搭建神经网络:
- 准备数据
- 定义数据输入层
- 定义网络隐藏层和预测层
- 定义loss 表达式
- 选择optimizer使得loss 最小
import tensorflow as tf
import numpy as np
# 定义一个添加层的函数为网络构建做准备
# 默认情况下没有激活函数,input 是神经元输入, in_size 输入神经元的个数,out_size输出的个数。
def add_layer(inputs, in_size,out_size,activation_function=None):
weights=tf.Variable(tf.random_normal([in_size,out_size]))
# 定义权重是变量,在tensorflow中定义是一个变量才是变量
biase=tf.Variable(tf.zeros([1,out_size])+0.1)
# 矩阵乘法
w_plus_b=tf.matmul(inputs,weights)+biase
# 定义运算
if activation_function is None:
outputs=w_plus_b
else:
outputs=activation_function(w_plus_b)
return outputs
#1. 准备训练数据
x_data=np.linspace(-1,1,300)[:,np.newaxis]
# linspace 类似matlab 中的[-1:1:300],生成一个数组从-1 到300 每次加1,
# np.newaxis 等价于None,np.linspace 生成的是一个行向量,使用newaxis 增加一个维度大小为1 的新维度。x=[1,2,3],x.shape=3.,x[:,newaxis].shape=(3,1)在3后加一维
noise=np.random.normal(0,0.05,x_data.shape)
# 获得一个正态分布的值,和x_data大小相同, mu=0,v=0.05
y_data=np.square(x_data)-0.5+noise
#2. 定义节点接受数据
# 要给节点输入数据时,要用placeholder 占位符,类似于函数的参数描述待输入的节点,在运行时传入,和feed_dict是绑定使用的。
xs=tf.placeholder(tf.float32,[None,1])
ys=tf.placeholder(tf.float32,[None,1])
#3.定义网络结构
l1=add_layer(xs,1,10,activation_function=tf.nn.relu)
prediction=add_layer(l1,10,1,activation_function=None)
#4.定义loss
# reduce_sum 是求和,求和的对象时tensor,沿着tensor的某些维度求和。 本质是降维,reduce_sum 以求和的手段降维, reduce_mean 以求平均手段降维。 这种操作都有reduce_indices, 默认值为None,将tensor 降到0维
loss=tf.reduce_mean(tf.reduce_sum(tf.square(ys-prediction),reduction_indices=[1]))
#5.选择optimizer
# 使用梯度下降的方法,学习率为0.1,最小化loss
train_step=tf.train.GradientDescentOptimizer(0.1).minimize(loss)
#
# 初始化参数, 如果有变量一定要给变量初始化
init=tf.initialize_all_variables()
# 定义一个Session对象, 在session 中执行
sess=tf.Session()
sess.run(init)
# 迭代1000次,在sess中run optimizer
for i in range(1000):
# train_step 中loss 是由 placeholder 定义的运算,要用feed 传入参数
sess.run(train_step,feed_dict={xs:x_data,ys:y_data})
if i%50==0:
print(sess.run(loss,feed_dict={xs:x_data,ys:y_data}))
reduce_sum:

在tensorflow 1.0 中,reduction_indices 改为axis,
dropout 是训练过程中,按照一定概率将一部分神经单元暂时从网络中丢弃。
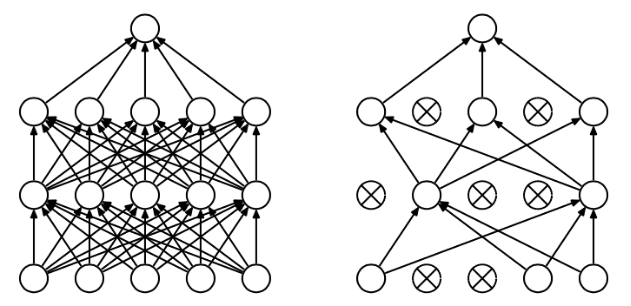
在tensorflow 中实现就是在add layer 函数中加上dropout,keep_prob保存多少不被drop
Wx_plus_b = tf.nn.dropout(Wx_plus_b, keep_prob)使用tensorboard: 要用with tf.name_scope 定义各个框架,