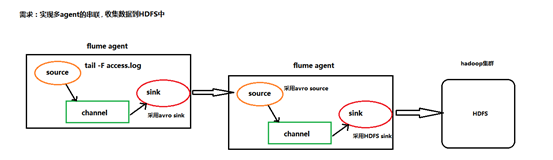
根据需求,首先定义以下3大要素
第一台flume agent
l 采集源,即source——监控文件内容更新 : exec ‘tail -F file’
l 下沉目标,即sink——数据的发送者,实现序列化 : avro sink
l Source和sink之间的传递通道——channel,可用file channel 也可以用 内存channel
第二台flume agent
l 采集源,即source——接受数据。并实现反序列化 : avro source
l 下沉目标,即sink——HDFS文件系统 : HDFS sink
l Source和sink之间的传递通道——channel,可用file channel 也可以用 内存channel
配置文件编写:
在mini1的conf下
vi execsource-avrosink.conf
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /root/logs/test.log # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.channel = c1 a1.sinks.k1.hostname = mini2 a1.sinks.k1.port = 41414 a1.sinks.k1.batch-size = 2 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
在mini2造数据

while true; do date >>test.log ;sleep 0.5s; done
在mini2的conf下
avro-sink.conf
a1.sources = r1 a1.sinks =s1 a1.channels = c1 ##source中的avro组件是一个接收者服务 a1.sources.r1.type = avro a1.sources.r1.bind = 0.0.0.0 a1.sources.r1.port = 41414 a1.sinks.s1.type=hdfs a1.sinks.s1.hdfs.path=/flumedata a1.sinks.s1.hdfs.filePrefix = access_log a1.sinks.s1.hdfs.batchSize= 100 a1.sinks.s1.hdfs.fileType = DataStream a1.sinks.s1.hdfs.writeFormat =Text a1.sinks.s1.hdfs.rollSize = 10240 a1.sinks.s1.hdfs.rollCount = 1000 a1.sinks.s1.hdfs.rollInterval = 10 a1.sinks.s1.hdfs.round = true a1.sinks.s1.hdfs.roundValue = 10 a1.sinks.s1.hdfs.roundUnit = minute a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sources.r1.channels = c1 a1.sinks.s1.channel = c1
启动
在mini2先启动 bin/flume-ng agent -c conf -f conf/avro-sink.conf -n a1 -Dflume.root.logger=INFO,console
在mini1再启动 bin/flume-ng agent -c conf -f conf/execsource-avrosink.conf -n a1 -Dflume.root.logger=INFO,console
结果
