下面通过模拟实例分析排查Java应用程序CPU和内存占用过高的过程。如果是Java面试,这2个问题在面试过程中出现的概率很高,所以我打算在这里好好总结一下。
1、Java CPU过高的问题排查
举个例子,如下:
package com.classloading;
public class Test {
static class MyThread extends Thread {
public void run() { // 死循环,消耗CPU
int i = 0;
while (true) {
i++;
}
}
}
public static void main(String args[]) throws InterruptedException {
new MyThread().start();
Thread.sleep(10000000);
}
}
使用top命令查看占用CPU过高的进程。如下图所示。
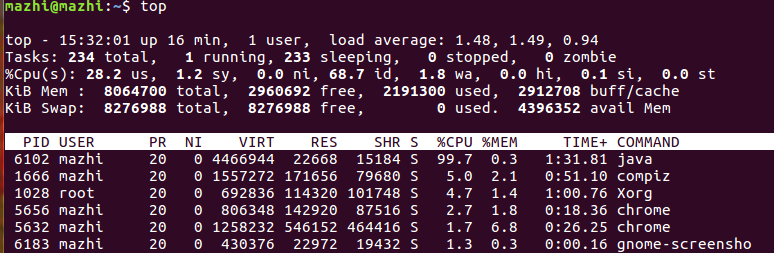
查看进程6102下线程的占用情况,如下图所示。

使用如下命令将6122转换为16进制表示,如下:

导出CPU占用高进程的线程栈。命令如下:
jstack pid >> java.txt
内容如下:
mazhi@mazhi:~$ cat java.txt
Attaching to remote server pid, please wait...
2021-02-23 15:38:18
Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.192-b12 mixed mode):
"Attach Listener" #10 daemon prio=9 os_prio=0 tid=0x00007f4ee0001000 nid=0x1956 runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
// 这是0x17ea线程,也是占用CPU最高的线程
"Thread-0" #9 prio=5 os_prio=0 tid=0x00007f4f180d6000 nid=0x17ea runnable [0x00007f4f044da000]
java.lang.Thread.State: RUNNABLE
at com.cpuhigh.Test$MyThread.run(Test.java:8) // 这里指示第8行,则正是死循环的代码开始
...
导出的堆栈信息有线程的状态(一般要找RUNNABLE状态)和调用堆栈结合来查找问题。线程dump分析:线程dump分析主要目的是定位线程长时间停顿的原因
jstack是一个瞬时堆栈只记录瞬时状态
实际排查问题的时候jstack建议打印5次至少3次,根据多次的堆栈内容,再结合相关代码段进行分析,定位高cpu出现的原因,高cpu可能是代码段中某个bug导致的而不是堆栈打印出来的那几行导致的。

cpu高的情况还有一种可能的原因,假如一个4核cpu的服务器我们看到总的cpu达到了100%+,按1之后观察每个cpu的us(用户空间占用cpu的百分比),只有一个达到了90%+,其他都在1%左右(下图只是演示top按1之后的效果并非真实场景):

这种情况下可以重点考虑是不是频繁Full GC引起的。因为我们知道Full GC的时候会有Stop The World这个动作,多核cpu的服务器,除了GC线程外,在Stop The World的时候都是会挂起的,直到Stop The World结束。以几种老年代垃圾收集器为例:
- Serial Old收集器,全程Stop The World
- Parallel Old收集器,全程Stop The World
- CMS收集器,它在初始标记与并发标记两个过程中,为了准确标记出需要回收的对象,都会Stop The World,但是相比前两种大大减少了系统停顿时间
无论如何,当真正发生Stop The World的时候,就会出现GC线程在占用cpu工作而其他线程挂起的情况,自然表现也就为某个cpu的us很高而且他cpu的us很低。
2、Java 内存过高的问题排查
堆dump分析:堆dump分析主要目的是定位OOM异常的原因;解决oom问题四 部曲:
1.分析OOM异常的原因,堆溢出?栈溢出?本地内存溢出?
