Week7
Technology: Application Protocols
This week, we’ll be covering application protocols. With reliable “pipes” available from the Transport layer, we can build applications like web browsers, file transfer applications, or email clients and servers.
时间飞逝,这周我们将学习技术层次的最后一周,在这周里,教授讲解了最后一层Application Layer的内容,同时也说到了我以前的特别感兴趣的”Hacker”,正如每个男生心里都有一个武侠梦,每一个IT男心里都有一个Hacker梦。哈哈哈
Layer 4: Applications
Application Layer
学习了前三周,我们知道,TCP/IP模型前三层,层层相扣,互相弥补,缺一不可。哪么你其实也可以推测出,第四层也是这样的,依赖于第三层TCP层。TCP层的服务为应用层提供了可靠、有序的端到端数据流。可以从一台电脑中一个应用程序开始,到另一台电脑的应用中结束并可提供双向交流。在我们得到了这样的框架后,我们应该怎么去使用它?在日常通信中,我们该如何请求数据?
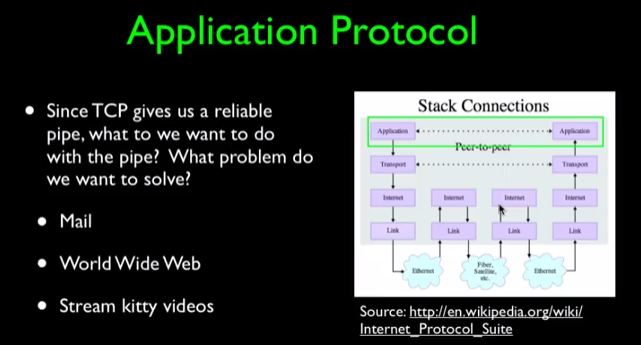
在上图中,两侧都有Application方框。一般来说,一侧代表用户,另一侧代表服务器。客户端给我们信息,而服务器负责给客户端提供信息,所以客户端经常要发出请求,然后服务器回应请求,这之间的消息传递就是我们之前所学习的四个层次。因此,我们可以基于这个原理建立邮件系统、万维网或者我们可以观看流视频。这时候就要重点提一下万维网了,它基于上面所说的原理,整体简洁且优雅,可以说是最为人所熟知的一个概念,虽然也有很多其他的协议存在,但是万维网协议是最普遍的协议。
Application Layer有两个基本问题:
1.Which application gets the data?
- Ports
2.What are the rules for talking with application?
- Protocols
Ports
所谓的端口,就好像是门牌号一样,客户端可以通过ip地址找到对应的服务器端,但是服务器端是有很多端口的,每个应用程序对应一个端口号,通过类似门牌号的端口号,客户端才能真正的访问到该服务器。为了对端口进行区分,将每个端口进行了编号,这就是端口号
IANA(Internet Assigned Number Authority,互联网地址分配机构)维护了端口分配列表,分三类:
第一类:0-1023,众所周知的端口。由IANA控制和分配,特定的网络程序使用,例如:TCP协议使用80端口来完成http协议传输。
第二类:1024-49151,登记端口。不由IANA控制,但IANA维护了登记表,不应该在程序中使用,如果没有冲突情况下也是可以由用户程序使用。
第三类:49152-65535,私有端口。可以由普通用户程序使用。
常用的端口

Application Protocols
服务器有许多端口,分别起着不同的作用。而一旦我们和网络服务器、邮箱服务器或邮局服务器有了连接,我们就得了解如何和它进行沟通,这就是所谓的应用协议(Application protocols)。这也就是我们要面对的第二个问题,与应用程序交谈的规则是什么?TCP提供了可靠的连接,我们现在可以通过端口连向想要的的服务器,而现在的问题是:我们在整次连接中要说些什么?说什么?谁先说?需要发送些什么内容?而这取决于你进行对话的是哪类服务器,例如在视频中,就是使用万维网服务器。
HTTP - Hypertext Transport Protocol

