词法单元的规约:
- 串和语言:
- 字母表:一个有限的符号集合,符号的典型例子包括字母、数位和标点符号
- 串:字母表中符号的一个有穷序列
- 串s的前缀:从s的尾部删除0个或多个符号得到的串
- 串s的后缀:从s的开始处删除0个或多个符号后得到的串
- 串s的子串:删除s的某个前缀和某个后缀之后得到的串
- 串s的真前缀:s的既不属于ε,有不等于s本身的前缀
- 串s的真后缀:s的既不属于ε,有不等于s本身的后缀
- 串s的真子串:s的既不属于ε,有不等于s本身的子缀
- 串s的子序列:是从s中删除0个或多个符号后得到的串,被删除的符号可能不相邻
- 串的运算:
- 语言:字母表上一个任意的可数的串集合
- 语言上的运算:
- 例:

- 语言上的运算:
- 句子:属于语言的串
- 正则表达式:
- 正则表达式可以描述所有通过并、链接和闭包等运算产生的某个字母表的语言
- 等价:两个正则表达式 r 和 s 表示相同的语言,则称 r 和 s 是等价
- 正则表达式的构建:
- 归纳基础:
- ε是一个正则表达式,L(ε) = |ε|,即该语言只包含空串
- 如果α是Σ上的一个符号,那么a是一个正则表达式,并且L(a) = |α|,即着语言仅包含一个长度为1的符号串α
- 归纳步骤:由小的正则表达式构造大的正则表达式的步骤有四个部分,假定r 和 s 都是正则表达式,分别表示语言L(r) 和 L(s):
- (r) | (s) 是一个正则表达式,表示语言L(r) | L(s)
- (r)(s) 是一个正则表达式,表示语言L(r)L(s)
- (r)*是一个正则表达式,表示语言(L(r))*
- (r)是一个正则表达式,表示语言L(r),表达式两边加上括号并不影响表达式所表达的语言
- 简化:
- 一元运算符 * 具有最高的优先级,并且是左结合的
- 连接具有次高的优先级,它也是左结合的
- | 的优先级最低,并且也是左结合的
- 例:
- 归纳基础:
- 正则集合:由一个正则表达式定义的语言
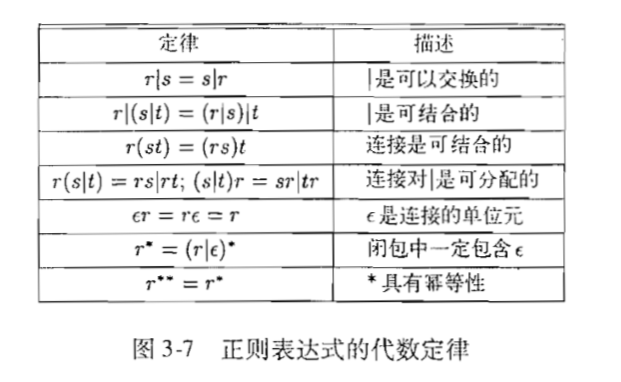
- 正则表达式的代数定律:
- 正则定义:
- 一个复杂的正则式, 通常是由多个子正则式, 经过某些运算后得到的正则式,可以对子正则式命名,使正则式简洁化
- 是一种描述模式的重要表示方法
- 定义:具有如下形式的定义序列:
- d1→r1,d2→r2,..........,dn→rn
- 每个di都是一个新符号,它们都不在 Σ 中,并且各不相同
- 每个ri是字母表 Σ υ {d1,d2,.......,di-1}上的正则表达式,其中Σ是基本符号的集合
- 例:
- 一个复杂的正则式, 通常是由多个子正则式, 经过某些运算后得到的正则式,可以对子正则式命名,使正则式简洁化
- 正则表达式的扩展:
- 使正则表达式更易于表达模式
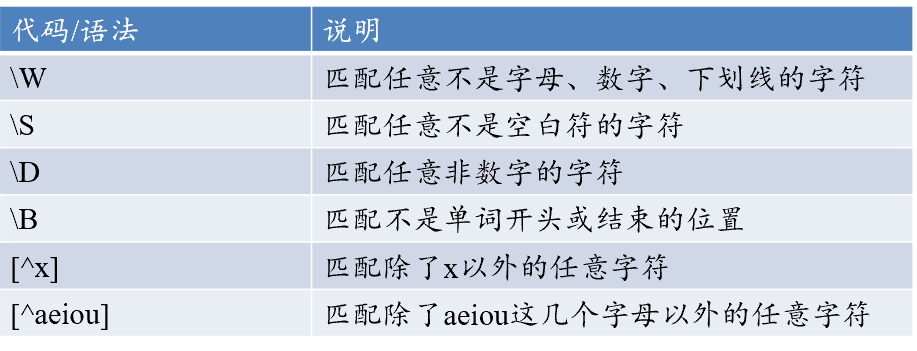
- 元字符:
- 反义:
- 重复:
-
- 贪婪与懒惰:
-
- 例:
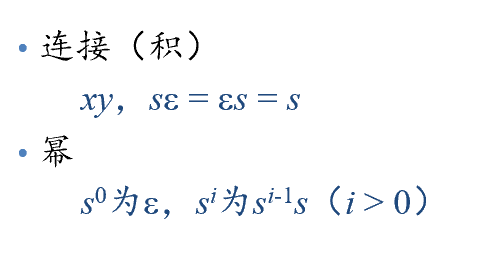











参考——《编译原理(第二版)》