Redis全面入门
引子
在互联网系统开发中,随着系统的业务新增迭代功能的日益繁杂,传统的关系型数据库频繁IO读取会影响系统的速度,严重还会造成数据库宕机(这里普及一个基础知识,数据库IO操作属于与硬盘交互,速度慢与内存交互),所以光靠数据库往往不能有效支持功能业务,这个时候常常需要的Nosql作为功能业务的拓展和延伸,从而降低数据库的压力,Redis作为键值对非关系内存数据库,是目前最广泛也是最为常用的中间件解决方案。
Redis是什么
Redis是遵守BSD协议、支持网络、可基于内存亦可持久化的非关系型key-value数据库,对比memcached(内存缓存,不可以持久化)有着能够持久化的优势,因为性能强大支持每秒10万的QPS,单线程(线程安全),哨兵模式集群简单,多种数据类型,主从复制可持久化,支持订阅发布等优点常常作为缓存,数据库,消息通知,分布式锁等。
数据类型
Redis支持5种数据类型分别是:String、Hash、List、Set、SortedSet
String最基本的数据格式, Value最多可以容纳的数据长度是512M,常用set,get命令进行键值对存储可设置有效时间,其中setex命令是原子性操作,支持设置有效时间,该命令在Redis 用作缓存时,非常实用。
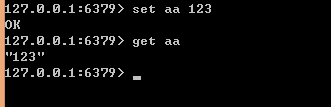
Hash是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象,Redis 中每个 hash 可以存储 232 - 1 键值对(40多亿)。常用命令hset,hget
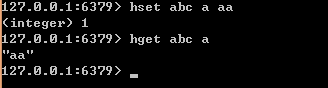
List列表,是简单的字符串列表,按照插入顺序排序,可以从左,右插入(头,尾),一个列表最多可以包含 232 - 1 个元素 (4294967295, 每个列表超过40亿个元素)。常用命令rpush(插入元素),lrange(根据列表key和下标范围获取列表数据)
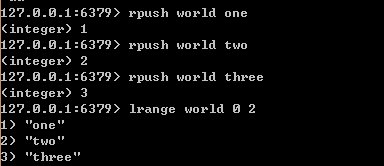
Set是String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。Set集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1),集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。常用命令sadd(添加一个或者多个元素),sdiif(返回一个集合全部成员)
Sortedset也叫zset是set集合的升级版,它是有序集合,可以在新增元素的时候指定顺序,不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。有序集合的成员是唯一的,但分数(score)却可以重复。
应用场景
Redis比较适合,数据实时性要求不高,又需要频繁操作的业务(页面访问统计,功能点击统计,好友点赞),或者做热点数据(做业务缓存,配置缓存),例如做活动的范围数据存储(例如XX门店等),zset适合做排行榜,排序排名处理都非常方便,INCR 命令适合非常适合做计数,限时业务,例如(限时商品,拼团时限,验证码)等,redis还可以做分布式锁,例如setex就是原子性操作,这些都是Redis比较常见的应用场景。
关于Redis的一些问题
Redis为什么性能强大?
