学习神经网络
想拿lstm 做回归, 网上找demo 基本三种: sin拟合cos 那个, 比特币价格预测(我用相同的代码和数据没有跑成功, 我太菜了)和keras 的一个例子
我基于keras 那个实现了一个, 这里贴一下我的代码.
import numpy as np np.random.seed(1337) from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt import keras from keras.models import Sequential from keras.layers import Activation from keras.layers import LSTM from keras.layers import Dropout from keras.layers import Dense
# 数据的数量 datan = 400 X = np.linspace(-1, 2, datan) np.random.shuffle(X) # 构造y y=3*x + 2 并加上一个0-0.5 的随机数 Y = 3.3 * X + 2 + np.random.normal(0, 0.5, (datan, )) # 展示一下数据 plt.scatter(X, Y) plt.show()
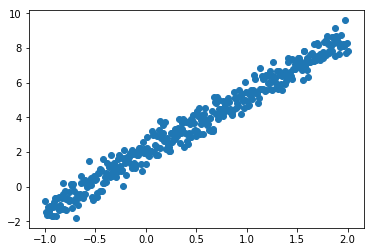
# 训练集测试集划分 2:1 X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.33, random_state=42)
# 一些参数 neurons = 128 activation_function = 'tanh' # 激活函数 loss = 'mse' # 损失函数 optimizer="adam" # 优化函数 dropout = 0.01
model = Sequential() model.add(LSTM(neurons, return_sequences=True, input_shape=(1, 1), activation=activation_function)) model.add(Dropout(dropout)) model.add(LSTM(neurons, return_sequences=True, activation=activation_function)) model.add(Dropout(dropout)) model.add(LSTM(neurons, activation=activation_function)) model.add(Dropout(dropout)) model.add(Dense(output_dim=1, input_dim=1)) # model.compile(loss=loss, optimizer=optimizer)
# training 训练
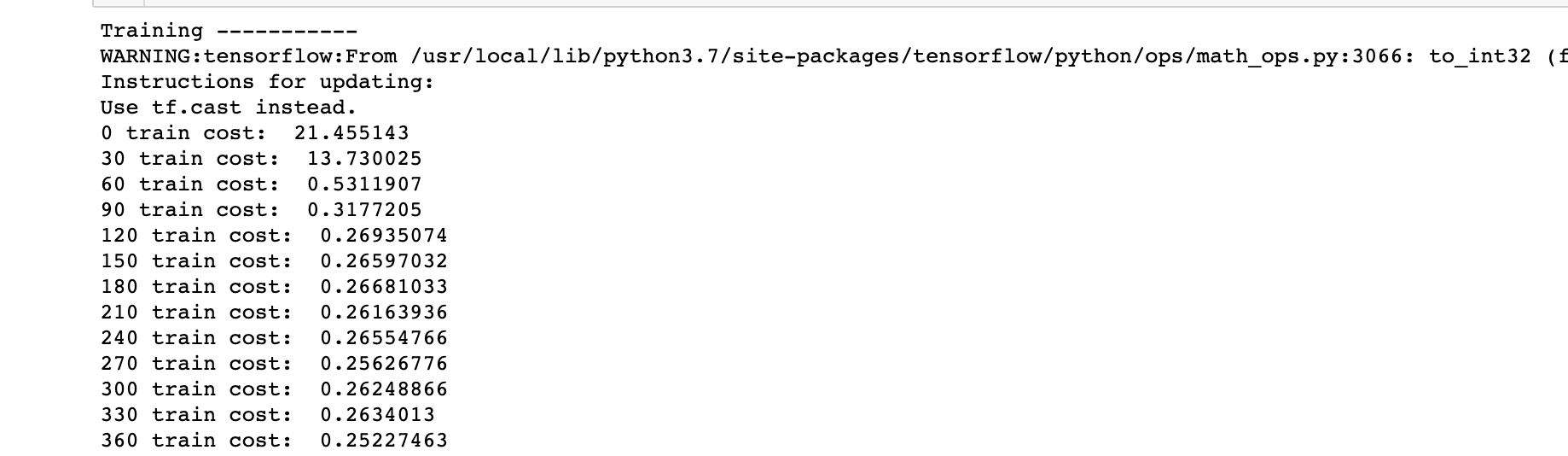
print('Training -----------')
epochs = 2001
for step in range(epochs):
cost = model.train_on_batch(X_train[:, np.newaxis, np.newaxis], Y_train)
if step % 30 == 0:
print(f'{step} train cost: ', cost)
# 测试
print('Testing ------------')
cost = model.evaluate(X_test[:, np.newaxis, np.newaxis], Y_test, batch_size=40)
print('test cost:', cost)

# 打印预测结果 Y_pred = model.predict(X_test[:, np.newaxis, np.newaxis]) plt.scatter(X_test, Y_test) plt.plot(X_test, Y_pred, 'ro') plt.show()
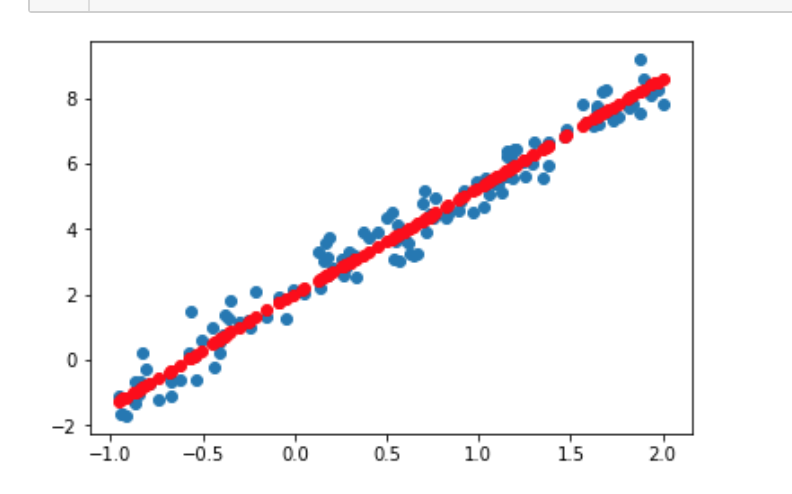
loss_history = {}
def run(X_train, Y_train, X_test, Y_test, epochs, activation_func='tanh', loss_func='mse', opt_func='sgd'):
"""
这里是对上面代码的封装, 我测试了一下各种优化函数的效率
可用的目标函数
mean_squared_error或mse
mean_absolute_error或mae
mean_absolute_percentage_error或mape
mean_squared_logarithmic_error或msle
squared_hinge
hinge
categorical_hinge
binary_crossentropy(亦称作对数损失,logloss)
logcosh
