- SGD 中 stochastic 什么意思: Mini-Batch。。。
- 随机梯度下降算法(SGD)是mini-batch GD的一个特殊应用。SGD等价于b=1的mini-batch GD。即,每个mini-batch中只有一个训练样本。full batch GD每一轮迭代需要所有样本参与,对于大规模的机器学习应用,经常有billion级别的训练集,计算复杂度非常高。因此,有学者就提出,反正训练集只是数据分布的一个采样集合,我们能不能在每次迭代只利用部分训练集样本呢?这就是mini-batch算法。
- 监督学习、半监督学习、弱监督学习、无监督学习、迁移学习
- 无监督学习:训练样本数据和待分类的类别已知,但训练样本数据皆为非标签数据;k-聚类、主成分分析等
- 训练样本数据和待分类的类别已知,且训练样本数据皆为标签数据;支持向量机、线性判别;
- 训练样本数据和待分类的类别已知,然而训练样本既有标签数据,也有非标签数据;S3VM、S4VM、CS4VM、TSVM;
- 数据集的标签不靠谱,这里的不可靠可以是标记不正确,多种标记,标记不充分,局部标记等。半监督学习属于弱监督学习,半监督学习是弱监督学习的子集。弱监督学习可以看做是有多个标记的数据集合,次集合可以是空集,单个元素,或是多个元素的,分别表示没有标记,有一个标记,和有多个标记。在此统一声明为一个标记的集合。
- softmax loss
- 首先给出 Softmax function 的定义
-

-
对于一个输入,能够计算出对于没类的一个得分值,通sigmoid可以计算其预测概率值y,有了概率值之后loss计算为对最终正确分类所得的概率求一个LOG值,再取负。

设SoftmaxWithLoss层的输入为向量z,即bottom_blob_data,也就是上一层的输出。经过Softmax计算后的输出为向量f(z),公式为
 (省略了标准化常量m)。最后SoftmaxWithLoss层的输出
(省略了标准化常量m)。最后SoftmaxWithLoss层的输出 ,y为样本的标签
,y为样本的标签
-
反向传播:

由上面公式可知,如果输出层采用sfotmax,且loss用交叉熵形式,则最后一层的误差敏感值就等于CNN网络输出值f(x)减样本标签值e(y),即f(x)-e(y),其形式非常简单,这个公式是不是很眼熟?很多情况下如果model采用MSE的loss,即loss=1/2*(e(y)-f(x))^2,那么loss对最终的输出f(x)求导时其结果就是f(x)-e(y),虽然和上面的结果一样,但是大家不要搞混淆了,这2个含义是不同的,一个是对输出层节点输入值的导数(softmax激发函数),一个是对输出层节点输出值的导数(任意激发函数)。而在使用MSE的loss表达式时,输出层的误差敏感项为(f(x)-e(y)).*f(x)’,两者只相差一个因子。
这样就可以求出第L层的权值W的偏导数:
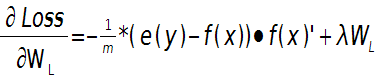
输出层偏置的偏导数:
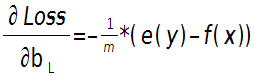
上面2个公式的e(y)和f(x)是一个矩阵,已经把所有m个训练样本考虑进去了,每一列代表一个样本。
CNN最成功的应用是在CV,那为什么NLP和Speech的很多问题也可以用CNN解出来?为什么AlphaGo里也用了CNN?这几个不相关的问题的相似性在哪里?CNN通过什么手段抓住了这个共性?
都存在局部与整体的关系,由低层特征经过组合,组成高层特征,并且得到不同特征之间的空间相关性。如低层特征:直线曲线->中层特征:形状->高层特征:汽车。CNN抓住此共性的手段主要有四个:局部连接/权值共享/池化操作/多层次结构。局部连接使网络可以提取数据的局部特征;权值共享大大降低了网络 的训练难度,一个Filter只提取一个特征,在整个图片(或者语音/文本) 中进行卷积;池化操作与多层次结构一起,实现了数据的降维,将低层次的局部特征组 合成为较高层次的特征,从而对整个图片进行表示。
- 为什么很多做人脸的Paper会最后加入一个Local Connected Conv?
当不存在全局特征分布时(鼻子,嘴。。。),Local-Conv更适合特征的提取,Local-Conv:
- 什麽样的资料集不适合用深度学习?
数据集太小,数据样本不足时,深度学习相对其它机器学习算法,没有明显优势。
数据集没有局部相关特性,目前深度学习表现比较好的领域主要是图像/语音/自然语言处理等领域,这些领域的一个共性是局部相关性。图像中像素组成物 体,语音信号中音位组合成单词,文本数据中单词组合成句子,这些特征元素的组合一旦被打乱,表示的含义同时也被改变。对于没有这样的局部相关性的数据 集,不适于使用深度学习算法进行处理。举个例子:预测一个人的健康状况,相关的参数会有年龄、职业、收入、家庭状况等各种元素,将这些元素打乱,并 不会影响相关的结果。