一、概述
1.软件版本介绍
- 主机服务器:处理器:Xeon E5620 主频:2.4GHz,内存:64G(48G可用),操作系统:Windows Server 2008 R2 SP1
- 虚拟机:VMware Workstation 10
- linux版本:CentOS 7
- JDK:jdk-8u131-linux-x64
- hadoop:2.8.0
2.hadoop采用完全分布式方式部署,具体见下表
| 序号 | IP地址 | 机器名 | 节点类型 |
| 1 | 192.168.1.52 | master1 | namenode |
| 2 | 192.168.1.53 | slave01 | datanode |
| 3 | 192.168.1.54 | slave02 | datanode |
所有节点均是CentOS系统,防火墙均禁用,所有节点上均创建了一个Hadoop用户,用户主目录是/home/Hadoop。所有节点上均创建了一个目录/usr/hadoop,并且拥有者是hadoop用户。因为该目录用于安装hadoop,用户对其必须有rwx权限。(一般做法是root用户下在/usr下创建hadoop目录,并修改该目录拥有者为hadoop(chown –R Hadoop: /usr/hadoop),否则通过SSH往其他机器分发Hadoop文件会出现权限不足的提示
二、系统安装
1.安装系统,参见http://www.cnblogs.com/kxxx/p/6279298.html
2.安装完系统之后配置IP
(1)配置本机的IP,请参见 http://www.cnblogs.com/kxxx/p/6279319.html
(2)配置/etc/hosts文件
配置如下图:

此处需要配置自己和另外2台的IP地址和机器名。。注:这里有一个比较坑的地方,在后面hadoop安装好之后出现了问题。我在第一句
127.0.0.1 master1 localhost localhost.localdomain localhost4 localhost4.localdomain4 中多了红色字体的数据,引起后面datanode的2台一直连不起namenode,后续介绍。
3.禁用防火墙
systemctl stop firewalld.service 关闭防火墙
systemctl disable firewalld.service 禁止防火墙在开机时启动
4.设置selinux为disabled
修改/etc/selinux/config 文件
将SELINUX=enforcing改为SELINUX=disabled
重启机器即可。 注:一定要重启
三、安装JAVA
(1)卸载系统自带的openjdk
由于我按照的CentOS 7 默认安装了openjdk,故这里需要先卸载,具体操作步骤参见http://www.cnblogs.com/kxxx/p/7055273.html
(2)安装JDK
请参见上面的文章一起http://www.cnblogs.com/kxxx/p/7055273.html
四、配置SSH免密码登录
我的配置过程请参见:http://www.cnblogs.com/kxxx/p/7050159.html
由于我刚刚接触到linux系统,对SSH免密登录不熟悉,中间走了很多弯路,我开始一直以为需要将公钥copy到其它机器是其它机器可以免密登录到本机器,结果我理解正好相反。比如在master1上生成key,并且将公钥拷贝到slave01上并配置slave01上的authorized_keys。我的理解是slave01可以免密登录到master1,结果和我理解的相反,正确的应该是master1免密登录到slave01上。
五、安装hadoop
1.创建hadoop用户和hadoop-user组
描述:hadoop启动全部使用hadoop用户,故先创建了hadoop用户,并且hadoop用户属于hadoop-user组
步骤:使用root用户登录,分别执行如下命令
创建用户组:groupadd hadoop-user
创建用户并分配组:useradd -g hadoop-user hadoop
修改用户密码:passwd hadoop
2.使用root用户登录,在/usr目录下创建hadoop目录,并将hadoop的拥有者变为hadoop用户
cd /usr
mkdir hadoop
chown -R hadoop:hadoop-user hadoop
3.使用SecureCRT将下载的hadoop-2.8.0.tar.gz包发送到master1中的/usr/hadoop目录下,并解压。解压后删除hadoop-2.8.0.tar.gz包。解压后在hadoop文件下将出现hadoop-2.8.0这个文件夹。
解压命令:cd /usr/hadoop
tar –xzvf hadoop-2.8.0.tar.gz
4.处理配置文件,我参照了Apache的官方文档:http://hadoop.apache.org/docs/r2.8.0/hadoop-project-dist/hadoop-common/ClusterSetup.html
所有的配置文件都在/usr/hadoop/hadoop-2.8.0/etc/hadoop目录下。在配置时使用hadoop用户登录
4.1 配置hadoop-env.sh
需要配置JAVA_HOME,文件中开始时值为export JAVA_HOME=${JAVA_HOME},需要改为:
export JAVA_HOME=/usr/java/jdk1.8.0_131
4.2 配置core-site.xml,我配置如下:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master1:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/hadoop/tmp</value> </property> </configuration>
4.3 配置hdfs-site.xml,这个配置文件分为namenode和datanode进行配置,namenode的配置如下(即master1上):
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///usr/hadoop/dfs/name</value> </property> <property> <name>dfs.blocksize</name> <value>268435456</value> </property> <property> <name>dfs.namenode.handler.count</name> <value>100</value> </property> </configuration>
datanode的配置如下(即slave01,slave02上):
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///usr/hadoop/dfs/data</value> </property> </configuration>
4.4 配置yarn-site.xml,配置如下:
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.hostname</name> <value>master1</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master1:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master1:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master1:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master1:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master1:8088</value> </property> </configuration>
4.5 配置mapred-site.xml,配置如下:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master1:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master1:19888</value> </property> </configuration>
这个配置文件最开始没有,需要从mapred-site.xml.template这个文件复制过来
4.6 配置slaves,配置如下:

