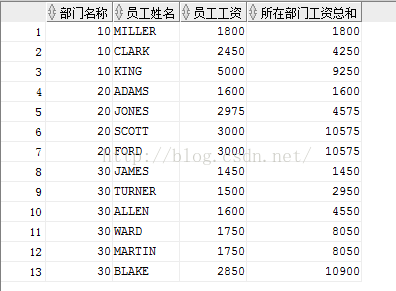
SELECT deptno 部门名称 ,ename 员工姓名, sal 员工工资, SUM(sal) OVER(PARTITION BY deptno ORDER BY sal) 所在部门工资总和 FROM emp;
场景:查询出每个部门工资最低的员工编号【每个部门可能有两个最低的工资员工】
create table TSALER ( userid NUMBER(10), salary NUMBER(10), deptid NUMBER(10) ) -- Add comments to the columns comment on column TSALER.userid is '员工ID'; comment on column TSALER.salary is '工资'; comment on column TSALER.deptid is '部门ID'; insert into TSALER (工号, 工资, 部门编号) values (1, 200, 1); insert into TSALER (工号, 工资, 部门编号) values (2, 2000, 1); insert into TSALER (工号, 工资, 部门编号) values (3, 200, 1); insert into TSALER (工号, 工资, 部门编号) values (4, 1000, 2); insert into TSALER (工号, 工资, 部门编号) values (5, 1000, 2); insert into TSALER (工号, 工资, 部门编号) values (6, 3000, 2);
方法一:
select tsaler.* from tsaler inner join(select min(salary) as salary,deptid from tsaler group by deptid) c on tsaler.salary=c.salary and tsaler.deptid=c.deptid
方法二:
select * from tsaler inner join(select min(salary) as salary,deptid from tsaler group by deptid) c using(salary,deptid)
方法三:
--row_number() 顺序排序 select row_number() over(partition by deptid order by salary) my_rank ,deptid,USERID,salary from tsaler; --rank() (跳跃排序,如果有两个第一级别时,接下来是第三级别) select rank() over(partition by deptid order by salary) my_rank,deptid,USERID,salary from tsaler; --dense_rank()(连续排序,如果有两个第一级别时,接下来是第二级) select dense_rank() over(partition by deptid order by salary) my_rank,deptid,USERID,salary from tsaler; -------方案3解决方案 select * from (select rank() over(partition by deptid order by salary) my_rank,deptid,USERID,salary from tsaler) where my_rank=1; select * from (select dense_rank() over(partition by deptid order by salary) my_rank,deptid,USERID,salary from tsaler) where my_rank=1;