最近一个服务上线一个月后出现某个时间段响应延迟的问题,先看下监控数据:
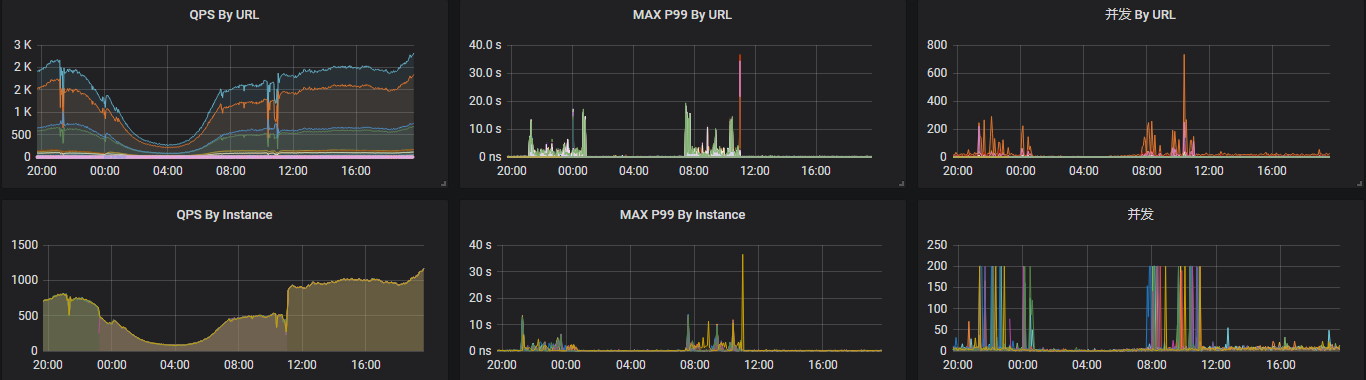
这里有一点,单台实例的并发最高达到200是因为没修改spring boot中tomcat默认的最大线程数(默认是200)。
从上图可以看出21点—24点以及第二天08点—11点服务的延迟已经达到s级别,甚至严重时已经达到30多s,整个app基本不可用。
问题第一次出现时,整个服务启了4台实例,dau是40万,所以当时单纯怀疑是因为访问量增加导致实例的请求线程被打满,出现请求阻塞导致的延迟。于是在24点时将服务增加到8台实例,响应出现好转。
但是第二天又出现类似情况,且更加严重,每台实例的qps只有500左右,所以分析是其他问题导致的请求耗时较高从而引起的请求阻塞。因为我们的服务很依赖redis,且对redis进行过一次降配(这个服务属于突然起量),于是redis的性能:
可以看到在出问题的时间段redis的延迟也达到s级别。于是查看redis的内存和cpu状态:
CPU load:
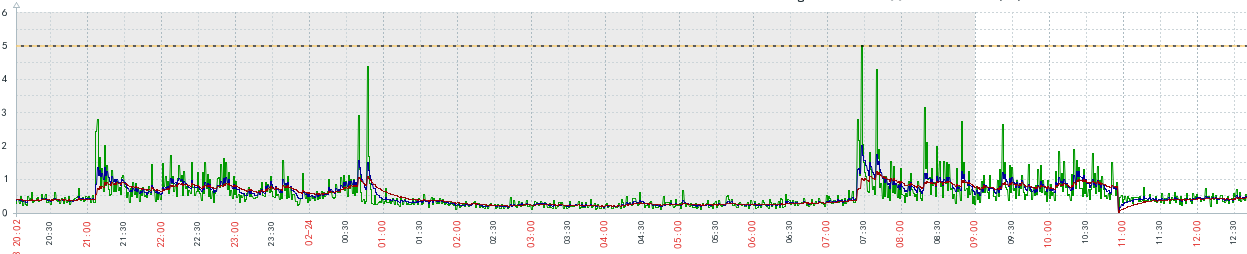
可以看到redis实例出现cpu load达到1以上,说明CPU阻塞严重,大量的处理请求在排队。
memory:
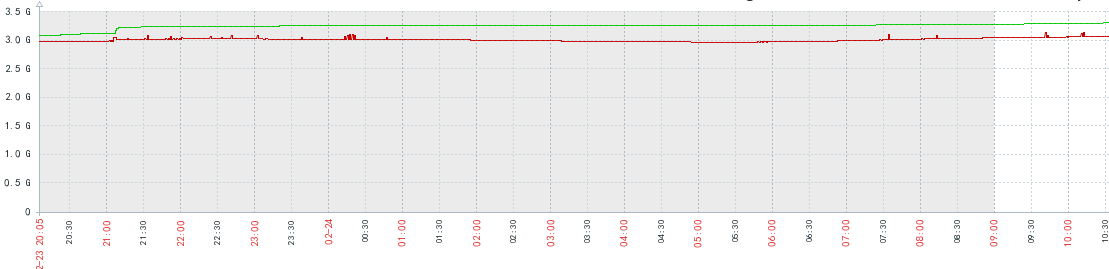
可以看到内存使用率已经达到90%以上,所以很明显redis内存存在问题,为了尽快解决线上问题,先进行redis内存的升级(使用的阿里服务,升级耗时3分钟),再去寻找内在具体原因。
进入redis集群,通过info查看redis状态:果然发现异常,rdb_last_bgsave_status:err
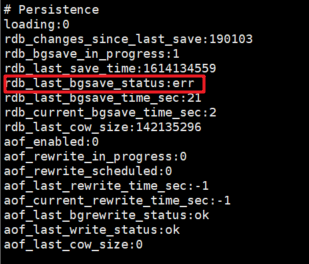
redis bgsave失败,使用的RDB持久化策略,bgsave会fork一个进程进行数据的持久化,具体的分析可以参考这篇文章,讲的很详细:https://zhuanlan.zhihu.com/p/89248752
通过以上分析,个人认为这次问题的具体原因是:
1、fork子进程会消耗CPU资源,通过下图可以看出,CPU随着定时执行的bgsave出现锯齿状波动

2、fork出的子进程和父进程会共享堆栈代码和内存,只有当父进程进行数据修改二者才会分离,所以出现这次问题的本质原因是因为内存使用率过高,而且redis的写请求量很大,所以导致bgsave时内存不足而发生错误,出现错误又会重新fork子进程去重新执行数据同步,所以导致CPU负载一直较高无法处理其他请求,从而hang住了整个客户端。
我觉得通过一点可以印证这一点,从00点到08点之间,其实redis内存的使用率一直很高,但是在这段时间用户的请求量较少,所以redis的写请求不多,也就不会导致bgsave因内存不足而发生报错。