前言
学习机器学习和数据挖掘的相关知识也有一段时间了,平时事情比较多也就懒得做笔记, 回忆起来,AndrewNg 在coursera上开设的机器学习课程受益匪浅,课程覆盖了机器学习的基础内容,深入浅出,把很多概念解释得很到位。
以AndrewNg的课程为出发点,参考多本经典的教材,对经典的机器学习和数据挖掘的思想和算法进行总结回顾,一来是为了对自身学习做一个总结,二来是与大家分享学习过程,共同学习,欢迎批评指正。
相关算法的实现
由于课程的代码不能公开,本文对《机器学习实战》一书给出的算法实现进行了重写和整理,会不定期更新,可以参考:
https://github.com/hfl15/MLinAction
整理的系列文章中主要参考的书目如下:
[1] Andrew Ng Machine Learning Course : https://zh.coursera.org/learn/machine-learning
[2]《机器学习实战》(Machine Learning in Action) —— Peter Harrington
[3] 《数据挖掘概念与技术》—— Jiawei Han,Micheline Kamber
[4] 《机器学习》—— Tom Mitchell
[5] 《机器学习》—— 周志华
[6] 《统计学习方法》—— 李航
Introduction
本部门主要对机器学习的基本概念以及相关的方法分类进行一个概要的介绍。进行的拓展主要在于总结和科普,没有进行详细详细的展开,后续会进一步进行展开或总结。
1. 机器学习的定义
ArthurSamuel(1959).MachineLearning:Fieldof study that gives computers the ability to learn without being explicitly programmed.
TomMitchell(1998)Well-posedLearning Problem: A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
以上两个定义中,普遍使用的后者。在进行机器学习的建模过程中,我们首要的任务是确定好三个基本要素,即经验(experience,E)、任务(task, T)和效果(performance, P)。学习是基于历史经验(E)的,直观的表现为采集的历史数据,学习的过程要针对特定的任务(T),即目的(比如说需要对邮件进行分类),能够拟合给定历史数据的模型假设有很多,如何挑选出好的假设,就需要定义好评估的标准(P)。
举个例子,对邮件进行分类,假设分成两类,即正常邮件和垃圾邮件,那么:
E: 事先采集好的一系列邮件,我们事先知道了每个邮件所属的类别(有标数据)
T: 将邮件分成两类:正常邮件和垃圾邮件
P: 正常分类的百分比