2.如果是堆溢出,导出堆dump,并对堆内存使用有个整体了解;
3.找到最有可能导致内存泄露的元凶,通常也就是消耗内存最多的对象;
4.使用辅助工具对dump文件进行分析;
注意其他几类造成OOM异常的原因
1.Direct Memory
2.线程堆栈:单线程:StackOverflowError 多线程:OutOfMemoryError:unable to create new native thread
3.Socket 缓冲区:IOException:Too many open files
举个例子如下:
package com.classloading;
import java.util.ArrayList;
import java.util.List;
public class Test {
private static final int UNIT_MB = 1024 * 1024;
public static void main(String args[]) throws InterruptedException{
List<Object> x = new ArrayList<Object>();
int i = 0;
while(i<1000){
x.add(new byte[UNIT_MB]);
i++;
}
Thread.sleep(1000000000);
}
}
通过jmap dump内存快照。如果是线上环境,注意dump之前必须先将流量切走,否则大内存dump是直接卡死服务。
命令行输入:
jmap -histo <pid> | head -20
就可以查看某个pid的java服务占用内存排名前20的类,如下图所示。
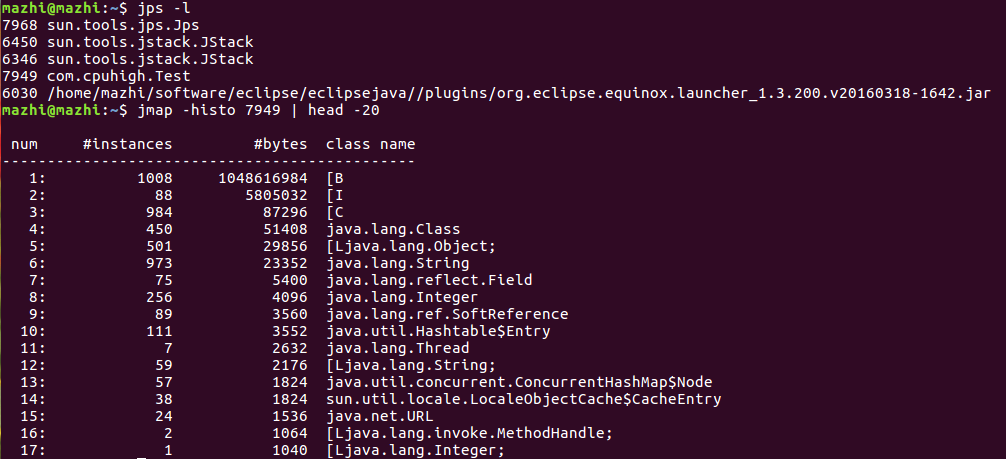
可以看到,占用内存最多的是byte字节数组,共有1008个实例。
jmap还有一个指令可以把整个内存情况转成文件形式保存下来,如下:
jmap -dump:format=b,file=filename.bin <pid>
执行命令如下图所示。

可以在JVM启动时设置,如果发生OOM,则dump出文件。命令如下:
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/heapdump.hprof
如果快照文件不大,可以下载到本地,然后通过MAT分析,也可以在线分析(https://fastthread.io/);如果快照文件很大,可以在服务器上直接分析,使用的命令是:
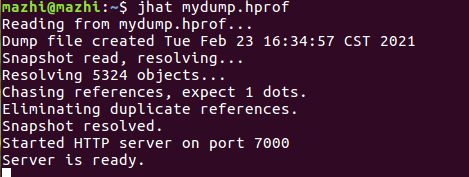
jhat dump.hprof
jhat也是jdk内置的工具之一。主要是用来分析java堆的命令,可以将堆中的对象以html的形式显示出来,包括对象的数量,大小等等,并支持对象查询语言。命令执行后如下图所示。
访问如下图所示。
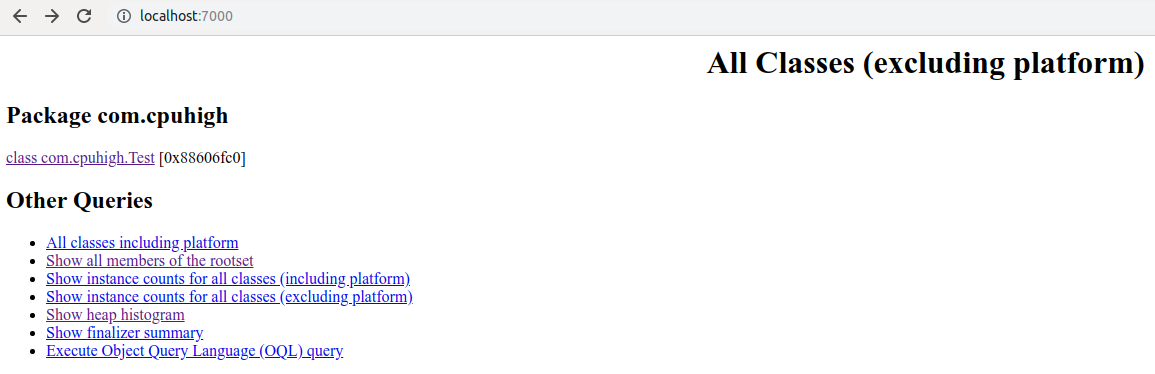
其中的Show heap histogram就会显示对象占用内在的大小。如下图所示。

使用MAT时,有时候这个工具还会提示某个对象异常。我们可以在Histogram 页面,可以查看到对象数量排序,我们可以看到 Byte[] 数组排在了第一位,选中对象后右击选择 with incomming reference 功能,可以查看到具体哪个对象引用了这个对象。
3、JVM的Error日志
致命错误日志文件位置可以通过 -XX:ErrorFile进行指定,相关的信息如下:
这个文件主要包含如下内容:
- 日志头文件
- 导致 crash 的线程信息
- 所有线程信息
- 安全点和锁信息
- 堆信息
- 本地代码缓存
- 编译事件
- gc 相关记录
- jvm 内存映射
- jvm 启动参数
- 服务器信息
