Kafka是什么
在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算。
1)Apache Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。
2)Kafka最初是由LinkedIn公司开发,并于 2011年初开源。2012年10月从Apache Incubator毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
3)Kafka是一个分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。
4)无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
Kafk内部实现原理

(1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息推送到客户端。这个模型的特点是发送到队列的消息被一个且只有一个接收者接收处理,即使有多个消息监听者也是如此。
(2)发布/订阅模式(一对多,数据生产后,推送给所有订阅者)
发布订阅模型则是一个基于推送的消息传送模型。发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即使当前订阅者不可用,处于离线状态。
Kafka架构
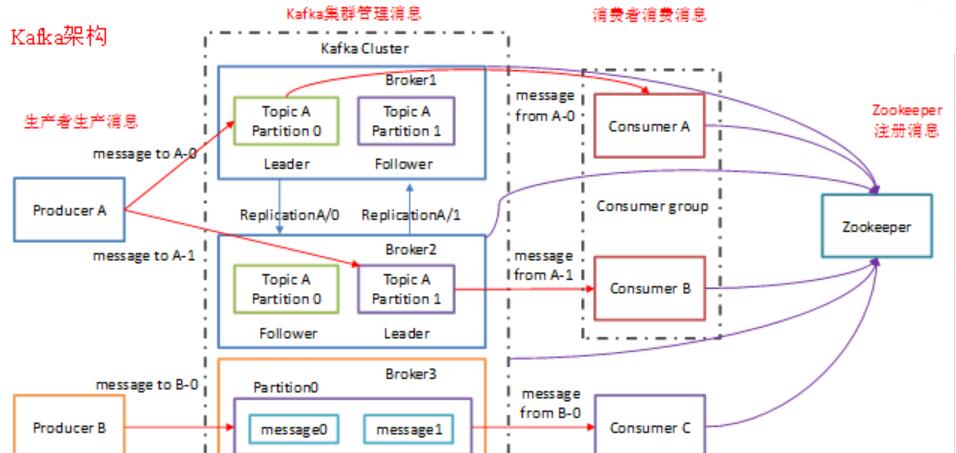
1)Producer :消息生产者,就是向kafka broker发消息的客户端。
2)Consumer :消息消费者,向kafka broker取消息的客户端
3)Topic :可以理解为一个队列。
4) Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制-给consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
5)Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
6)Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
7)Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka
Kafka分布式模型
Kafka每个主题的多个分区日志分布式地存储在Kafka集群上,同时为了故障容错,每个分区都会以副本的方式复制到多个消息代理节点上。其中一个节点会作为主副本(Leader),其他节点作为备份副本(Follower,也叫作从副本)。主副本会负责所有的客户端读写操作,备份副本仅仅从主副本同步数据。当主副本出现故障时,备份副本中的一个副本会被选择为新的主副本。因为每个分区的副本中只有主副本接受读写,所以每个服务器端都会作为某些分区的主副本,以及另外一些分区的备份副本,这样Kafka集群的所有服务端整体上对客户端是负载均衡的。
Kafka的生产者和消费者相对于服务器端而言都是客户端。
Kafka生产者客户端发布消息到服务端的指定主题,会指定消息所属的分区。生产者发布消息时根据消息是否有键,采用不同的分区策略。消息没有键时,通过轮询方式进行客户端负载均衡;消息有键时,根据分区语义(例如hash)确保相同键的消息总是发送到同一分区。
Kafka的消费者通过订阅主题来消费消息,并且每个消费者都会设置一个消费组名称。因为生产者发布到主题的每一条消息都只会发送给消费者组的一个消费者。所以,如果要实现传统消息系统的“队列”模型,可以让每个消费者都拥有相同的消费组名称,这样消息就会负责均衡到所有的消费者;如果要实现“发布-订阅”模型,则每个消费者的消费者组名称都不相同,这样每条消息就会广播给所有的消费者。
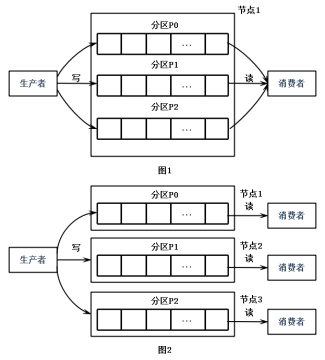
分区是消费者现场模型的最小并行单位。如下图(图1)所示,生产者发布消息到一台服务器的3个分区时,只有一个消费者消费所有的3个分区。在下图(图2)中,3个分区分布在3台服务器上,同时有3个消费者分别消费不同的分区。假设每个服务器的吞吐量时300MB,在下图(图1)中分摊到每个分区只有100MB,而在下图(图2)中,集群整体的吞吐量有900MB。可以看到,增加服务器节点会提升集群的性能,增加消费者数量会提升处理性能。
同一个消费组下多个消费者互相协调消费工作,Kafka会将所有的分区平均地分配给所有的消费者实例,这样每个消费者都可以分配到数量均等的分区。Kafka的消费组管理协议会动态地维护消费组的成员列表,当一个新消费者加入消费者组,或者有消费者离开消费组,都会触发再平衡操作。
Kafka的消费者消费消息时,只保证在一个分区内的消息的完全有序性,并不保证同一个主题汇中多个分区的消息顺序。而且,消费者读取一个分区消息的顺序和生产者写入到这个分区的顺序是一致的。比如,生产者写入“hello”和“Kafka”两条消息到分区P1,则消费者读取到的顺序也一定是“hello”和“Kafka”。如果业务上需要保证所有消息完全一致,只能通过设置一个分区完成,但这种做法的缺点是最多只能有一个消费者进行消费。一般来说,只需要保证每个分区的有序性,再对消息假设键来保证相同键的所有消息落入同一分区,就可以满足绝大多数的应用。