标题:Robust Semantic Representations for Inferring Human Co-manipulation Activities even with Different Demonstration Styles
0. 摘要
在这项工作中,我们提出了一种新颖的方法,该方法可以生成紧凑的语义模型来推断人类的协调活动,包括需要了解双臂测序的任务。这些模型对于从同一活动的不同执行样式观察时具有鲁棒性和不变性。另外,所获得的语义表示能够重用所获得的知识来推断不同类型的活动。此外,我们的方法能够推断出双臂的协同操作,并且考虑了推断出的活动之间的正确同步,以实现所需的共同目标。我们提出一种系统,而不是专注于不同的执行方式,而是通过语义表示来提取观察到的任务的含义。所提出的方法是一种分层方法,该方法首先从观测值中提取相关信息。然后,它基于获得的语义表示来推断观察到的人类活动。之后,这些推断的活动可用于触发机器人中的运动原语以执行演示的任务。为了验证系统的可移植性,我们在两个不同的人形平台iCub机器人和REEM-C机器人上评估了基于语义的方法。证明我们的系统能够正确细分并在线推断观察到的活动,平均准确度为84.8%。
1.介绍
使机器人学习新任务通常需要人类多次演示期望的任务[1]。 这意味着所获取的模型将极大地捕获演示所需活动的人的执行方式。 但是,这可能会导致获取模型的泛化的主要问题,因为几乎不可能教给机器人一种特定活动的所有可能变化。 然后,理想的情况是使具有推理机制的机器人能够通过生成以一般方式解释所演示活动的模型来允许他们学习新活动,从而允许包含同一活动的不同变体。
即使可以从重复的人类运动中观察到刻板印象和预定义的运动模式[2],也可以根据人,地方或环境的限制,以许多不同的形式执行一项活动或类似活动。换句话说,每个人都有自己的风格来执行所需的活动。例如,图1显示了至少三个不同的现实生活中的演示,演示了随机人进行的切面包的活动。我们可以观察到,第一个参与者正在使用一种常见的方式来用左手握住面包,并用右手执行切割活动,图1.b.1。在另一种形式中,中间的参与者选择用左手滚动面包,而用右手切割面包,图1.b.2。最后,左手的第三名参与者用右手握住面包,用左手切面包,图1.b.3。这表明我们需要设计一个能够处理所有这些不同执行样式的系统。
在我们以前的工作[3]中,我们提出了一个系统,该系统允许我们的iCub人形机器人使用拟议的分层方法来提取人的活动的含义,以获得语义模型。后来,我们扩展了我们的系统,方法是同时包含两只手的活动识别,如[4]中所述。即使我们的系统能够识别两只手的活动,也只能执行一只手的活动。 然后,本文以以下形式增强了我们当前的系统:a)我们为不同活动的演示样式的变化增加了鲁棒性; b)然后,我们提供了一种解决协同活动问题的方法; c)最后,我们改善了系统的可移植性,并在两个不同的人形平台上对其进行了测试。
本文的组织结构如下,第二节介绍了相关工作。 然后,第三节介绍了所提出系统的主要模块。 随后,第四节介绍了提取低级功能的步骤。 然后,第五节介绍了语义表示方法。 第六节介绍了语义模型向类人机器人的转移。 最后,第七节简要介绍了所获得的结果和结论。
2. 相关工作
学习和理解人类活动可以极大地提高所获得的知识在不同机器人平台之间的传递和推广。 这些机器人平台具有不同的实施例和不同的认知能力[5],因此,训练有素的模型从一个平台到另一个平台的转移不是直截了当的,通常,所获得的模型仅适用于测试平台[6]。 但是,如果不是学习动作的执行方式,而是学习这些动作的含义,那么我们可以将这些学习的模型转移到不同的情况下,并按照本文的建议在不同的机器人平台之间进行转移。