2. 机器学习方法分类
机器学习方法可以大致分为: 监督学习(supervised learning)和非监督学习(unsupervised learning),其最主要的区别在于我们是否可以获取到所学目标的分类。
2.1.监督学习:
对于任意样本,我们知道其目标值,通常也称为类标,当目标值是离散的,则是分类问题,当目标值是连续的,那么就是回归问题。
对于任意实例 (x,y),x为向量,通常称为特征向量,每一个维度表示目标的一个属性,y为目标值,即实例的类标,当y为离散值时是分类问题,y为连续值是回归问题。
分类问题,如图1所示。假设样本实例为一些列的患者,我们希望给予两个属性,即x1(肿瘤大小)和x2(肿瘤个数),来对患者是否患有癌症进行预测。每一个患者用表示为图中一点,⭕️表示一类(非癌症患者),✖️表示一类(癌症患者)。有监督的学习过程是基于有类标的数据(通常称为训练集)将出一个分类面,通常称为假设h(x)=y,此处y=1(癌症患者)或y=0(非癌症患者),将训练集划分成两类。当新数据到来时,根据学习的假设h(x)可以对患者是否患癌症作出预测。

2.2.非监督学习
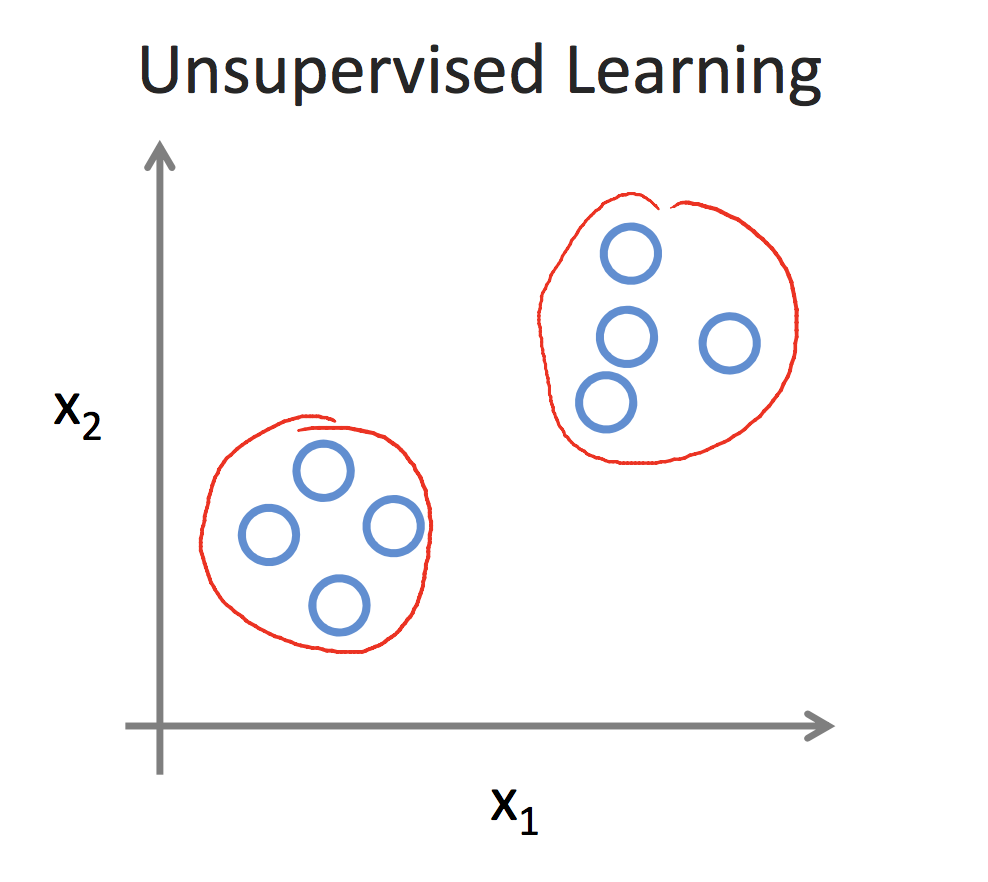
非监督学习中,我们无法事先获取到样本的类标,即如图3所示,每个⭕️表示一个样本,很明显样本可以划分成两个蔟,这两个蔟之间相距很远,但蔟内各样本点之间很近。聚类是非监督学习的典型,而关键在于距离函数的定义,即如何衡量样本之间的相近程度,一般我们认为距离相近的两个样本点属于一个蔟。常用的聚类算法有k-mean,dbscan等。
3.其他概念
这里稍微概括的介绍一下机器学习中的一些重要概念。
[1] 半监督学习
半监督学习介于监督学习和非监督学习之间。监督学习的训练集是打了类标的,即我们事先知道样本中的邮件是否为垃圾邮件,基于这一经验来对模型进行训练;而非监督学习的训练集是不知道类标的,我们只能基于某种相似性或是结构特征将样本分成不同的蔟。现实生活中我们很难获取到大量的标记数据,通过人工大类标也是费时费力的,因此就有了半监督学习方法的提出,其核心思想是,我们先通过少量的标记数据来训练模型,然后基于某种方法将未标记的数据也用上,对模型进行自动的进一步的优化。
[2] 主动学习
主动学习与半监督学习有点相似,半监督学习期望自动的利用未标记数据进行学习,而主动学习则可以看成是半自动的利用未标记的数据。其核心思想是,利用少量的标记数据训练模型,基于当前模型尝试对未标记的数据进行标记,如果模型对当前标记的结果把握不大,则可以对人发起帮助请求,询问当前样例的类标,通过人的反馈对模型进行优化,而对于把握大的结果则不发出询问。
[3] 增强学习 (reinforcement learning)
