Xx_Menu
- Burp Target
- Target site map
- Scope - Burp Spider
- Control:status and Scope(Target and Custom)
- Options:Crawler Setting,Passive Spidering,Form Submission,Application Login,Spider Engine,Request Headers.
Ax_Burp Target
z.site map
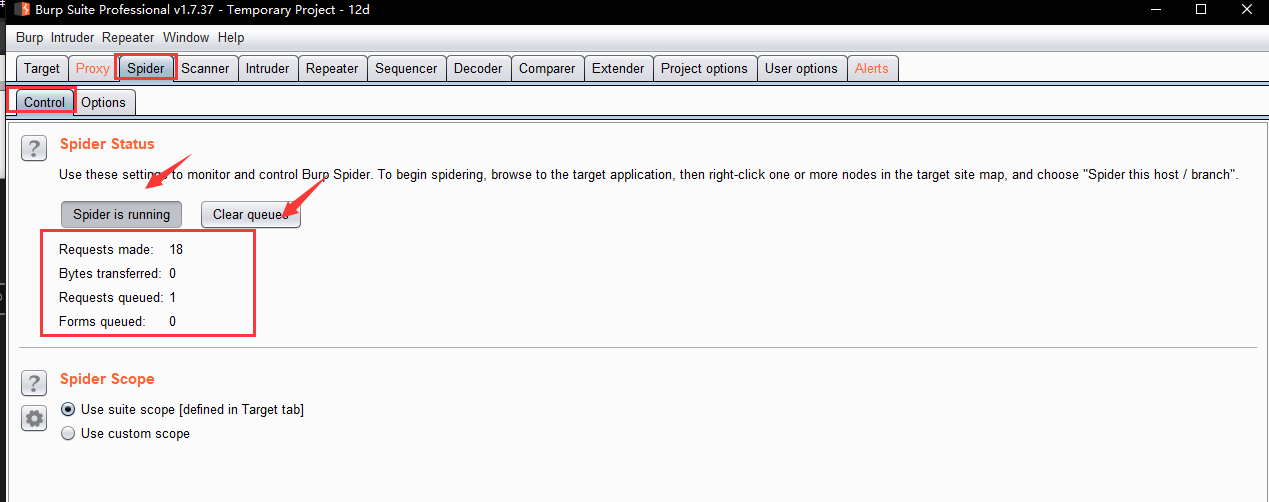
Use these settings to monitor and control Burp Spider:
Spider is paused / running - This toggle button is used to start and stop the Spider. While the Spider is stopped it will not make any requests of its own, although it will continue to process responses generated via Burp Proxy (if passive spidering is enabled), and any newly-discovered items that are within the spidering scope will be queued to be requested if the Spider is restarted.
Clear queues - If you want to reprioritize your work, you can completely clear the currently queued items, so that other items can be added to the queue. Note that the cleared items may be re-queued if they remain in-scope and the Spider's parser encounters new links to the items.
The display also shows some metrics about the Spider's progress, enabling you to see the size of the in-scope content and the work remaining to fully spider it.
All content discovered by the Spider is added to the main suite site map.
