先上结论,根据官网的说法是 B 树

然而笔者看到一篇,云栖社区-MongoDB 为什么使用B-树而不是B+树?,里面有人如下回答
实际是B+树,这个在2018年元旦北京的MongoDB专场,我问了WiredTiger引擎的作者,他也确认了是B plus Tree。虽然官方文档写了B树。
现在有些觉得迷惑了,要是有人知道,请留言告诉我好么。
由于第二个观点,相关的佐证很难找,姑且还是采用官网的的说法是用 B 树吧。
那么为什么是 B 树?
在上一篇 MySQL 的索引实现 里笔者分析过
B+ 是在 B 树上改进,它的数据都在叶子节点,同时叶子节点之间还加了指针形成链表。范围选择只需要找到首尾,通过链表就能把所有数据取出来了。
而 B 树有啥好处呢?因此查询单条数据的时候,B树的查询效率不固定,最好的情况是 O(1),因为它不需要再遍历去找到叶子节点。所以可以认为在做单一数据查询的时候,使用 B 树平均性能更好。但是,由于 B 树中各节点之间没有指针相邻,因此 B 树做一些数据遍历操作不那么适合。
换言之 MySQL 之所以选择 B+,那是因为出于范围选择考虑的。那么 MongoDB 选择 B 树,可能是因为单一数据查询多,范围查询少。
那为什么 Mongodb 范围查询少呢?是因为 Mysql 是关系型数据库,而 Mongodb 是非关系型数据。往下看举例
例子
下文图片和例子都出自博客园-孤独烟 为什么Mongodb索引用B树,而Mysql用B+树?
设计学生和班级一对多关系的表。关系型数据库逻辑如下
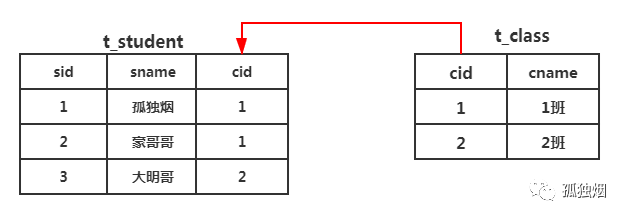
此时要查 cname 为 1 班的班级,不论是 join,还是先查出所有 cid,后再 student 表里匹配这 cid 相同的记录,都避免不了从一个表中取一个数据,去另一个表中逐行匹配,如果索引结构是 B+ 树,叶子节点上是有指针的,能够极大的提高这种一行一行的匹配速度。
那非关系型怎么设计?
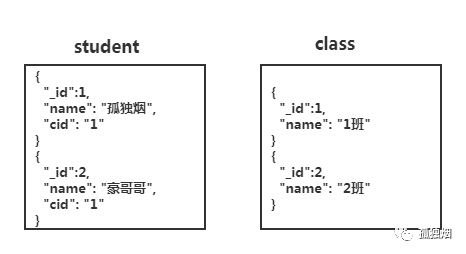
然后再执行两条查询去计算结果,虽然是可以这么设计,但是 MongoDB 并不推荐。发挥非关系型数据库的长处应当这么设计:
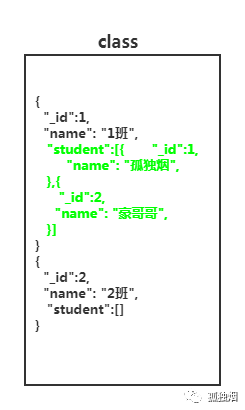
假设name这列,我们建了索引!寻执行一次语句,这样就能查询出自己想要的结果。
db.class.find( { name: '1班' } )
而这,就是一种单一数据查询!毕竟你不需要去逐行匹配,不涉及遍历操作,幸运的情况下,有可能一次IO就能够得到你想要的结果。
因此,由于关系型数据库和非关系型数据的设计方式上的不同。导致在关系型数据中,遍历操作比较常见,因此采用B+树作为索引,比较合适。而在非关系型数据库中,单一查询比较常见,因此采用B树作为索引,比较合适。