这对于一般的开发人员来说不太容易读懂。在日志头文件中有常见的描述是“EXCEPTION_STACK_OVERFLOW”,该描述表示这是个栈溢出导致的错误,这往往是应用程序中存在深层递归导致的
4、Full GC的排查
如果FullGC只是发生在老年代区,比较有经验的开发人员还是容易发现问题的,一般都是一些代码bug引起的。MetaSpace发生的FullGC经常会是一些诡异、隐晦的问题,很多和引入的第三方框架使用不当有关或者就是第三方框架有bug导致的,排查起来就很费时间。
YGC如果频繁,会让对象过早进入老年代,如果回收时间过长,会造成系统停顿时间长,造成服务超时等问题。系统中有许多方法可以观察到Full GC,通常有3种方法,如下:
1、在系统中增加参数,记录相关信息,如下:
-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:/home/mazhi/workspace/projectjava/projectjava01/gclog/gc.log
某一次记录的日志信息如下:
Java HotSpot(TM) 64-Bit Server VM (25.192-b12) for linux-amd64 JRE (1.8.0_192-b12), built on Oct 6 2018 06:46:09 by "java_re" with gcc 7.3.0
Memory: 4k page, physical 8064700k(2091464k free), swap 8276988k(8276988k free)
CommandLine flags: -XX:InitialHeapSize=129035200 -XX:MaxHeapSize=2064563200 -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC
0.073: [GC (System.gc()) [PSYoungGen: 634K->320K(36864K)] 634K->320K(121856K), 0.0015284 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.075: [Full GC (System.gc()) [PSYoungGen: 320K->0K(36864K)] [ParOldGen: 0K->258K(84992K)] 320K->258K(121856K), [Metaspace: 2473K->2473K(1056768K)], 0.0035519 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
Heap
PSYoungGen total 36864K, used 1270K [0x00000000d6f80000, 0x00000000d9880000, 0x0000000100000000)
eden space 31744K, 4% used [0x00000000d6f80000,0x00000000d70bd890,0x00000000d8e80000)
from space 5120K, 0% used [0x00000000d8e80000,0x00000000d8e80000,0x00000000d9380000)
to space 5120K, 0% used [0x00000000d9380000,0x00000000d9380000,0x00000000d9880000)
ParOldGen total 84992K, used 258K [0x0000000084e00000, 0x000000008a100000, 0x00000000d6f80000)