这个文件原值是localhost,需要改为如上图的配置.
4.7 配置yarn-env.sh,

5.配置完成后创建文件夹,在/usr/hadoop/目录下创建 tmp、dfs、dfs/name、dfs/data
6.启动和验证
6.1在启动前需要进行format,在master1上执行
[hadoop@master1 ~]$ cd /usr/hadoop/hadoop-2.8.0
[hadoop@master1 hadoop-2.8.0]$ bin/hdfs namenode -format
6.2启动
先执行:sbin/start-dfs.sh
[hadoop@master1 hadoop-2.8.0]$ sbin/start-dfs.sh
再执行:sbin/start-yarn.sh
[hadoop@master1 hadoop-2.8.0]$ sbin/start-yarn.sh
至此启动完毕,
在master1上执行jps,如下图:

在slave01或slave02上执行 jps

当出现上图时表示服务启动成功.
可以在master1上通过 bin/hdfs dfsadmin -report 查看状态:
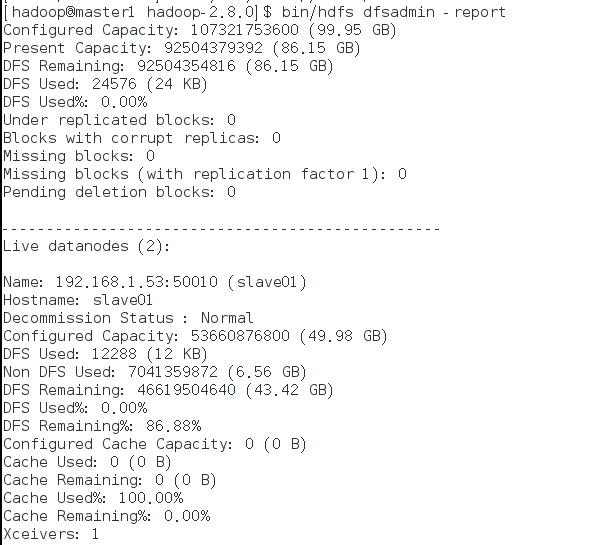
表示namenode和datanode全部正常工作
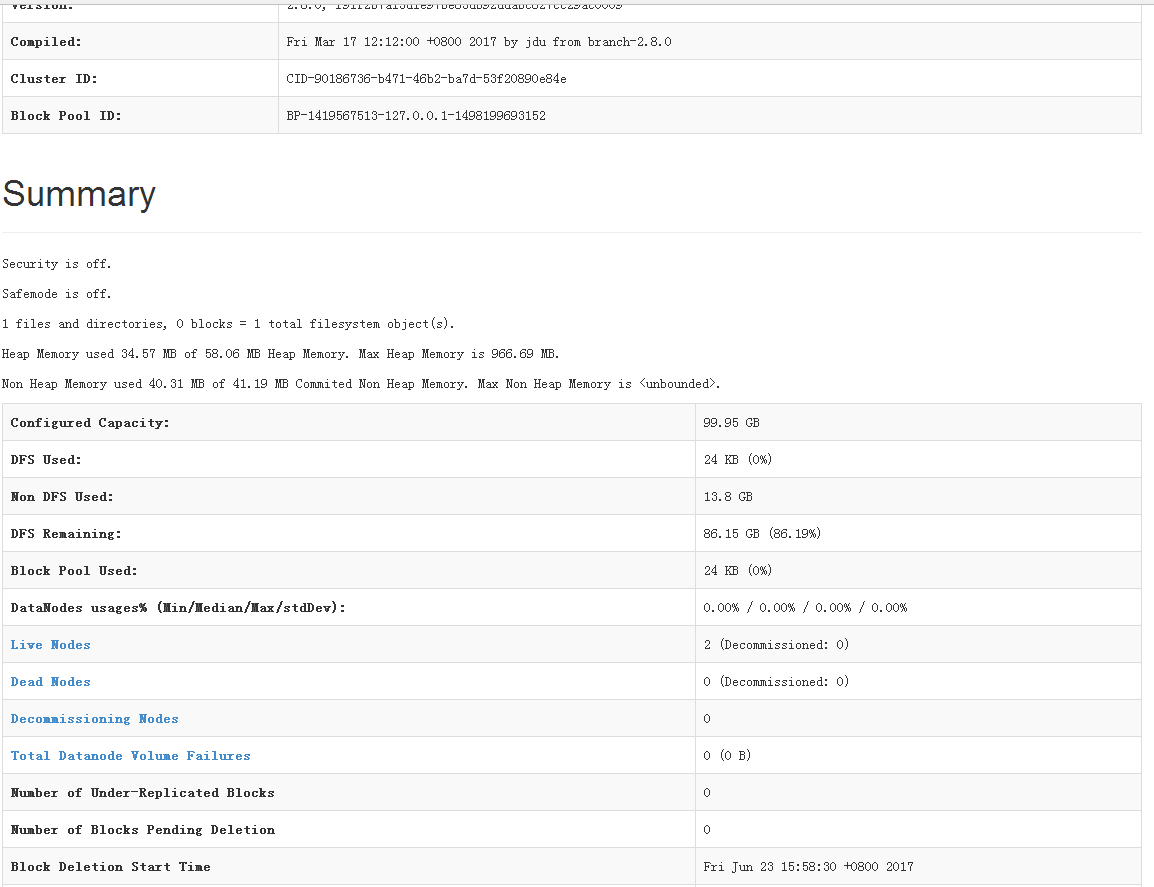
也可以通过master1上提供的服务:http://192.168.1.52:50070查看

六、安装后的碰到的错误
在安装后datanode节点启动起来了,且配置文件全部重新核对后,datanode总是报错连接不到master1,试了很多方法都不行,最后看到这篇文章:http://www.myexception.cn/cloud/1648939.html,问题解决。
这篇文章主要是说master1上的9000端口只启动了127.0.0.1这个IP,未启动到192.168.1.52这个IP,主要是由/etc/hosts这个文件引起的。我的转发文章:http://www.cnblogs.com/kxxx/p/7070705.html