
小技巧:group by和order by 语句可以用数字反射选择的字段
如上图:1代表total_movies,2代表rating
group by使用场景:电影被很多人打了分,我要看一下这些电影各有多少人打了分
我只想要输出“电影名+打分人数”的形式,不想重复出现电影名,所以用group by 给重复的电影名分组,按电影名来统计电影评分的总分。
所以group by一般都是配合函数来使用

SUM( )函数用于统计总数,括号内写字段名,输出所有记录的该字段值的和

MAX( ) 函数用于查找最大值,括号内写字段名,输出所有记录该字段的最大值

MIN( )函数用于查找记录中的最小值,使用和MAX( )同理

COUNT( )函数用于计算记录个数,括号内写*和字段名都可以,输出符合条件的记录个数
COUNT(*)记录空值,但COUNT(字段名)不会记录空值,对应不同的应用场景

GROUP BY 语句用于按相同的值进行分组合并,结果和我们在select语句中的distinct去重类似
但是GROUP BY并不会过滤掉记录,而是合并记录,此时场景一般出现在统计、找最大最小值等利用到sql函数的地方
上图语句做的是从movies(电影)表中把所有记录的 `rating` 字段值和相同 `rating`字段的个数(rating代表评分),即看一下各个电影被多少个人评了分
如果没有GROUP BY,这个count(*)的值永远不会变,一直会是总记录个数,不会按rating(评分)来分组

AVG( )函数应用于计算符合条件的记录中,某字段的平均值,括号内写一个字段名
上图语句做的是选出员工(employee)中从业经验(experience)大于5年的员工,得到他们的平均薪资(salary)
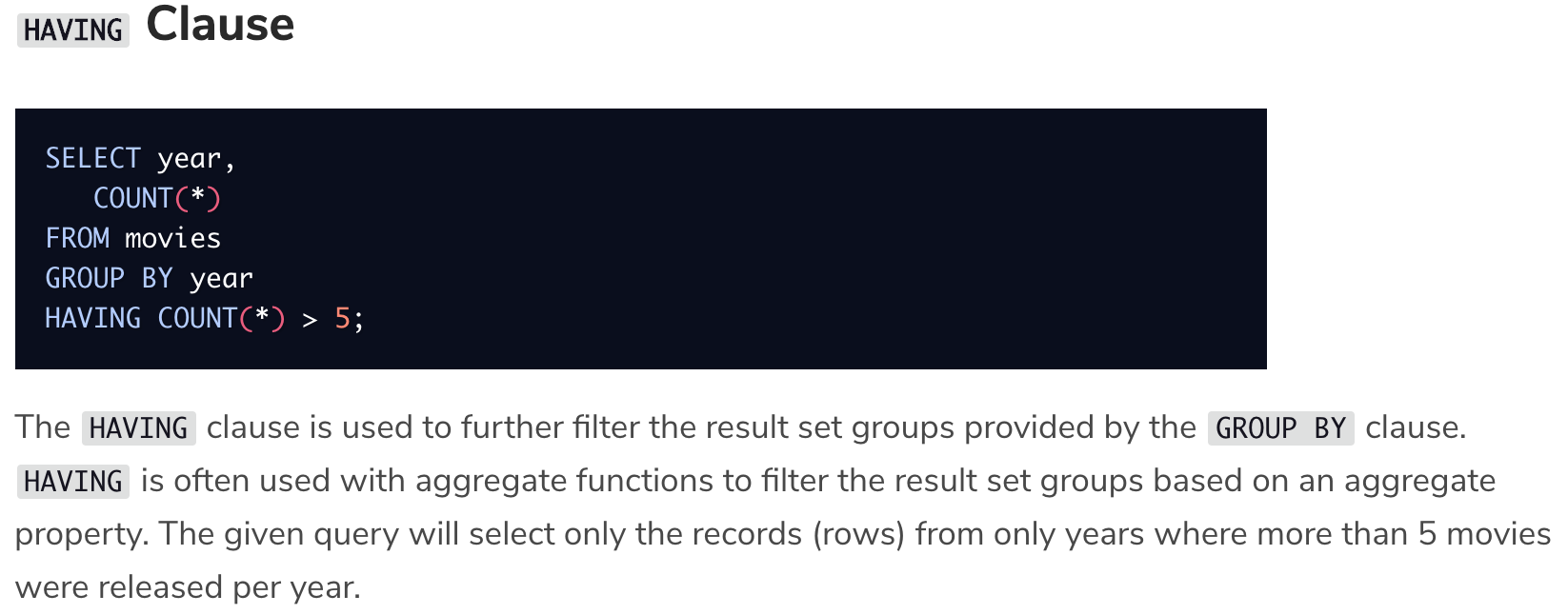
HAVING语句是和GROUP BY一起用的语句,在没有GROUP BY分组的时候,我们利用WHERE加入更精细的查找条件
但是在GROUP BY按字段分组后,我们用HAVING对分组后的结果进行额外的条件约束
上图语句做的是按相同年份分组,输出年份+同年上映的电影个数,并且只选择该年上映电影数大于5的年份
HAVING对于GROUP BY,正如WHERE对于SELECT的关系,HAVING是修饰GROUP BY分组结果的语句

总结:sql函数都执行了一步计算,对于"a set of values"一堆记录进行计算,返回的是一个值