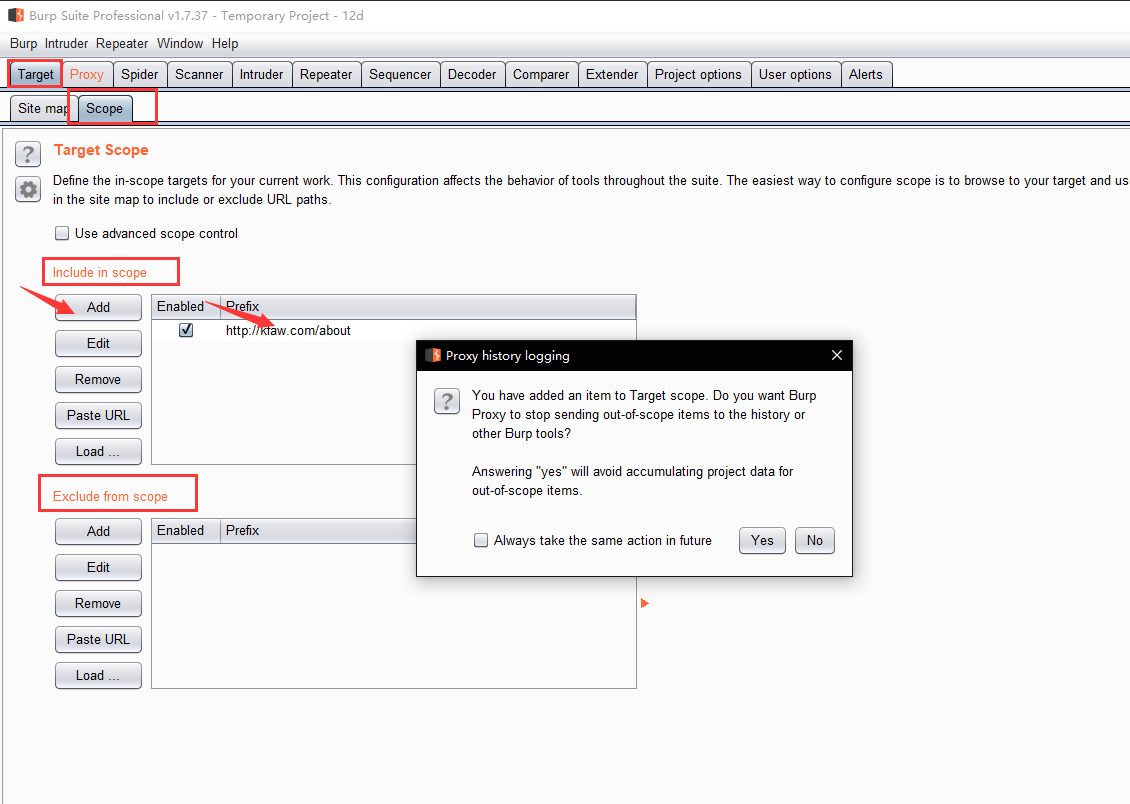
y.scope
This panel lets you define exactly what is in-scope for the Spider to request.
The best way to handle spidering scope is normally using the suite-wide target scope, and by default the Spider will use that scope. If you need to define a different scope for the Spider to use, then select "Use custom scope". A further configuration panel will appear which functions in the same way as the suite-wide target scope panel. If you have selected to use a custom scope and you send any out-of-scope items to the Spider, then Burp will automatically update this custom scope, rather than the Suite scope.
Bx_Burp Spider
z.control.Spider Status

y.control.Spider Scope

x.options.Crawls Settings
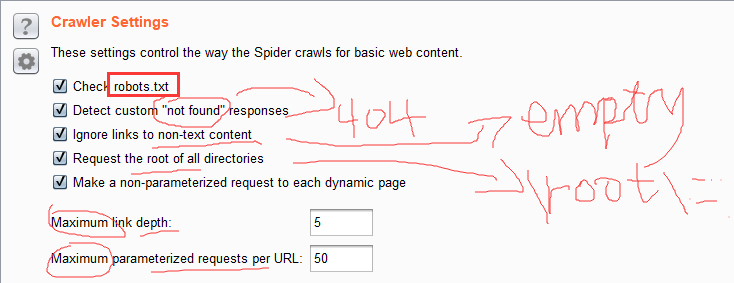
These settings control the way the Spider crawls for basic web content:
Check robots.txt - If this option is checked, the Spider will request and process the robots.txt file, to extract links to content. This file is used by the robots exclusion protocol to control the behavior of spider-like agents on the Internet. Note that the Spider does not conform to the robots exclusion protocol. Because the Spider is designed to enumerate a target application's content, all entries in robots.txt will be requested if they are in scope.
Detect custom "not found" responses - The HTTP protocol requires web servers to return a 404 status code if a requested resource does not exist. However, many web applications return customized "not found" pages that use a different status code. If this is the case, then using this option can prevent false positives in the mapping of site content. Burp Spider detects custom "not found" responses by requesting several nonexistent resources from each domain, and compiling a fingerprint with which to diagnose "not found" responses to other requests.