首先Redis基于内存操作,避免大量访问数据库,把数据保存在内存中,操作数据的时候不会受到IO速度影响,所以速度快,其次Redis是单线程操作,避免了线程竞争,减少了系统线程调度的资源消耗,不用考虑多线程并发之间锁的问题,而且Redis采用了非阻塞 I/O多路复用机制,极大的加强了工作的效率。
Redis持久化
持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失,Redis不同于memcached的地方是,Redis的数据可以进行持久化,Redis的持久化分为RDB和AOF两种机制
RDB机制是定时定范围文件持久化,优势是文件单一,恢复速度快,消耗性能资源空间少,非常适用于灾难恢复,RDB在保存RDB文件时父进程唯一需要做的就是fork出一个子进程,接下来的工作全部由子进程来做,父进程不需要再做其他IO操作,所以RDB持久化方式可以最大化redis的性能.,缺点也很明显就是Redis服务器出现宕机后,丢失数据量比较大,宕机前未保存的数据就会丢失掉。
AOF机制是实时持久化,他的优点策略多宕机丢失数据少,使用不同的fsync策略:无fsync,每秒fsync,每次写的时候fsync.使用默认的每秒fsync策略,Redis的性能依然很好(fsync是由后台线程进行处理的,主线程会尽力处理客户端请求),一旦出现故障,你最多丢失1秒的数据.,AOF文件是一个只进行追加的日志文件,Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写,切绝对安全,缺点就是体积相比RDB文件较大,在使用fsync策略的情况下,性能速度低于RDB机制。
在两种持久化机制直觉如何选择,一般来说, 如果想达到完美的数据安全性, 你应该同时使用两种持久化功能这也是官网推荐的。如果你可以承受数分钟以内的数据丢失, 那么你可以只使用 RDB 持久化。
Redis如何保证数据一致性
在使用缓存的业务场景中,经常会遇见数据一致性的问题,指的是Redis中的缓存数据和数据库的中的数据存在差异(时效差异,数据差异),只要是使用缓存,就肯定会回出现一致性问题,无法保证原子性,在业务设计上只能尽量规避这种问题发生,目前有以下几种的处理方式
1、先删缓存再更新数据库,缺点,在删除缓存更新数据库的操作中,其他线程发现缓存中没有数据就会去读取数据库,然而数据库还没有更新成功,就会读出旧的的数据,造成数据不一致问题
2、先更新数据库在删除缓存,缺点,在更新数据库的时候,其他线程发现缓存有数据,就读取了旧的数据,没有读取到数据库更新的数据,造成数据不一致
这两种方法都无法完美的解决数据一致性问题,在业务中如果需要强一致性数据,尽量不要放在缓存中。
什么叫缓存击穿,缓存穿透,缓存雪崩
缓存击穿是指,大量的请求访问换一个缓存和数据库都不存在的数据,大量的请求在一时间全部访问到数据库上面,导致数据库压力过大,可以通过IP访问限流,权限校验,等方式来防止恶意的请求。
缓存穿透是指,大量的请求访问一个缓存过期,但是数据库存在的数据,在一段时间内大量请求访问数据库,导致数据库压力过大,解决方案设置热点数据的不过期,在业务增加互斥锁来限制。
缓存雪崩是指,大量的缓存同一时间过期,在一段时间内大量请求访问数据库,导致数据库压力过大,解决方法缓存设置随机的过期时间,保证不会同时大量缓存过期。
Redis的架构模式
1、单机模式:单台Redis服务器给一个或多个服务器进行操作访问,适合系统或者业务初期阶段,维护成本低配置简单,缺点处理能力有限,无法保证高可用。
2、主从模式:一台master服务器多台从服务器slave,master数据同步给slave,降低了master的读取压力,转交了部分给了slave,主从数据相同,缺点无法保证高可用,没有解决master写入压力
3、哨兵模式:Redis sentinel 是一个分布式系统中监控 Redis 主从服务器,并在主服务器下线时自动进行故障转移,通过监听各个节点的服务器 ,服务器master如果出现以宕机立刻提醒,且切换到slave从服务器,实现故障自动迁移,缺点没有解决解决master写入压力,且切换节点有时间限制
4、集群(proxy)模式:通过一个proxy代理端,来连接多个Redis服务器,多种 hash 算法:MD5、CRC16、CRC32、CRC32a、hsieh、murmur、Jenkins,支持失败节点自动删除,业务方的读写方式和操作单个 Redis 一致,缺点增加了新的 proxy,需要维护其高可用,故障逻辑需要自己实现,服务器扩容需要手动操作,自身不支持故障转移,拓展性差。
5、(cluster)直连集群:无中心结构,Redis节点之间互相串联,数据共享,支持动态拓展删除节点,支持高可用,部分节点失效不影响集群使用,缺点数据通过异步复制,不保证数据的强一致性,资源隔离性差容易出现互相影响。