一. 从输入网址到看到网页内容的这个过程中到底发生了什么
不谈浏览器解析文件那部分哦。
过程如下:
1. 输入网址
2. 浏览器查找域名的IP地址
域名解析过程如下:
1)浏览器缓存——浏览器会缓存DNS记录一段时间。有趣的是,操作系统并不会告诉浏览器要存多久,所以浏览器会存一个固定的时间,大约2~30分钟。
2)系统缓存——如果浏览器缓存中没有要找的记录,浏览器会做一个系统调用(Windows中是gethostbyname)。操作系统有自己的缓存记录。
3)路由缓存——请求会发向路由器,路由器一般会有自己的缓存记录。
4)ISP DNS缓存——下一个被查询的是ISP的域名服务器缓存记录。在这里一般都能找到需要的缓存记录。
3. 浏览器给Web服务器发送一个http请求
下面是在浏览器的调试窗口中截取的CSDN个人主页的http请求头部
4. 网站服务的永久重定向响应
服务器给浏览器响应一个301永久重定向响应,为什么服务器一定要重定向而不是直接发会用户想看的网页内容呢?其中一个原因跟搜索引擎排名有关。如果一个页面有两个地址,就像http://www.igoro.com/ 和http://igoro.com/,搜索引擎会认为它们是两个网站,结果造成每一个的搜索链接都减少从而降低排名。而搜索引擎知道301永久重定向是什么意思,这样就会把访问带www的和不带www的地址归到同一个网站排名下。还有一个是用不同的地址会造成缓存友好性变差。当一个页面有好几个名字时,它可能会在缓存里出现好几次。
5. 浏览器跟踪重定向地址
现在浏览器知道了要访问的正确地址,它会发送另一个获取请求。
6. 服务器 “请求” 处理
服务器收到了GET请求,处理请求,并做出响应。
7. 服务器返回一个HTML响应
下面是截取的个人主页的http响应头部
8. 浏览器开始显示HTML
9. 浏览器发送请求,以获取嵌入在HTML中的对象
在浏览器显示HTML时,它会注意到需要获取其他地址内容的标签。这时,浏览器会发送一个获取请求来重新获得这些文件。这些文件就包括CSS/JS/图片等资源,这些资源的地址都要经历一个和HTML读取类似的过程。所以浏览器会在DNS中查找这些域名,发送请求,重定向等等…
二. HTTP头部信息
稍稍了解一下http协议的内容。
头部信息分三部分:
1. 通用头部:包含请求和响应消息都支持的头域
Request URL:请求的URL地址
Request Method:请求方法,get/post/put/……
Status Code:状态码,200为请求成功
Remote Address:路由地址
2. 请求头部
Accept:告诉web服务器自己接受什么介质类型,*/*表示任何类型
Accept-Charset:浏览器声明自己接收的字符集