categorical_crossentropy:亦称作多类的对数损失,注意使用该目标函数时,需要将标签转化为形如(nb_samples, nb_classes)的二值序列
sparse_categorical_crossentrop:如上,但接受稀疏标签。注意,使用该函数时仍然需要你的标签与输出值的维度相同,你可能需要在标签数据上增加一个维度:np.expand_dims(y,-1)
kullback_leibler_divergence:从预测值概率分布Q到真值概率分布P的信息增益,用以度量两个分布的差异.
poisson:即(predictions - targets * log(predictions))的均值
cosine_proximity:即预测值与真实标签的余弦距离平均值的相反数
优化函数
sgd
RMSprop
Adagrad
Adadelta
Adam
Adamax
Nadam
"""
mdl = Sequential()
mdl.add(LSTM(neurons, return_sequences=True, input_shape=(1, 1), activation=activation_func))
mdl.add(Dropout(dropout))
mdl.add(LSTM(neurons, return_sequences=True, activation=activation_func))
mdl.add(Dropout(dropout))
mdl.add(LSTM(neurons, activation=activation_func))
mdl.add(Dropout(dropout))
mdl.add(Dense(output_dim=1, input_dim=1))
#
mdl.compile(optimizer=opt_func, loss=loss_func)
#
print('Training -----------')
loss_history[opt_func] = []
for step in range(epochs):
cost = mdl.train_on_batch(X_train[:, np.newaxis, np.newaxis], Y_train)
if step % 30 == 0:
print(f'{step} train cost: ', cost)
loss_history[opt_func].append(cost)
# test
print('Testing ------------')
cost = mdl.evaluate(X_test[:, np.newaxis, np.newaxis], Y_test, batch_size=40)
print('test cost:', cost)
#
Y_pred = mdl.predict(X_test[:, np.newaxis, np.newaxis])
plt.scatter(X_test, Y_test)
plt.plot(X_test, Y_pred, 'ro')
return plt
run(X_train, Y_train, X_test, Y_test, 2000) run(X_train, Y_train, X_test, Y_test, 2000, opt_func='Adagrad') run(X_train, Y_train, X_test, Y_test, 2000, opt_func='Nadam') run(X_train, Y_train, X_test, Y_test, 2000, opt_func='Adadelta') run(X_train, Y_train, X_test, Y_test, 2000, opt_func='RMSprop') run(X_train, Y_train, X_test, Y_test, 2000, opt_func='Adam') run(X_train, Y_train, X_test, Y_test, 2000, opt_func='Adamax') # arr = [i*30 for i in range(len(loss_history['sgd']))] plt.plot(arr, loss_history['sgd'], 'b--') plt.plot(arr, loss_history['RMSprop'], 'r--') plt.plot(arr, loss_history['Adagrad'], color='orange', linestyle='--') plt.plot(arr, loss_history['Adadelta'], 'g--') plt.plot(arr, loss_history['Adam'], color='coral', linestyle='--') plt.plot(arr, loss_history['Adamax'], color='tomato', linestyle='--') plt.plot(arr, loss_history['Nadam'], color='darkkhaki', linestyle='--') plt
最快的是 adadelta, 最慢的sgd. 其他差不多.