为理解空洞卷积的详细作用以及对应的操作,对RFBNet进行复现。
代码位置:https://github.com/ruinmessi/RFBNet
完成下载后,执行./make.sh时出现下面的错误:
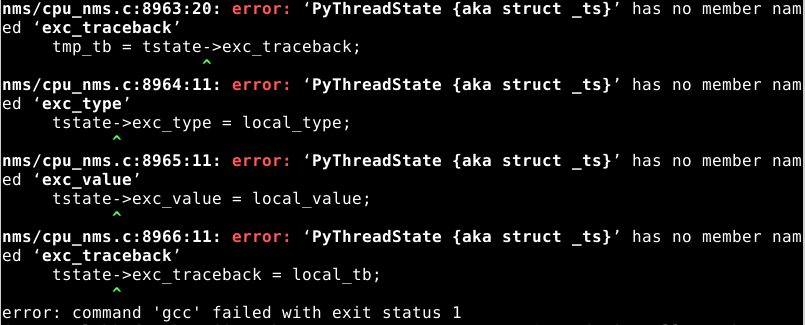
根据网上一篇博客说是Cython模块没有安装的原因,但是安装后,仍然没有效果
看着错误一步步进行更改:


1、根据错误提示,(PyObject *(*)(PyObject *, PyObject * const *, Py_ssize_t))meth函数给的参数太多,根据需要删除一个参数,而看一下每个参数的概念以及对应的类型名称,最后决定应当删除NULL。
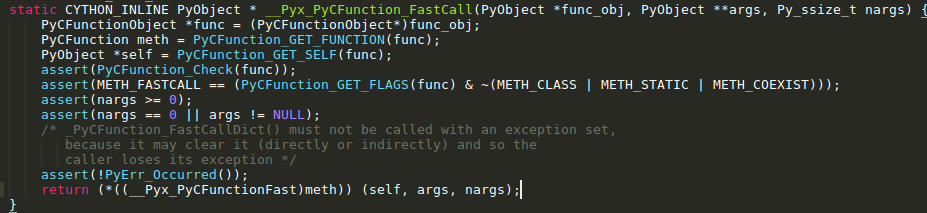
2、显示在PyThreadState中没有exc_type、exc_value、exc_traceback成员变量,通过查阅资料,以及看PyThreadState的源码了解到在版本1.5后,变量名称使用curexc_type、curexc_value以及curexc_traceback代替。所以这个错误只需要直接进行对应变量名的替换即可。

需要改的内容分别在utils/nms/cpu_nms.c、utils/nms/gpu_nms.c、utils/pycocotools/_mask.c,将这些文件进行上述修改即可。
此时执行完成./make.sh
在完成make.sh,配置好相关信息后,使用train_RFB.py文件进行训练,此时我是直接使用RFB_mobile版本的checkpoints,使用VOC数据集进行训练,同时设置size为300。
python train_RFB.py -d VOC -v RFB_mobile -s 300
-d:dataset的格式,VOC或COCO -v:使用的RFBNet的版本,RFB_vgg、RFB_mobile、RFB_E_vgg -s:图片的size
其中还有一些其他的参数,可以从train_RFB.py代码中详细查看,其中最主要的要设定网络的basenet
在此基础上,通过对应的github下载了mobilenet_feature.pth,当然下载vgg16的操作也是类似的,这些都只是一个预训练的模型。
在这个过程中,我也遇到了一些问题,因为当时的服务器上的0卡GPU已经被两个程序占用,剩余的内容非常小,而且RFBNet中的代码使用CUDA又是从服务器中的第一个GPU开始启动的,所以最后出现了
RumtimeError: CUDA Error, out of memory.
当时我很奇怪,明明还有其他的GPU卡没有被占用,为什么不能直接调用,最后发现是程序本身的问题,或者也可以说是CUDA配置的问题。默认的CUDA_VISIBLE_DEVICES是包含所有的GPU卡的,而且没有预先定义CUDA_VISIBLE_DEVICES在使用时也会出错;在网上看到的一个解决方法就是更改默认的可见GPU的序号,使用如下代码:
import os os.environ[‘CUDA_VISIBLE_DEVICES’]=’2,3’
在程序设置过程中,CUDA_VISIBLE_DEVICES被视为一个字符串,需要用引号进行赋值,但是在设置过程中,一直出现大致是说CUDA_VISIBLE_DEVICES不存在的意思,最后查看了一下声明的变量里面确实没有这个,所以需要在命令行中执行一下命令:
export CUDA_VISIBLE_DEVICES=0,1,2,3,4
不管其他,我觉得系统的变量还是最好能将整个服务器所有的GPU的序号都包括进去是比较好的,在使用的时候可以在当前程序中直接指定修改使用哪个GPU会更好。
之后就可以按照自己的需要进行训练或者测试了
1)我在训练时,使用RFB_mobile,共进行了epoch=200多次,最后保存的pth在205次。这个训练代码可以每10次进行保存一次。

2)然后使用最后的训练结果进行测试
python test_RFB.py -d VOC -v RFB_mobile -s 300
当然在test_RFB.py文件中也需要对对应的checkpoints的路径进行更改。
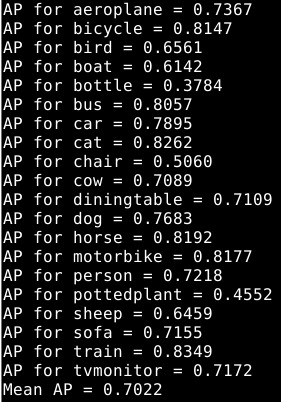
这里的mAP仅有70.2%,我觉得一方面是因为我只训练了200多个epoch,总共有1500个左右,训练不够充分,同时也有使用了RFB_mobile模型的缘故,如果直接使用RFB_vgg可能效果会更好。
最后,我认为对于复现代码,最好是能够自己独立解决报错的信息,在这个过程中可以发现以前编辑的代码与现在的不同之处,同时也能够锻炼一下自己解决问题的能力,而不是直接就上网开始搜对应的教程什么的。