Accept-Encoding:浏览器声明自己接收的编码方式,通常指压缩方式
Accept-Language:接收的语言,中文还是其他
Authorization:当客户端收到来自web服务器的WWW-Authenticate响应时,该头部来回应自己的身份验证
Connection:表示是否要持久连接,close/keep-alive。
Referer:浏览器向web服务器表明自己是从哪个网页获得/点击当前请求页面的
User-Agent:表明自己是哪种浏览器
Host:发送请求页面所在域
Cache-Control:浏览器应遵循的缓存机制
no-cache:不要缓存的实体,要求现在从服务器端取
max-age:之接受Age值小于max-age值,并且没有过期的对象
max-stale:可以接受过去的对象,但是过期时间必须小于max-stale值
min-fresh:接受其新鲜生命期大于当前Age和min-fresh值之和的缓存对象
Pramga:主要为Pragma:no-cache,相当于Cache-Control:no-cache
Range:浏览器(比如Flashget多线程下载时)告诉服务器自己想取对象的哪部分
Form:一种请求头标,给定控制用户代理的人工用户的电子邮件地址
Cookie:这是最重要的请求头信息之一
3. 响应头部
Age
Accept-Ranges
Cache-Control
Connection
Content-Encoding
Content-Language
Content-Length
Content-Range
Content-Type
Expired
Last-Modified
Location
Proxy-Authenticate
Server
Refresh
三. HTTP响应码
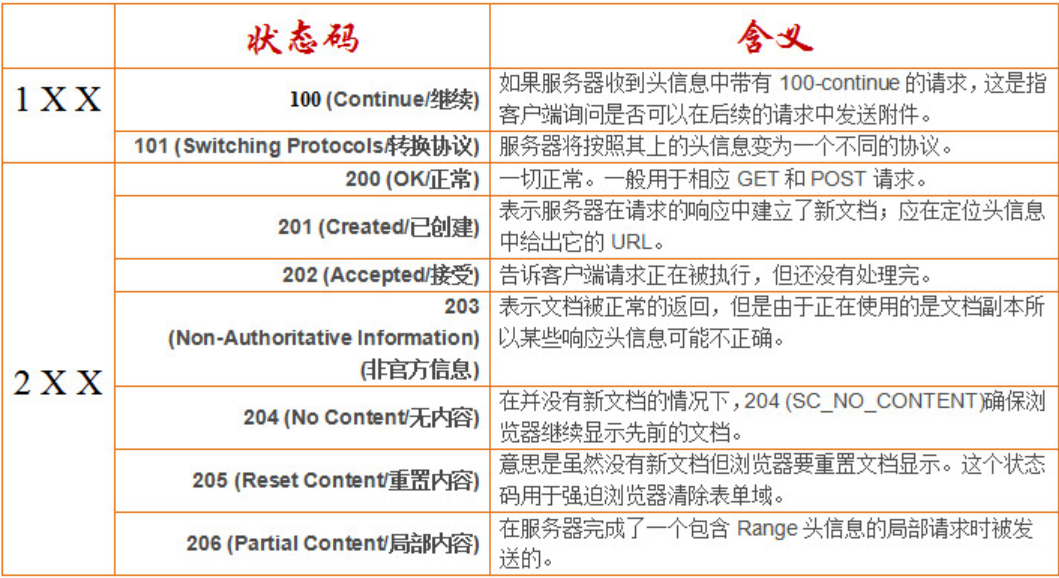


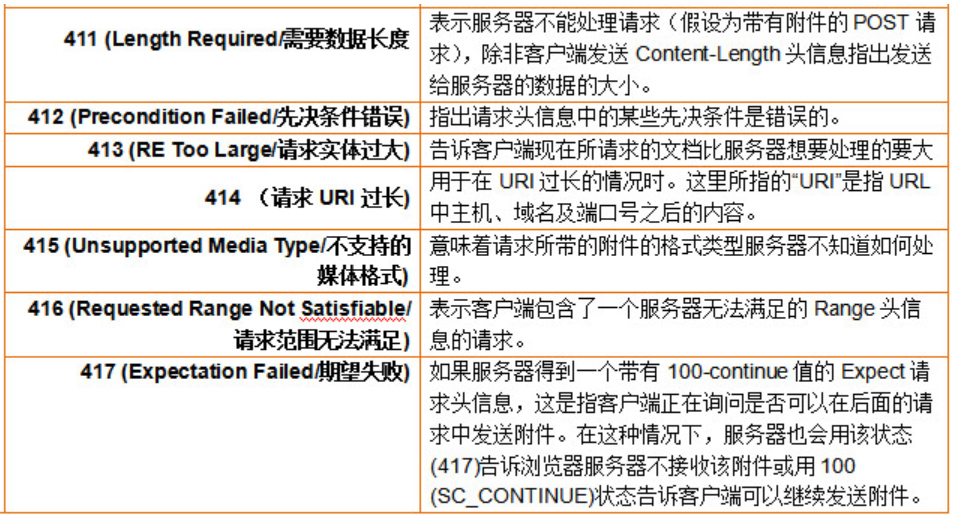
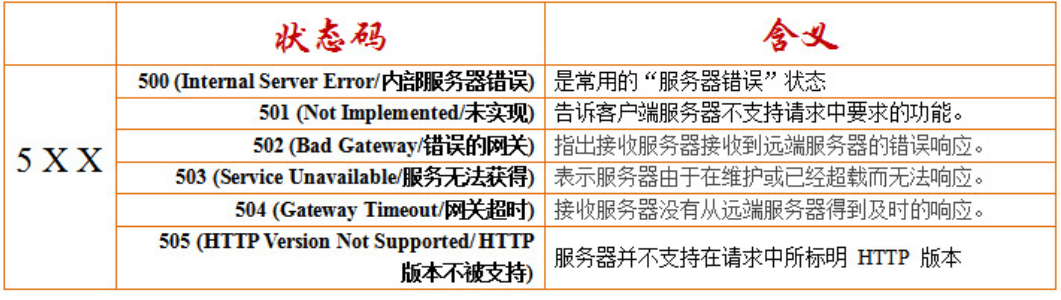
HTTP响应码出现在由HTTP服务器发送的响应的第一行,由三位十进制数字组成。分五种类型:
1xx:信息,请求收到,继续处理
2xx:成功,行为被成功地接受、理解和采纳
3xx:重定向,为完成请求,必须进一步执行的动作
4xx:客户端错误,请求包含语法错误或者请求无法实现
5xx:服务器错误,服务器不能实现一种明显无效的请求
版权声明:本文为CSDN博主「何-小鱼」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/hr10230322/article/details/78401475