HTTP,超文本传输协议,是一个简单的请求-响应协议,它通常运行在TCP之上。它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。请求和响应消息的头以ASCII码形式给出;而消息内容则具有一个类似MIME的格式。万维网服务器和客户端的交流就是采用了HTTP协议。下面老师给我们演示了一下HTTP协议响应机制。
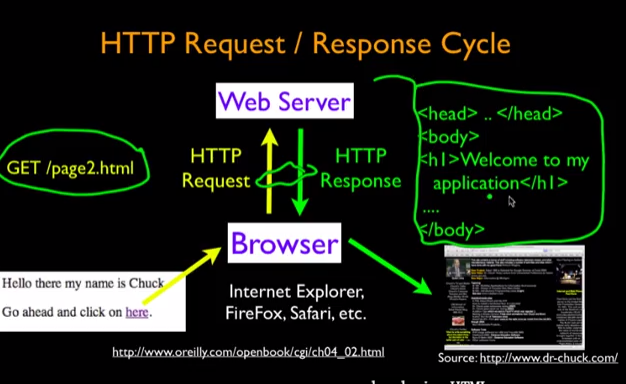
当你点击一个运行在你电脑中的客户端client的一个link,浏览器就会和web server 连接并发送一个请求,web server看到了就会返回请求,返回的document就会出现在客户端的桌面上。
Hacking HTTP
我们知道,在现实生活中网络似乎渐渐变得无所不能。但网络终究是死的,人是活的。在我们了解协议的内容后,我们就可以尝试去“攻击”网站,因为HTTP基本上是一个公共协议,它并没有被高度保护,所以它也是较为容易被攻击的,Windows系统需要下载Telnet,其最终的目的就是欺骗服务器,让它认为我们是浏览器,从而向我们发送数据。如果你看过黑客帝国,你一定会被Hacker这么名词所吸引,it is so cool!小的时候,我也想过如果当一名Hacker一定非常精彩。哈哈哈。

Application Layer Summary
应用层,基于底部的三层,不考虑底部技术细节,把它们抽象一个简单的管子,连通客户和服务器。
应用层是一个体量丰富的层次,在这一层就有许许多多的应用了。我们使用端口号,这样我们就可以连接到同一服务器上面的不同服务。

The Internet: An Amazing Design
介绍完Application Layer,我们也讲完了四层模型。但非常不可思议的是,这些大部分都来自1970年代的研究工作,且现在都还在使用,随着NSFnet的出现,会有一定的调整,但关键性的调整也都是上个世纪八十年代的事了。但另一方面,计算机的数量则大幅度增长,从1969年的6台到2011年的几十亿级别,他们仍在使用这最初的六台所使用的框架。当你看着现在的网络的时候,你可能会觉得它像一个生物,有着鲜活的生命,它从蹒跚的小孩慢慢成长为腾飞的巨龙。