object space 84992K, 0% used [0x0000000084e00000,0x0000000084e40b30,0x000000008a100000)
Metaspace used 2479K, capacity 4486K, committed 4864K, reserved 1056768K
class space used 265K, capacity 386K, committed 512K, reserved 1048576K
给出的信息还是比较全面详细的,包括堆和元空间GC前与GC后的变化,当前虚拟机使用的命令等。
2、通过监控查看,如Pinpoint APM监控工具等
3、通过Linux命令查看,如:
jstat -gc 4383 5000

当发现是Full GC频繁时,首先要知道,哪些情况下会触发Full GC,原因如下:
- 程序执行了System.gc();
- 执行了jmap命令;
- 大对象直接进入了老年代导致老年代内存不足,达到了GC阈值;
- 程序中存在内存泄露,导致老年代内存缓慢增长,且无法被回收,达到了GC阈值;
- 老年代存在内存碎片,导致新晋升的对象空间不足,触发GC。
对于第1个原因,如果老年代还有大量空闲空间时就触发,则有可能是调用了System.gc()。对于后面3个原因,通常需要观察Full GC之前与之后堆的内存变化来确定。可以通过GC日志或jvisualvm等图形化工具来查看,如果Full GC前与后堆回不到原来的大小并且堆大小一直增大,则可能是内存泄露,否则可能就是对象过于频繁进入老年代了,需要找出这些对象。可以通过jmap命令来dump出文件。我们可以在线上开启了 -XX:+HeapDumpBeforeFullGC。使用jvisualvm查看哪些对象占用的比较大的内存(能给出实例占用的大小和占用内存的百分比)
常用到的一些命令及图形化工具如下图所示。

5、应用故障你怎么样排除问题?
应用故障一般指应用运行缓慢、用户体验差或者周期性的出现卡顿,排除的思路:
1.检查应用所在的生产环境的软硬件以及网络环境,排除外围因素;
2.确定是否为OOM异常,这类异常影响最恶劣,但是比较容易排查;
3.确定是否有大量长时间停顿的应用线程,非常占用cpu资源;
4.周期性的卡顿很可能是垃圾回收造成,web后端系统建议使用cms垃圾回收器
6、什么情况下会发生栈内存溢出?
如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常。 如果虚拟机在动态扩展栈时无法申请到足够的内存空间,则抛出OutOfMemoryError异常。
7、频繁minor gc怎么办?可能造成的原因是什么?如何避免?minor gc运行的很慢有可能是什么原因引起的?
如下2个原因可能导致minor gc频繁:
1、 产生了太多朝生夕灭的对象导致需要频繁minor gc
2、 新生代空间设置的比较小
可以适当扩大新生代空间的大小,或者G1会根据实际的GC情况(主要是暂停时间)来动态的调整新生代的大小,主要是Eden Region的个数。
一个案例是,Object转xml,xml转Object,代码中每处都new XStream()去进行xml序列化与反序列化,回收速度跟不上new的速度,YoungGC次数陡增。
minor gc运行的很慢有可能是什么原因引起的?
1、新生代空间设置过大。
2、对象引用链较长,或者存活小对象的数量太多,进行可达性分析时间较长。
3、新生代survivor区设置的比较小,清理后剩余的对象不能装进去需要移动到老年代,造成移动开销。
4、内存分配担保失败,由minor gc转化为full gc
5、采用的垃圾收集器效率较低,比如新生代使用serial收集器
8、load飙升怎么处理?什么情况可能会遇到上述情况?