Ignore links to non-text content - It is often possible to deduce the MIME type of a particular resource from the HTML context in which links to it appear (for example tags). If this option is checked, the Spider will not request items which appear, from this context, to be non-text resources. Using this option can reduce spidering time with minimal risk of overlooking interesting content as a result.
Request the root of all directories - If checked, the Spider will request all identified web directories within the target scope, in addition to files within those directories. This option is particularly useful if directory indexing is available on the target site.
Make a non-parameterized request to each dynamic page - If checked, the Spider will make a non-parameterized GET request to all in-scope URLs that accept query string parameters. Dynamic pages usually respond differently if the expected parameters are not received, and this option may successfully detect additional site content and functionality.
Maximum link depth - This is the maximum number of "hops" that the Spider will navigate from any seed URL. A value of zero will cause the Spider to request seed URLs only. If a very large number is specified, then in-scope links will be followed effectively indefinitely. Setting this option to a reasonable number can help to prevent spidering loops in certain kinds of dynamically generated content.
Maximum parameterized requests per URL - This is the maximum number of requests that the Spider will make to the same base URL with different parameters. Setting this option to a reasonable number can help to avoid crawling "infinite" content, such as calendar applications with a date parameter in the URL.
w.options.Passive Spidering
Passive spidering monitors traffic through Burp Proxy to update the site map without making any new requests. This enables you to map out an application's content and functionality in a very controlled way using your browser.
The following options are used to control passive spidering:
Passively spider as you browse - If checked, Burp Spider will process all HTTP requests and responses made through Burp Proxy, to identify links and forms on pages that you visit. Using this option can enable Burp to build up a detailed picture of an application's content even when you have only browsed a subset of that content, because Burp identifies everything that is linked from the content that you do browse. Content that you have requested is shown in black on the Target site map, while unrequested content is shown in gray, enabling you to easily identify areas of the application that require further mapping.
Link depth to associate with Proxy requests - This option controls the "link depth" which will be associated with URLs accessed through Burp Proxy.

v.options.Form Submission
These settings control whether and how the Spider submits HTML forms. Simply following linked URLs will achieve limited coverage of most applications. To discover all of an application's content and functionality, it is generally necessary to submit forms using realistic inputs.
The following options are available:
Individuate forms - This option configures the criteria for individuating unique forms (action URL, method, fields, values). When the Spider processes each form, it will check these criteria to determine if the form is "new". Forms that are new will be queued for submission, according to the other form submission options. Careful use of this option can help the Spider to deal with applications that make use of different forms-based navigational structures.
Don't submit forms - If selected, the Spider will not submit any forms.
Prompt for guidance - If selected, the Spider will prompt you for guidance before submitting each form. The interactive prompt allows you to enter custom data into form input fields as required, select which submit fields to send to the server, and choose whether to iterate through all available submit fields.
Automatically submit - If selected, the Spider will automatically submit any in-scope forms using the defined rules to assign the values of text input fields. Each rule lets you specify a simple or regular expression to match on form field names, and the value to submit in fields whose names match the expression. A default value can be specified for any unmatched fields. This option is particularly useful if you want to automatically spider through registration forms and similar functions, where applications typically require data in a valid format for each input field. Burp comes with a set of default rules that have proven successful when automatically submitting form data to a wide range of applications. You can modify these or add your own rules if you encounter form field names that you want to submit specific values in. You should use this option with caution, as submitting bogus values in forms may sometimes result in undesirable actions. Many forms contain multiple SUBMIT elements, which result in different actions within the application, and the discovery of different content. You can configure the Spider to iterate through the values of all submit elements within forms, submitting each form multiple times up to a configurable maximum.

u.options.Application Login
These settings control how the Spider submits login forms.
Because of the function that authentication plays in web applications, you will often want Burp to handle login forms in a different way than ordinary forms. Using this configuration, you can tell the Spider to perform one of four different actions when a login form is encountered:
Burp can ignore the login form, if you don't have credentials or are concerned about spidering sensitive protected functionality.
Burp can prompt you for guidance interactively, enabling you to specify credentials on a case-by-case basis. This is the default option.
Burp can handle login forms in the same way as any other form, using the configuration and auto-fill rules you have configured for those.