俗话说不完美的才是完美的。互联网诞生开始就是不完美的。在互联网诞生之际,我们并没有给它设置一个上限,而是让它慢慢的成长,给他良好的扩张性,而这样也使得它慢慢变得无比巨大。这很像在修仙小说里修道一样。每个人的道都是不一样的,一味的模仿就像给它设置了一个限制。模仿永远不会有超越。只有通过自己的成长,才能有自己的道。
Van Jacobson - Content Centered Networking
当我们写到这里,我们对互联网技术层次的介绍就要接近尾声了。我们讲了互联网的历史,互联网现有的技术,在接近尾声之际,教授则想要引发我们对互联网未来的展望,对互联网未来的思考。你知道的,过去终究是过去,我们只有面向未来才会有更好的发展。在三十年之前,你根本无法想象,互联网的的出现会给世界带来如此大的变化,当然你也无法想象未来20年世界是怎么样的,因此我们需要不断的进步,不断地优化,不断地推陈出新。这也是教师给我们看这个视频的意义所在。你知道的,Van Jacobson 是一个天才,他的想法很多时候都领先于当时的世界,现在就让我们来看看他的想法。
Van在当时,提出了一个对未来互联网的设想——Content Centric Networking(内容中心网络),Van认为我们现在面临着大量的关于拓展性问题,他想把以信息为中心的网络模型,和以主机为中心的TCP/IP模型整合到一起。
网络最开始只是电脑的一个电话系统,但随着需求的增加,ARPnet诞生了,它可以不需要像电话线路一样知道所有结点,它只需要知道消息发送的下一个结点,就能把数据发送出去,而到了二十一世纪后,网络又有了新的发展。
但这些似乎都和最开始的电话模型没什么关系,这给Van带来了很大的冲击,这让他发出疑问:如果我们放弃18世纪的电话模型,把注意力放在电线里传输的信息,而不是电线本身,会怎么样? 我们能不能把web当作通讯的基础,而不仅仅是一个覆盖在TCP/IP上的一层? 例如,你可以在你的个人网站上面发布一个视频,但是你必须得寄希望于它的点击量不是特别大,因为如果点击量过大,你的链接配额将完全饱和。那么你的互联网供应商(ISP)就会马上关闭它,这就是 Slashdot 效应。现如今,你可以看到像YouTube、谷歌、亚马逊、脸书、推特都拥有着庞大的用户群,它们都是用一个IP地址表明自己,看起来就像只有一个地点,但是对于一个拥有数亿用户的单一地点来说,在对话模型下,它的通信量将跟用户数量同比增长,比如你正在更新推特或者上传视频,你想让数百万人看到,但你没法把它放到对话模型中。
所以,Van 他们花了许多的时间来让网络误以为只有一个地点,网络层的信息在性质上与姓名,身份信息一致,只是它随机的分散在整个分组里。这样他们有了源地址和目的地址,它的前部被网络层调用,端口作为更深层次的应用层调用,以及序列号,让应用重新组装成一个大的单元,URL的整个分层都要使用它,而不是只有传输的部分。如果你把源地址,端口,序列号,URL均整合到了一起,这些就是信息的特定名称(the name of the information)。如果每一个分组都有一个名字在上面,所有的信息都包含在其中,你随时可以查看它,只需要保证数据的前端工作是正常的。
你不必关心这些数据是从哪里获得的,你只需要关心数据本身,而不是它的来源。如果我们有两个人同时在看同一个视频,那么最靠近我们的上游网关会把一份拷贝发给我,把另一份一模一样的视频拷贝发给你,它们都要通过那一个网关的内存,因为这个对话的抽象概念的存在,网关并不知道,我们看的是相同的视频,它看到的是两个不同的对话,它没法看着它的内存,然后说:“哦!我有这个数据,我可以直接给你。”它必须要重新拿到一个新的拷贝,而且要从YouTube那里一路传下来,导致这种槽糕的拓展性的原因,是因为负载的拓展性或者说用户数量严格地跟数据有关,而且数据只能有一个源头。反过来如果你只关心数据本身 那么你沿着数据的源头方向去找。只要你在路上找到了这个数据,意味着你已经有了它的拷贝,那么这个数据的传送任务也就完成了。
Think after class
- 化繁为简。在Week5中,我们提到了Packet-switching,它的核心理念就是将一个庞大的数据分解成一个个小的数据,解决了网络堵塞的问题。其实在生活中我们也可以贯彻这样的想法。比如你要求每天被50个单词,哪么你就可以分成早上10个,中午10个,旁晚10个,晚上10个,睡觉10个。在生活中,这是一个很适用的方法。
- 分而化之,专而一之。在TCP/IP的模型中,我们知道每层都趋于专门化,这层只负责这个功能,哪层只负责哪层功能,这样极大的提高了效率并且也使得每层更专业,这让我想到了一句话,术业有专攻。人的精力是有限的,如果我们想要做出什么成就,应该专一且坚定不移地坚持下去。如果总是囫囵吞枣,终究上不得台面。
-
.如果要解决一个问题,就要了解事物的本质。在Hacking HTTP这节中,我们知道了协议的内容,我们就可以根据协议内容而攻击服务器,正所谓,知彼知己,百战不殆。
PS:(时间过的好快,转眼间技术层次就学完了。在这三周里,学到了很多干货。在计算机导论课堂上,老师也提到了TCP/IP模型等内容,但只是说了专有名词,而在这三周的内容则是加深和扩张了我对网络的了解。还有课后思考,现在的我只能做出哲理型思考,而不能做出技术型思考,你知道的技术需要专业的知识,而且我只是一个嗷嗷待哺的小雏鹰,希望我在未来能早日做出对技术的思考,同时将思考转化为成果。加油!)