1. galloping search
搜索的时候在找到目标之前成倍数的加快搜索进度,如指针所指的第一个不是目标,就往后跳一位,依然不是跳两位,然后四位,依此类推,直到比目标数更大时停止,使用binary search在现在所指的数与前一位数之间寻找目标值
目标值所在的位置称为n,所需跳的步数为log2n,二分法查找复杂度也为log2n,所以总时间复杂度为log2n
但是上面的操作针对的是只有一行数据的时候,若存在两条数据,根据下面的公式对复杂度继续进行化简
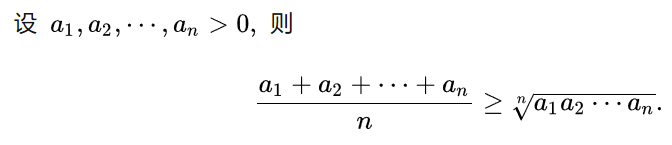
复杂度化简后得到2|K1|*log2(|K2|/|K1|), 可以得到当K1与K2相近时,搜索的复杂度接近于线性搜索
2. Multiple term conjunctive queries
多个query做and操作,若某一个数据行的第一个数很大,其他的数据行上的指针就以log2n的复杂度向后skip,速度很慢。可以的解决方式是以最短的数据行作为基准。针对最短数据第一个值x对应查找下一列可不可以skip到相同的数y,若是skip到了比x大的停下来,看x后面的数是不是与y相同,相同则输出,若依然小于y则第一行数据skip到y。若是比y大了则正常往后走,称为max algorithm
3. pre-progress
a) 获取文件后首先转为一段段统一形式的文件,document unit。若文件过大,如将一本书划分为一个unit,可以得到我们想要的信息但是不需要的信息过多;若是划分的很细则增加了查找困难,如划分成每句话为一个unit,所以划分要小心
b) tokenization即去掉标点符号等无用的信息,提取逐个单词,删除的时候以及什么时候两个单词被划分为一个整体这些问题都要进行考虑
c) 将数字作为meta data
stop words为停顿词,即the a and to be等
d) normalization
意思相同的词统一成一个形式,包括将大写全改为小写
方法可以手动去定义,且可以根据发音自动纠错
lemmatization指am are is转化为be等
stemming可以将词性进行统一
#document与query所进行的操作必须一样
e) 将用到的语言进行标注
4.