Burp can automatically submit specific credentials in every login form that is encountered. When Burp tries to do this, it will submit your configured password in the password field, and will submit your configured username in the text input field whose name most looks like a username field.
Note that you can also use the suite-wide session handling rules to deal with authentication while performing automated spidering. If you use session handling rules to maintain a valid session with the application, then you should configure the Spider not to submit login forms, to avoid disrupting your session.

t.options.Spider Engine
These settings control the engine used for making HTTP requests when spidering. The following options are available:
Number of threads - This option controls the number of concurrent requests the Spider is able to make.
Number of retries on network failure - If a connection error or other network problem occurs, Burp will retry the request the specified number of times before giving up and moving on. Intermittent network failures are common when testing, so it is best to retry the request several times when a failure occurs.
Pause before retry - When retrying a failed request, Burp will wait the specified time (in milliseconds) following the failure before retrying. If the server is being overwhelmed with traffic, or an intermittent problem is occurring, it is best to wait a short time before retrying.
Throttle between requests - Optionally, Burp can wait a specified delay (in milliseconds) before every request. This option is useful to avoid overloading the application, or to be more stealthy.
Add random variations to throttle - This option can further increase stealth by reducing patterns in the timing of your requests.
Careful use of these options lets you fine tune the spidering engine, depending on the performance impact on the application, and on your own processing power and bandwidth. If you find that the Spider is running slowly, but the application is performing well and your own CPU utilization is low, you can increase the number of threads to make your spidering proceed faster. If you find that connection errors are occurring, that the application is slowing down, or that your own computer is locking up, you should reduce the thread count, and maybe increase the number of retries on network failure and the pause between retries.

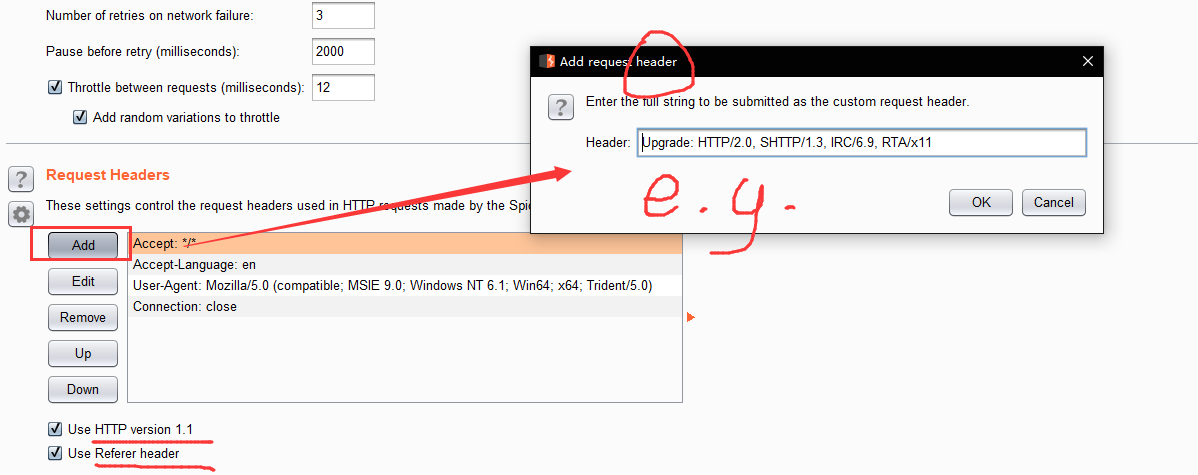
s.options.Request Headers
These settings control the request headers used in HTTP requests made by the Spider.
You can configure a custom list of headers to be used in Spider requests. This may be useful to meet specific requirements of individual applications - for example, to emulate an expected user agent when testing applications designed for mobile devices.
The following options are also available:
Use HTTP version 1.1 - If checked, the Spider will use version 1.1 of HTTP in its requests; otherwise, it will use version 1.0.
Use Referer header - If checked, the Spider will submit the relevant Referer header when requesting any item that was linked to from another page. This option is useful to more closely simulate the requests that would be made by your browser, and may also be necessary to navigate through some applications that validate the Referer header.
Cx_How to use Burp /Scanner/ and /Intruder/ ?
be continued..