增强学习是一个交互学习的过程,通常用马尔可夫决策过程来描述,其核心在于打分机制。以下棋为例子进行说明,每个棋局表示一个状态,在当前状态有不同的下法,即下一个棋子应该如何走,每一种策略都会将当前状态转换到下一状态,假设为x1,x2,...,xn,对于每一个转换造成的后果我们给予一个分数,分数表明了赢的可能性,那么在下棋过程以贪心的策略选择分数最高的策略。
[4] 集成学习 (ensemble learning)
集成学习的核心思想是将多个弱的分类器集合成一个强的分类器。打个比方,小明要去看病,看是否发烧,为了更准确,小明看了5个大夫,其中有4个大夫说小明没有发烧,只有1个大夫说小明发烧了,综合来看,如果每个大夫各有一票,最后少数服从多数,小明应该是没有发烧。
在机器学习中也是如此,我们通常希望将多个分类器集合起来,综合各个分类器的结果作出最后的预测。最简单的就是投标机制,少数服从多数。假设训练有k个分类器,对于任意实例,同时输入到k个分类器中,获取k个预测结果,依据少数服从多数的原则对实例进行分类。
[5] 模型选择 (model selection)
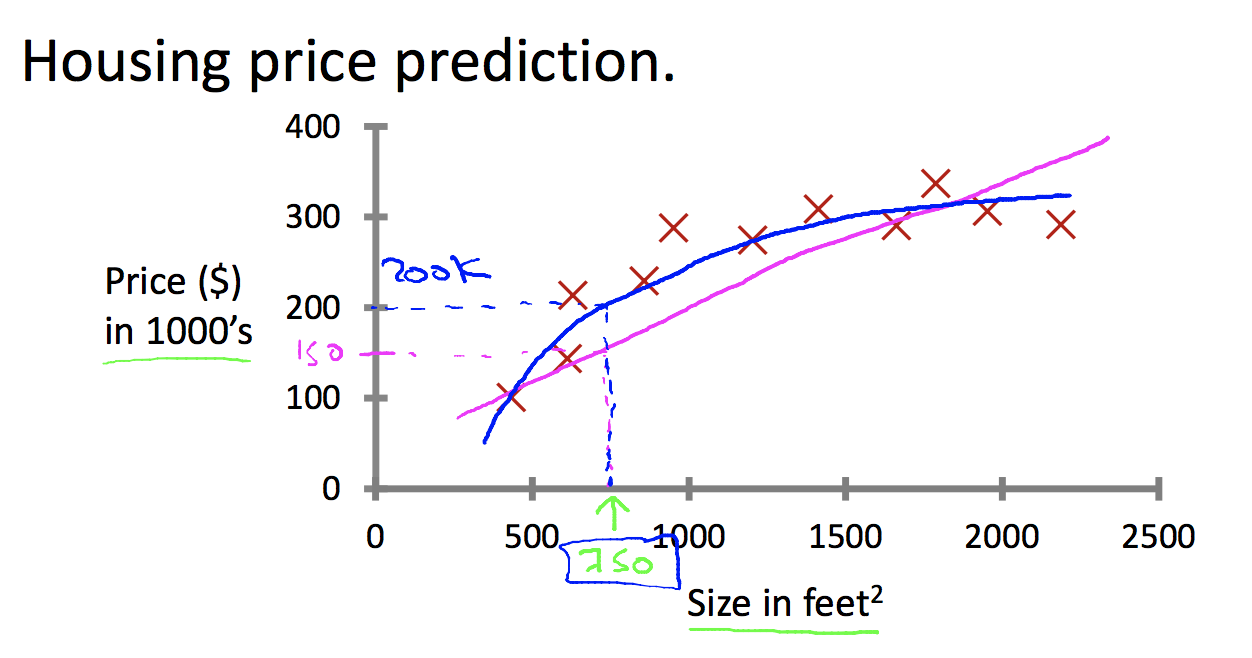
在机器学习中,能够反映历史经验的模型有很多,如图2所示,能拟合数据的有两条曲线,那么如何从众多候选中选出好的模型是一个很重要的话题。我们希望一个好的模型,不但在训练集(见过的数据)上具有很好的效果,我们还希望其对未见过的数据也具有很好的预测效果,即具有好的泛化能力。此处涉及到两个重要名词,即过拟合和欠拟合。欠拟合是指模型在所有数据上(见过的和未见过的)数据上表现都很差,没有能够很好的抽象模型。过拟合是指模型在见过的数据上表现很好,但对未见过的数据上表现很差,也就是模型通过拟合极端的数据来获取好的效果,学习的模型太过于具体,以至于对未见过的数据没有预测能力。我们通常会使用精确度来衡量预测的结果的好坏。保证预测精度还不够,同等条件下我们更偏向于简单的模型,这就是著名的奥卡姆剃刀原则(Occam's Razor),"An explanation of the data should be mad as simple as possible,but no simpler"。
综上所述,模型选择过程中考虑的方向主要有两个:预测结果的好坏(比如准确率)和模型的复杂程度。
[6] 特征选择 (feature selection)
如图1的例子,患者是否患有癌症的分类问题,我们考虑肿瘤的大小和肿瘤数量两个特征;如图2例子,房价的预测我们考虑房子大小的特征。特征的好坏,以及与目标的相关程度都在很大程度上影响了模型学习的效果。如果特征不足,或者与目标相关不大,学习出的模型很容易欠拟合。如果无关的特征过多会引起维度灾难,影响学习过程的效率。深度学习的效果好,是因为其隐藏层对特征具有很好的抽象作用。因此在进行模型学习的过程中,特征的选择也是很重要的课题。常用的特征选择方法有PCA,即主成分分析。