已经(主要)使用主要从外部视频(例如视频)中观察到的人体姿势对演示中的人类活动进行了细分和识别。 使用条件随机场(CRF)[7],动态时间规整[8]或通过使用隐马尔可夫模型(HMM)模仿模型[9]对观察到的轨迹进行编码。 但是,以上技术是根据轨迹的生成而实现的,而轨迹的生成取决于对象的位置和人体姿势,这意味着,如果正在分析不同的环境或由不同的演示者对其执行,那么轨迹将被完全改变。 必须为分类获得新模型,这意味着所提出的技术需要大量时间才能最终学习特定任务[1]。 另外,这样的技术需要复杂的视觉处理方法来提取人体姿势[10]。
3. 系统模块说明
大多数识别系统都设计为完全适合所研究的任务,但是,大多数这些系统无法轻松扩展到新任务或允许使用不同的输入源[6]。 本节介绍了我们提出的框架的总体设计和主要组成部分。 我们系统的主要优点是其抽象级别,可增强其可伸缩性和对新情况的适应性。 例如,我们的感知模块允许使用不同的输入源,例如:可以引导学习过程的单个视频[3],多个视频[17]和虚拟环境[18]。
我们的框架包含四个主要模块(请参见图2):1)了解演示的相关方面; 2)生成或重用语义规则; 3)推断示威者的目标; 最后,4)由机器人执行推断的行为。
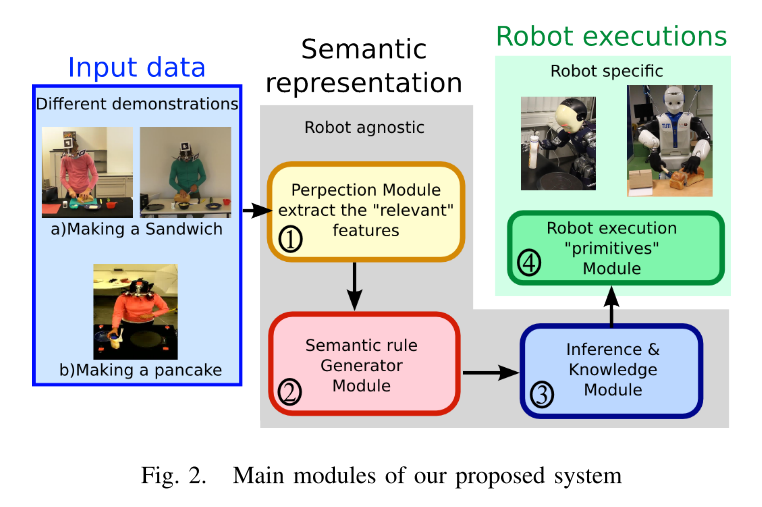
感知模块使机器人能够感知来自不同来源的不同类型的输入信息。 该模块提取从环境(输入源)获得的特征,分析特征并生成有意义的信息。 从输入数据中分割出三个基本运动,即运动,不运动和工具使用。 此外,还从环境中提取信息,例如场景中的对象及其属性,在本例中,我们考虑了以下两个属性:ObjectActedOn和ObjectInHand。
语义模块代表了我们系统的核心。 它解释从“感知”模块获得的数据,并处理该信息以自动推断和理解观察到的人类行为。 它负责通过生成语义规则来识别和提取人体运动的含义。
推理模块包括知识库,以增强我们系统的推理能力。 这是一个重要的功能,在发生故障的情况下,系统使用其知识库来获取包含所需类实例的系统的替代等效状态。 使用知识库,我们不必每次面对新情况时都重新计算语义规则。
机器人基元模块使用推断的活动并启用人工系统,即允许机器人重现推断的动作,以实现与观察到的目标类似的目标。 这意味着在给定活动的情况下,机器人需要执行技能计划并从库中命令图元来生成相似的结果。
我们的系统基于分层方法,其中定义了不同的抽象级别。 观察结果的这种抽象抓住了活动的本质,这意味着我们的系统能够指示演示者活动的哪个方面应执行以完成推断的活动。
A. 抽象层次
来自心理学和认知界的研究表明,以目标为导向的活动表现出经常性的相互关联的活动模式[19]。 受上述发现启发,我们提出了两个抽象层次:
第一个收集(感知)来自环境的低级特征信息,即 基本的原子动作,例如:移动,不移动和工具使用,以及基本的对象属性,例如 ObjectActedOn和ObjectInHand(请参阅第IV节);
而第二部分则解决了使用我们提出的推理引擎将感知的信息解释为有意义的类的困难问题,即高级人类活动,例如:到达,获取,削减等(请参见第V节)。
4. 从观察中提取低水平特征
在我们以前的工作[3]中,我们建议从观察中提取以下低层特征,即将三个原始人体运动分为以下类别之一: