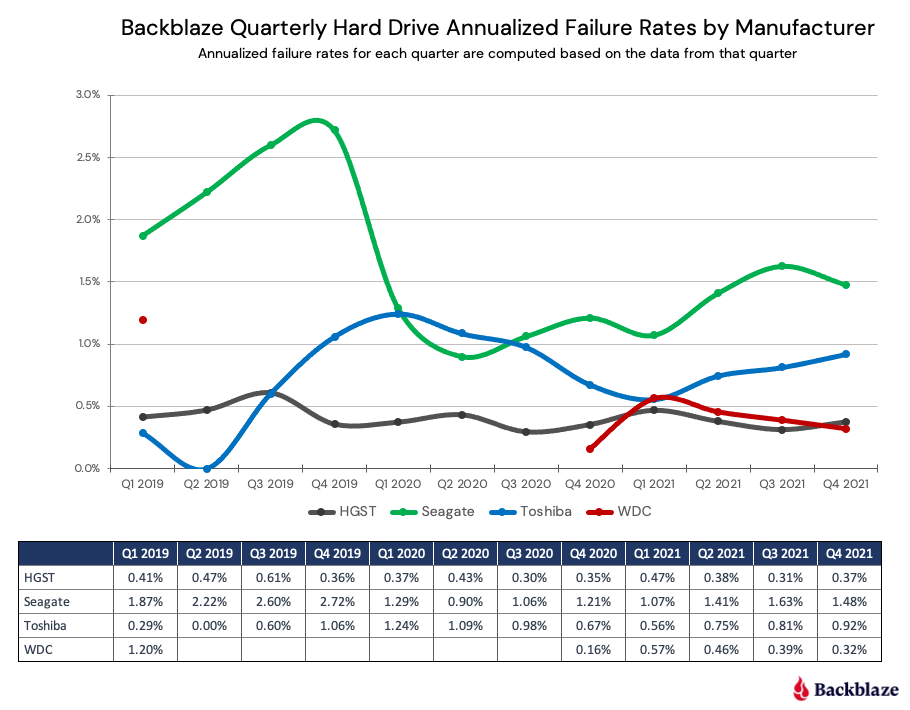
根据云存储服务商Backblaze发布的2021年硬盘“质量报告”,现有存储硬件设备的可靠性无法完全保证,我们需要在软件层面通过一些机制来实现可靠存储。一个分布式软件的常用设计原则就是面向失效的设计。
作为当前广泛流行的分布式文件系统,HDFS需要解决的一个重要问题就是数据的可靠性问题。3.0以前版本的Hadoop在HDFS上只能采用多副本冗余的方式做数据备份,以实现数据可靠性目标(比如,三副本11个9,双副本8个9)。多副本冗余的方式虽然简单可靠,却浪费了成倍的存储资源,随着数据量的增长,将带来大量额外成本的增加。为了解决冗余数据的成本问题,在Hadoop3.0版本上,HDFS引入了EC技术(Erasure Code 纠删码)。
本文分享EC技术原理及个推的EC实践,带大家一起玩转Hadoop3.0!

EC原理深度解读
EC技术深度应用于RAID和通信领域,通过对数据编解码以实现在部分数据丢失时仍能够将其恢复。
我们可以这样理解EC的目标和作用:对n个同样大小的数据块, 额外增加m个校验块, 使得这n+m个数据中任意丢失m个数据块或校验块时都能恢复原本的数据。
以HDFS的RS-10-4-1024k策略为例,可以实现在1.4倍的数据冗余的情况下,达到近似于5副本的数据可靠性,也就是说以更小的数据冗余度获得更高的数据可靠性。
1、EC算法
常见的EC算法有XOR、RS,下面一一做简要介绍:
//简单EC算法:XOR
XOR是一种基于异或运算的算法,通过对两个数据块进行按位异或,就可以得到一个新的数据块,当这三个数据块中有任意一个数据块丢失时,就可以通过另外两个数据块的“异或”恢复丢失的数据块。
HDFS通过XOR-2-1-1024k的EC策略实现了该算法,这种方式虽然降低了冗余度,但是只能容忍三个数据块中一个丢失,在很多情况下其可靠性依然达不到要求。
//改进的EC算法:RS
另一种降低冗余度的编码方式为Reed-Solomon(RS),它有两个参数,记为RS(n,m)。其中,n表示数据块,m表示校验块,需要注意的是,RS算法下,有多少个校验块,就表示最多可容忍多少个数据块(包括数据块和校验块)丢失。
RS 算法使用生成矩阵(GT,Generator Matrix)与n个数据单元相乘,以获得具有n个数据单元(data cells)和m个奇偶校验单元(parity cells)的矩阵。如果存储失败,那么只要n+m个cells中的n个可用,就可以通过生成器矩阵来恢复存储。
RS算法克服了XOR算法的限制,使用线性代数运算生成多个parity cells,以便能够容忍多个失败。
下图形象地描述了RS算法的编码与解码过程:
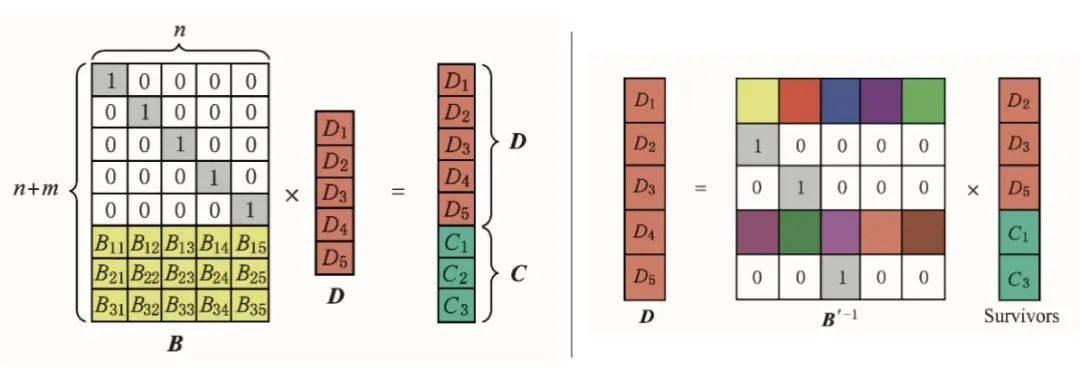
编码过程(图左):
- 把m个有效数据组成一个向量D。
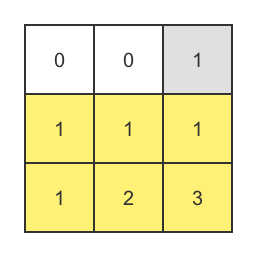
- 生成一个变换矩阵B:由一个n阶的单位矩阵和一个n * M的范德蒙特矩阵(Vandemode)组成。
- 两矩阵B和D,相乘,得到一个新的具备纠错能力的矩阵。
解码过程(图右):
- 取范德蒙矩阵B中没有丢失的行,构成矩阵B`。
- 取编码过程最后计算的矩阵中没有丢失的行,构成矩阵Survivors。
- 用B`的逆,乘以Survivors矩阵,即可得到原始的有效数据。
为了更通俗地说明编解码过程,我们以RS-3-2-1024k策略为例,回顾使用EC算法进行编解码的过程。
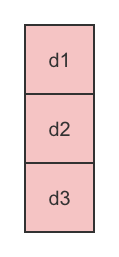
假设有三块数据:d1,d2,d3,我们需要额外存储两块数据,使得这五块数据中,任意丢失两块数据,都能将它们完整找回。
首先按编码过程构建纠错矩阵:
1、得到向量D
2、生成一个变换矩阵B
3、得到纠错矩阵D*B
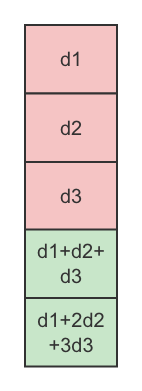
假设d1,d2数据丢失,我们通过解码做数据恢复:
1、取B中没有丢失的行,构成矩阵B`
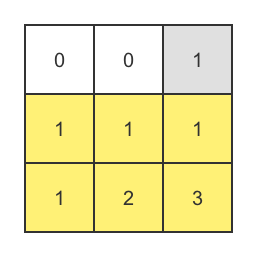
2、取纠错矩阵中没有丢失的行,构成矩阵Survivors
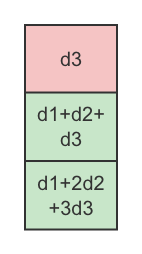
3、计算B`的逆为:
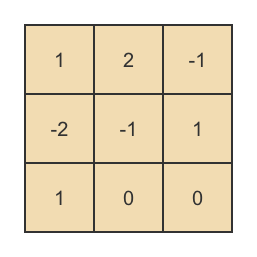
4、B`的逆,乘以Survivors矩阵,即可得到原始的有效数据:
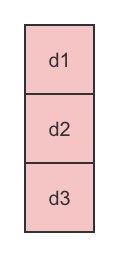
至此,我们完成了在原本3个数据块外再额外存储2个数据块,使得这5个数据块中任意丢失两个都能将其找回的目标。
与三副本的方式对比,在可靠性方面,三副本方式可以容忍存储该文件(数据d1,d2,d3)的机器中任意两台宕机或坏盘,因为总还有一个副本可用,并通过复制到其他节点恢复到三副本的水平。同样,在RS-3-2策略下,我们也可以容忍5个数据块所在的任意2台机器宕机或坏盘,因为总可以通过另外的3个数据块来恢复丢失的2个数据块。
由此可见,三副本方式和RS-3-2策略,在可靠性方面基本相当。
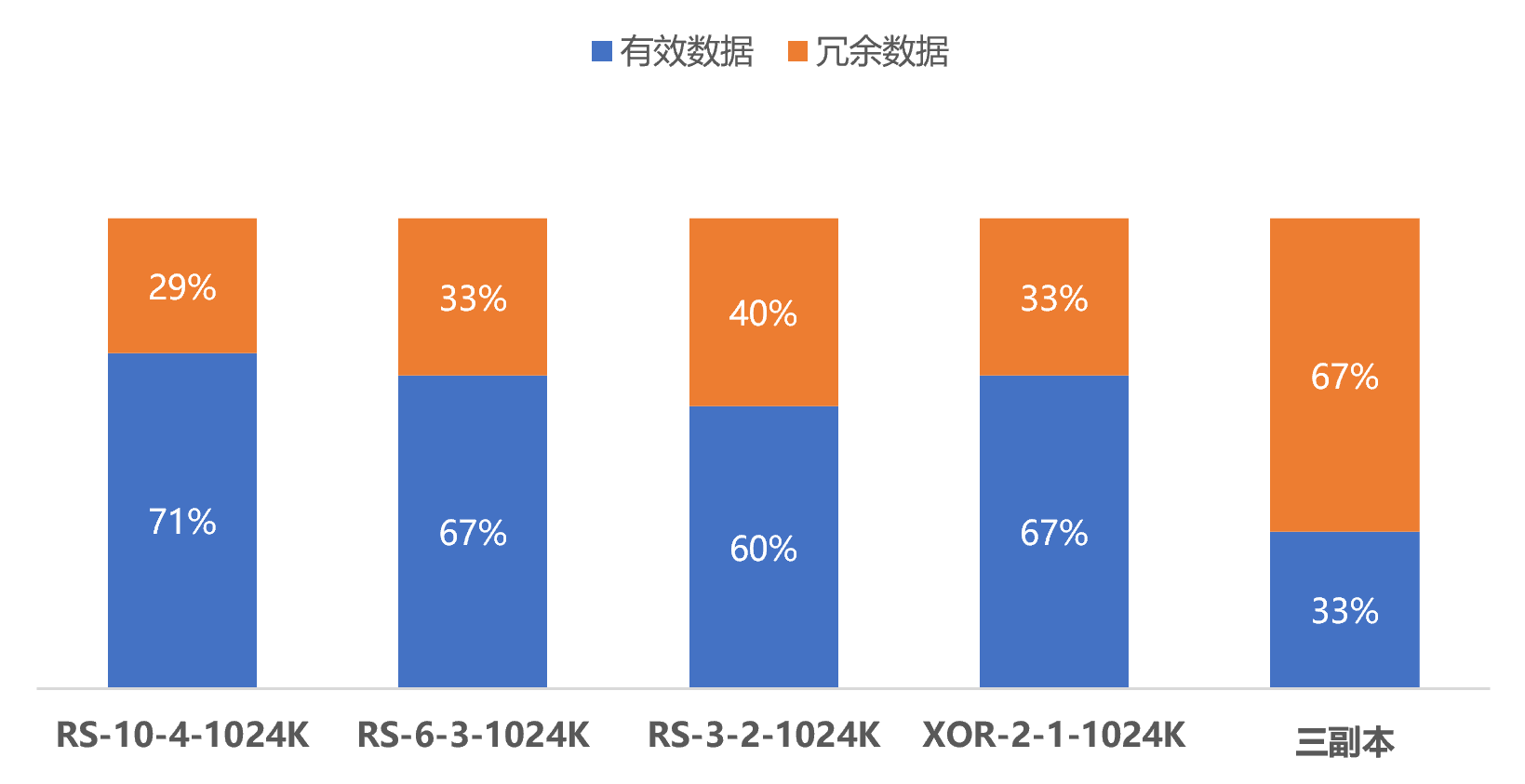
在冗余度(冗余度=实际存储空间/有效存储空间)方面,三副本方式下,每1个数据块都需要额外的2个数据块做副本,冗余度为3/1=3,而在RS-3-2的策略下,每3个数据块只需要额外的2个数据块就能够实现可靠性目标,冗余度为5/3=1.67。
最终,我们通过RS-3-2的方式能够在1.67倍冗余的情况下,实现近似三副本的可靠性。
下图为Hadoop上,不同策略下的有效数据与冗余数据占比示意图。可以看到,三副本方式的存储成本是最高的:
2. 条带布局
副本策略以块(Block)为单位,将数据连续写入Block中,直至达到该Block上限(默认128M),然后再去申请下一个Block。以最常见的三副本方式为例,每个Block会有3个相同数据的副本存储于3个DataNode(DN)上。
HDFS EC策略采用的是条带式存储布局(Striping Block Layout)。条带式存储以块组(BlockGroup)为单位,横向式地将数据保存在各个Block上,同一个Block上不同分段的数据是不连续的,写完一个块组再申请下一个块组。
下图为连续布局和RS(3,2)策略下一个BlockGroup布局对比:
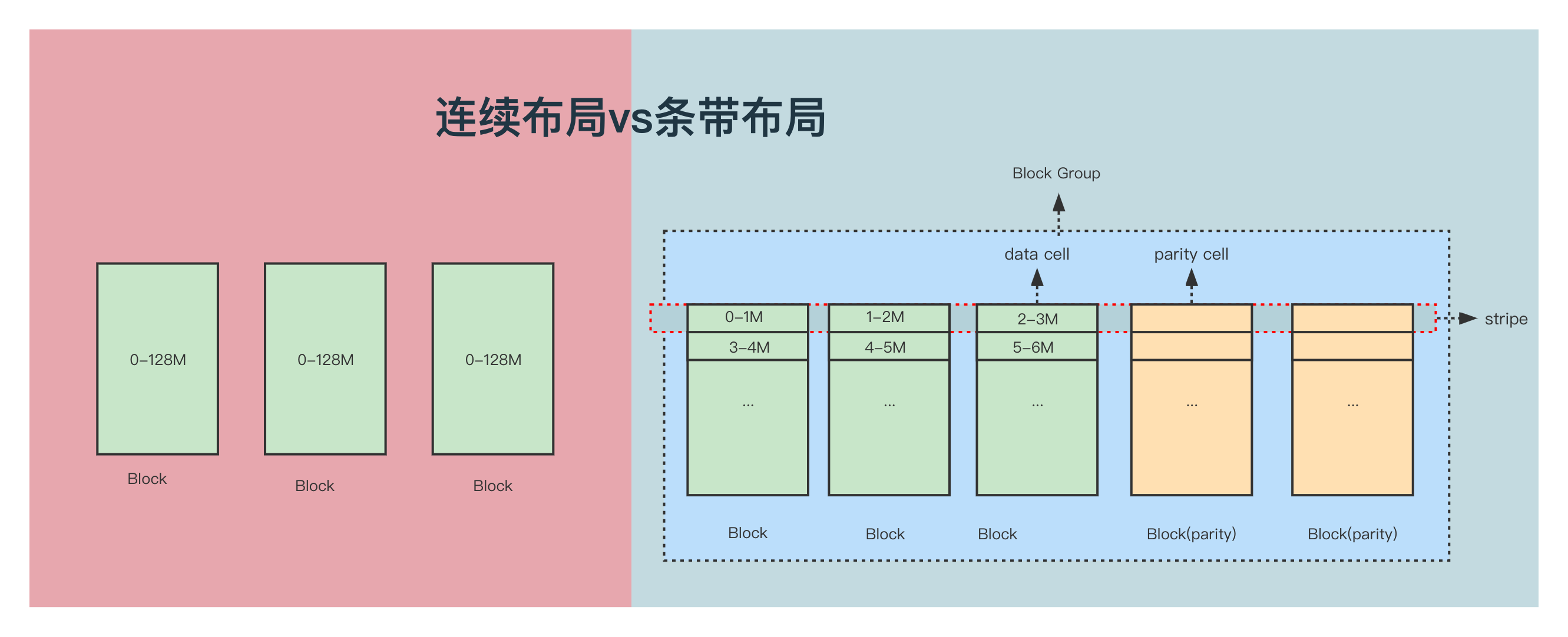
相比于连续布局,条带布局有以下优势:
- 支持直接写入EC数据,不需要做离线转化
- 对小文件更友好
- I/O并行能力提高
个推在Hadoop2.0上落地EC
个推在很早的时候就对整个集群做了规划,将整个Hadoop集群分为对计算需求比较大的热集群和对存储需求比较大的冷集群。在Hadoop3.x发布以后,我们将冷集群升级到Hadoop3.x版本,进行了包括EC编码在内的新特性试用。考虑到计算引擎的兼容性、稳定性要求,同时为了减少迁移成本,我们仍将热集群保持在了Hadoop2.7版本。
计算引擎访问
由于主要承接计算任务的热集群是Hadoop2.x的环境,而内部的计算引擎都不支持Hadoop3.x,所以为了将EC功能在生产环境落地,我们首先要解决在Hadoop2.x上对Hadoop3.x上EC数据进行访问的能力。为此,我们对Hadoop2.7的hadoop-hdfs做了定制化开发,移植了Hadoop3.x上的EC功能,核心的变动包括:
- EC编解码和条带相关功能引入
- PB协议的适配
- 客户端读取流程的改造
资源本地化
在部署改造代码包的过程中,我们使用Hadoop的“资源本地化”机制,简化了灰度和上线流程。
所谓“资源本地化”,指的是NodeManager在启动container以前需要从HDFS上下载该container执行所依赖资源的过程,这些资源包括jar、依赖的jar或者其它文件。借助资源本地化的特性,我们就可以将jar包,定制分发到相应计算任务的container中,以控制application级别任务的Container的jar包环境,使后续的测试、灰度验证和上线非常方便。
SQL访问
个推目前有大量的任务是通过SQL方式提交的,其中,大部分的SQL任务在提交到Yarn上之后,会转化为相应计算引擎的计算任务。针对该部分SQL任务,我们可以直接使用第一种解决方案进行访问。
但是,仍然存在一部分的任务并不通过Yarn提交,而是直接与HDFS做交互,比如一些小数据集计算任务或直接通过limit查看几条示例的SQL任务(例如select * from table_name limit 3)。这就需要该部分任务所在的节点,有访问Hadoop3.x上EC数据的能力。
以Hive为例,下图为个推环境上Hive访问HDFS数据的几种方式,这里的HiveCli、Hiveserver2都要做相应的适配:

3、损坏校验
在社区提交的EC相关的bug中,我们发现有一些bug会导致编码的数据损坏,例如:HDFS-14768、HDFS-15186、HDFS-15240。为了确保转化后的数据是正确的,我们对编码后的数据做了块级别的额外校验。
在设计校验程序时,我们不仅要考虑校验程序的便利性,使其能够对新EC的数据做校验,还要对之前已经EC过的数据做一遍校验。因此,我们主要的思路是利用全部的校验块和部分数据块对编码后的数据做解码,来对比解码后的数据块和原数据块是否一致。
我们以RS-3-2-1024k为例,回顾下校验过程:
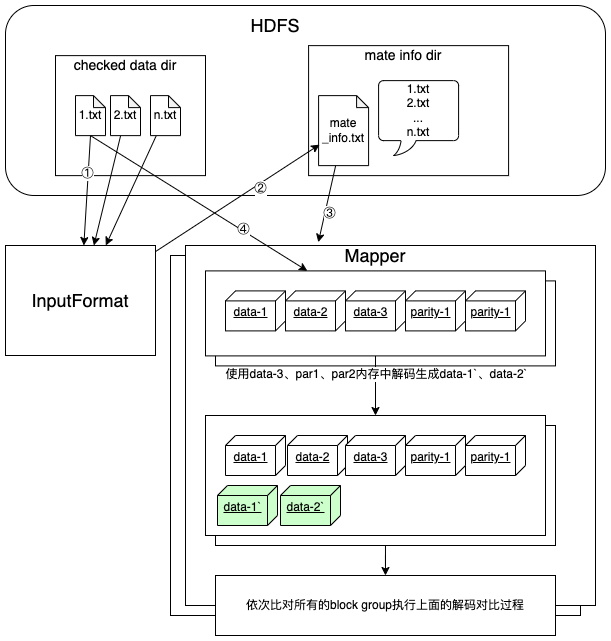
基于额外的校验工具,我们抽取了单副本1PB的EC数据做了验证,验证结果显示,故障的文件数和大小占比大约都在百万分之一以下,可靠性达到目标要求。
展望
目前,我们还需要专门统计和筛选出热度比较低的数据并过滤掉小文件,用于后续的EC编码处理。后续我们将探索设计一套系统,使其能自动感知到数据的热度下降,并完成数据从副本策略到EC策略的转化。此外,在intel ISA-L加速库等方面,我们还将持续展开探索,以提升整个EC编解码的运算效率。
关注个推技术实践公众号,解锁“大数据降本提效”更多干货内容。
彩蛋
“大数据降本提效”系列专栏由每日互动大数据平台架构团队深度参与打造。
每日互动大数据平台架构团队是负责每日互动大数据平台研发的核心团队,基于大数据生态圈开源组件定制优化,助力全公司各项业务的降本提效,欢迎分布式存储、分布式计算、分布式数据库等大数据平台架构领域相关的专家加入和交流。
简历投递:hrzp@getui.com;
技术交流:通过个推技术实践公众号后台,或发送邮件至tech@getui.com和我们联系。