可参考:https://www.cnblogs.com/xrq730/p/11041741.html
对于load的理解如下:
一个单核的处理器可以形象得比喻成一条单车道,车辆依次行驶在这条单车道上,前车驶过之后后车才可以行驶。
如果前面没有车辆,那么你顺利通过;如果车辆众多,那么你需要等待前车通过之后才可以通过。
因此,需要些特定的代号表示目前的车流情况,例如:
- 等于0.00,表示目前桥面上没有任何的车流。实际上这种情况0.00和1.00之间是相同的,总而言之很通畅,过往的车辆可以丝毫不用等待的通过
- 等于1.00,表示刚好是在这座桥的承受范围内。这种情况不算糟糕,只是车流会有些堵,不过这种情况可能会造成交通越来越慢
- 大于1.00,那么说明这座桥已经超出负荷,交通严重的拥堵。那么情况有多糟糕? 例如2.00的情况说明车流已经超出了桥所能承受的一倍,那么将有多余过桥一倍的车辆正在焦急的等待
系统load是处于运行状态或者不可中断状态的进程的平均数(标红部分表示被算入load的内容)。一个处于运行状态的进程表示正在使用cpu或者等待使用cpu,一个不可中断状态的进程表示正在等待IO,例如磁盘IO。load的平均值通过3个时间间隔来展示,就是我们看到的1分钟、5分钟、15分钟,load值和cpu核数有关,单核cpu的load=1表示系统一直处在负载状态,但是4核cpu的load=1表示系统有75%的空闲。
特别注意,load指的是所有核的平均值,这和cpu的值是有区别的。
还有一个重要的点是,查了资料发现,虽然上面一直强调的是"进程",但是进程中的线程数也是会被当作不同的进程来计算的,假如一个进程产生1000个线程同时运行,那运行队列的长度就是1000,load average就是1000。
load是以线程/进程作为统计指标,无论请求数是多少,最终都需要线程去处理,而工作线程的处理性能直接决定了最终的load值
load高、cpu高的问题排查思路
首先抛出一个观点:cpu高不是问题,由cpu高引起的load高才是问题,load是判断系统能力指标的依据。
前面说了这么多,这里总结一下load高常见的、可能的一些原因:
- 死循环或者不合理的大量循环操作,如果不是循环操作,按照现代cpu的处理速度来说处理一大段代码也就一会会儿的事,基本对能力无消耗
- 频繁的YoungGC
- 频繁的FullGC
- 高磁盘IO
- 高网络IO
线上遇到问题的时候首先不要慌,因为大部分load高的问题都集中在以上几个点里面,以下分析问题的步骤或许能帮你整理思路:
- top先查看用户us与空闲us(id)的cpu占比,目的是确认load高是否高cpu起的
- 如果是高cpu引起的,那么确认一下是否gc引起的,jstat命令 + gc日志基本就能确认
- gc引起的高cpu直接dump,非gc引起的分析线程堆栈
- 如果不是高cpu引起的,查看磁盘io占比(wa:cpu等待磁盘写入完成时间,如果一台机器看到wa特别高,那么一般说明是磁盘IO出现问题,可以使用iostat等命令继续进行详细分析
),如果是,那么打线程堆栈分析是否有大量的文件io - 如果不是高cpu引起的,且不是磁盘io导致的,检查各依赖子系统的调用耗时,高耗时的网络调用很可能是罪魁祸首
最后还是不行,当束手无策时,jstack打印堆栈多分析分析吧,或许能灵光一现能找到错误原因。
9、问题排查之服务响应超时
(1)JVM频繁做垃圾回收,或STW时间过长
(2)线程池中的线程执行任务太慢,可能导致阻塞,这样其它任务就压入队列中了
抢购活动出现了大量超时报警,不过比我预料的要好一点,起码没有挂掉重启。
通过工具分析,我发现 cs(上下文切换每秒次数)指标已经接近了 60w ,平时的话最高 5w。再通过日志分析,我发现了大量带有 wait() 的 Exception,由此初步怀疑是大量线程处理不及时导致的,进一步锁定问题是连接池大小设置不合理。后来我就模拟了生产环境配置,对连接数压测进行调节,降低最大线程数,最后系统的性能就上去了。